
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1008 followers · 429 posts · Server sigmoid.social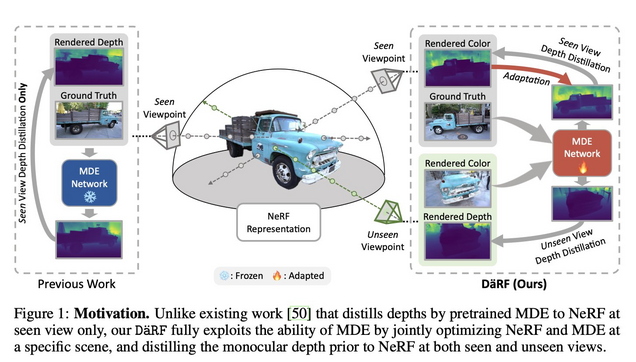
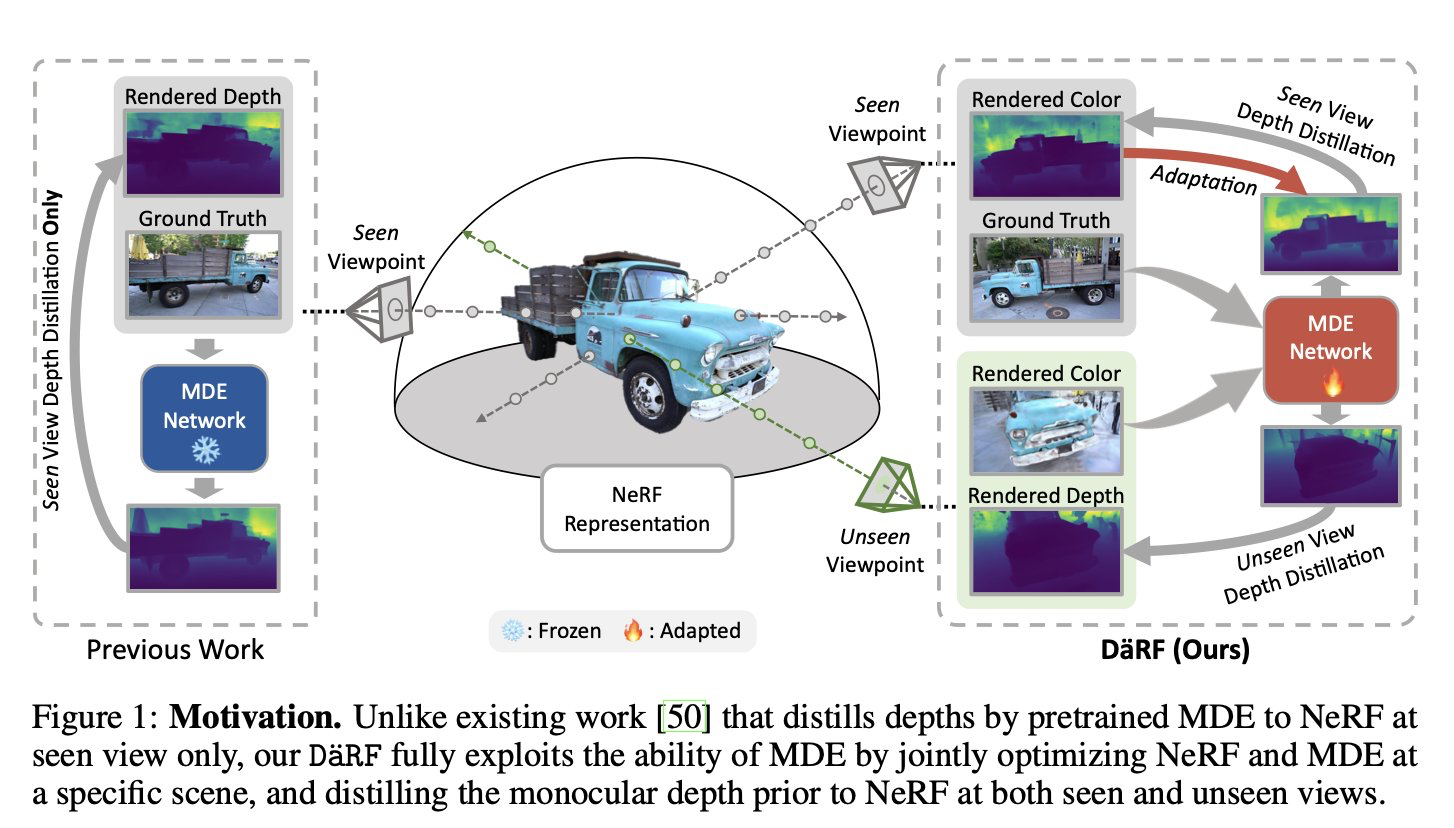
DäRF: Boosting Radiance Fields from Sparse Inputs with Monocular Depth Adaptation
Jiuhn Song, Seonghoon Park, Honggyu An, Seokju Cho, Min-Seop Kwak, Sungjin Cho, Seungryong Kim
tl;dr: feed NERF-rendered novel view into monodepth, and optimize consistency
https://arxiv.org/abs/2305.19201.pdf
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1005 followers · 427 posts · Server sigmoid.social
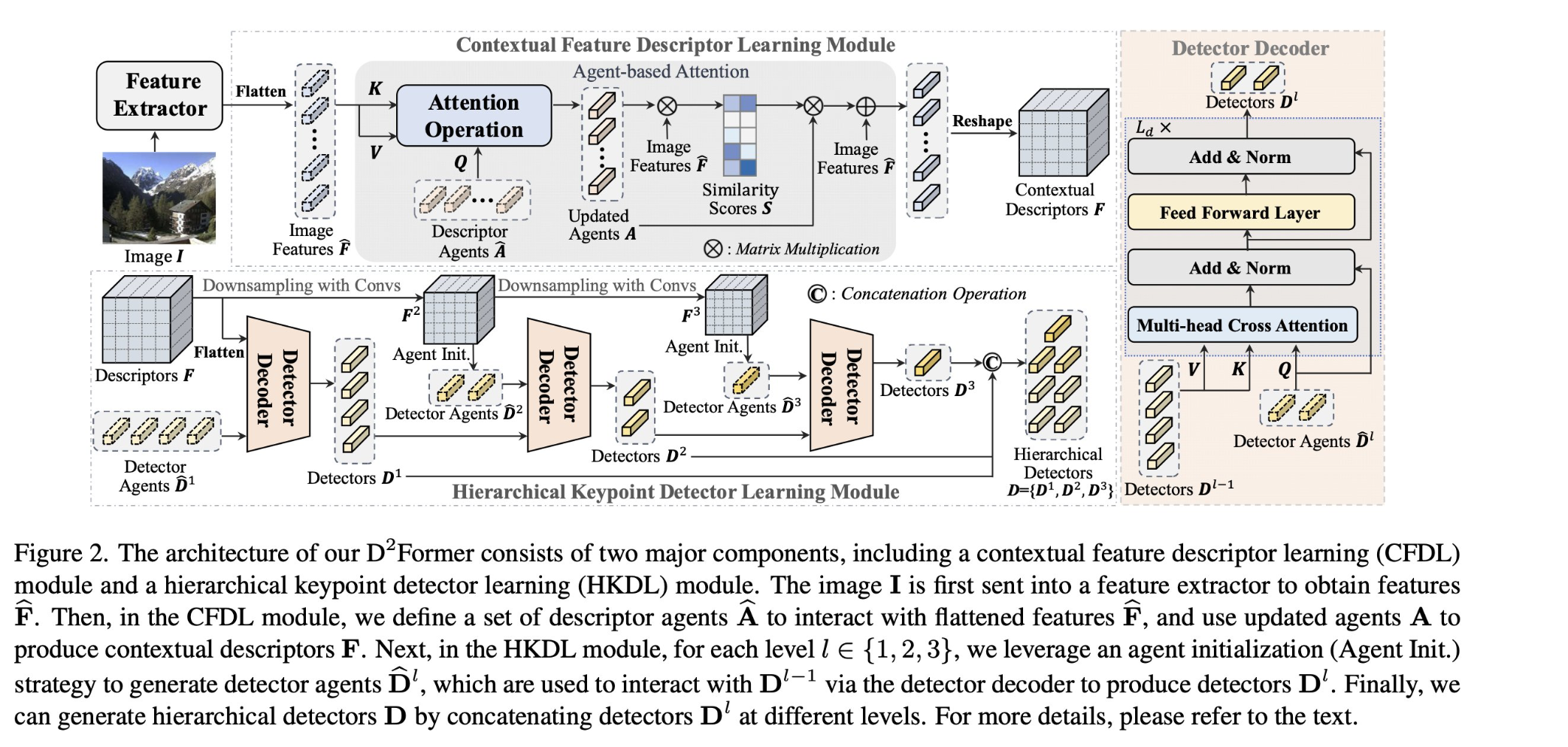
D2Former: Jointly Learning Hierarchical Detectors and Contextual Descriptors via Agent-Based Transformers
Jianfeng He, Yuan Gao, Tianzhu Zhang, Zhe Zhang, Feng Wu
tl;dr: no idea how that works, hierarchical attention something. No eval on #IMC
https://openaccess.thecvf.com/content/CVPR2023/papers/He_D2Former_Jointly_Learning_Hierarchical_Detectors_and_Contextual_Descriptors_via_Agent-Based_CVPR_2023_paper.pdf
#CVPR2023
#computervision #deeplearning
#dmytrotweetsaboutDL
#imc #CVPR2023 #computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1005 followers · 426 posts · Server sigmoid.social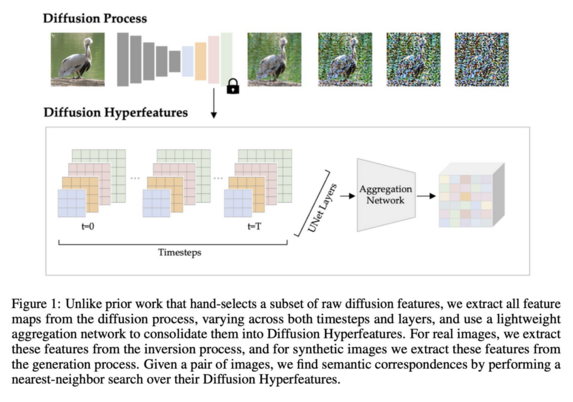
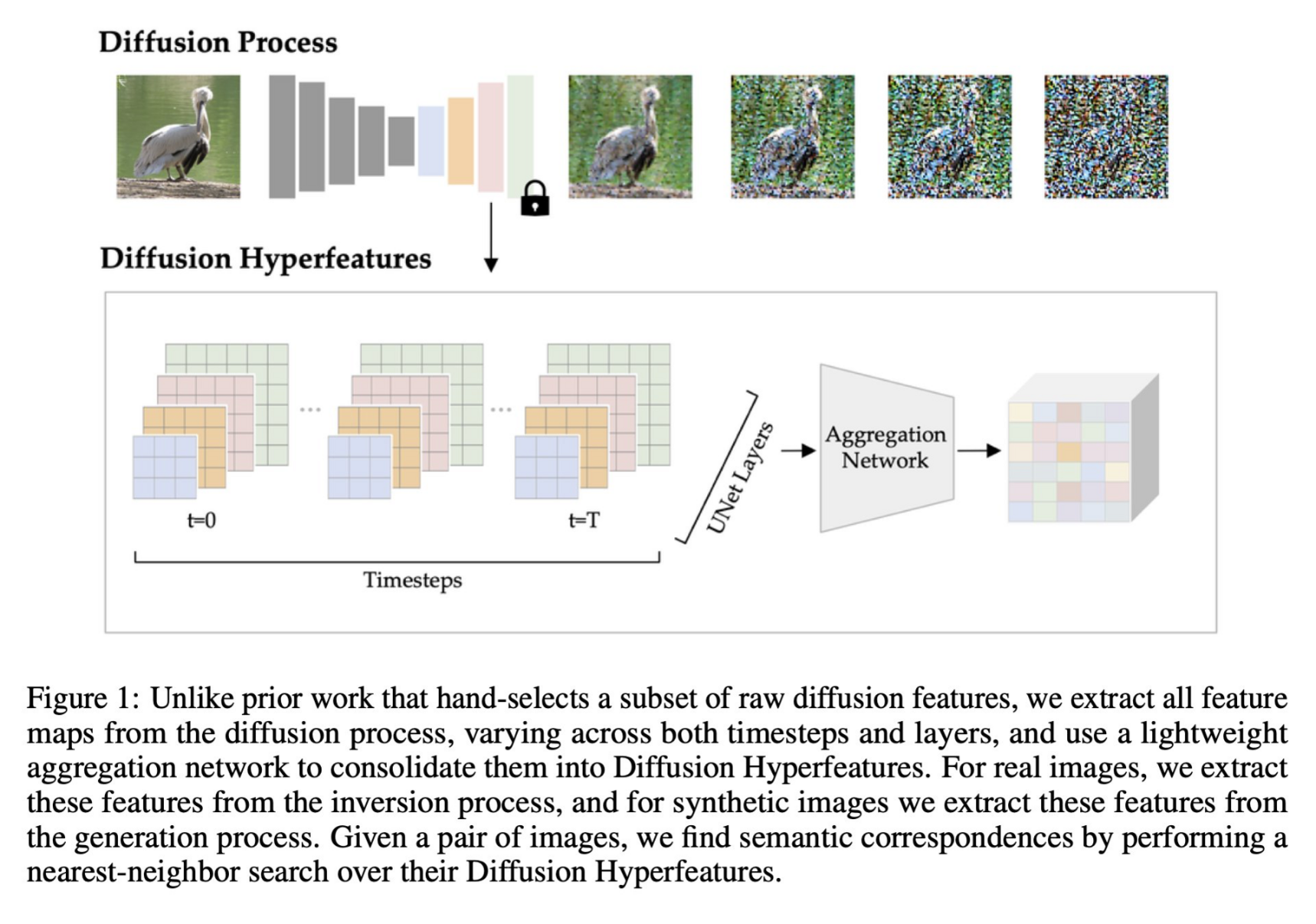
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holynski Trevor Darrell
tl;dr: diffusion features are good descriptors for semantic corrs, if aggregated among timesteps.
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1005 followers · 425 posts · Server sigmoid.social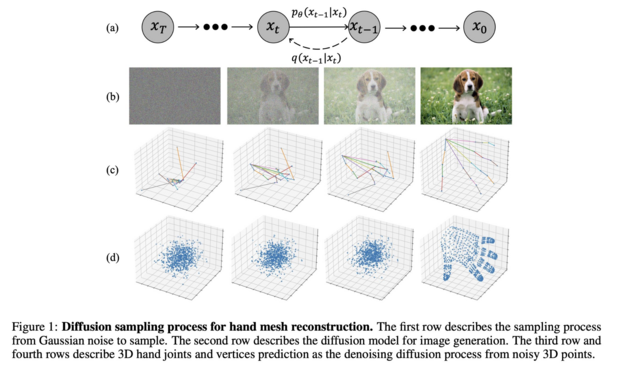
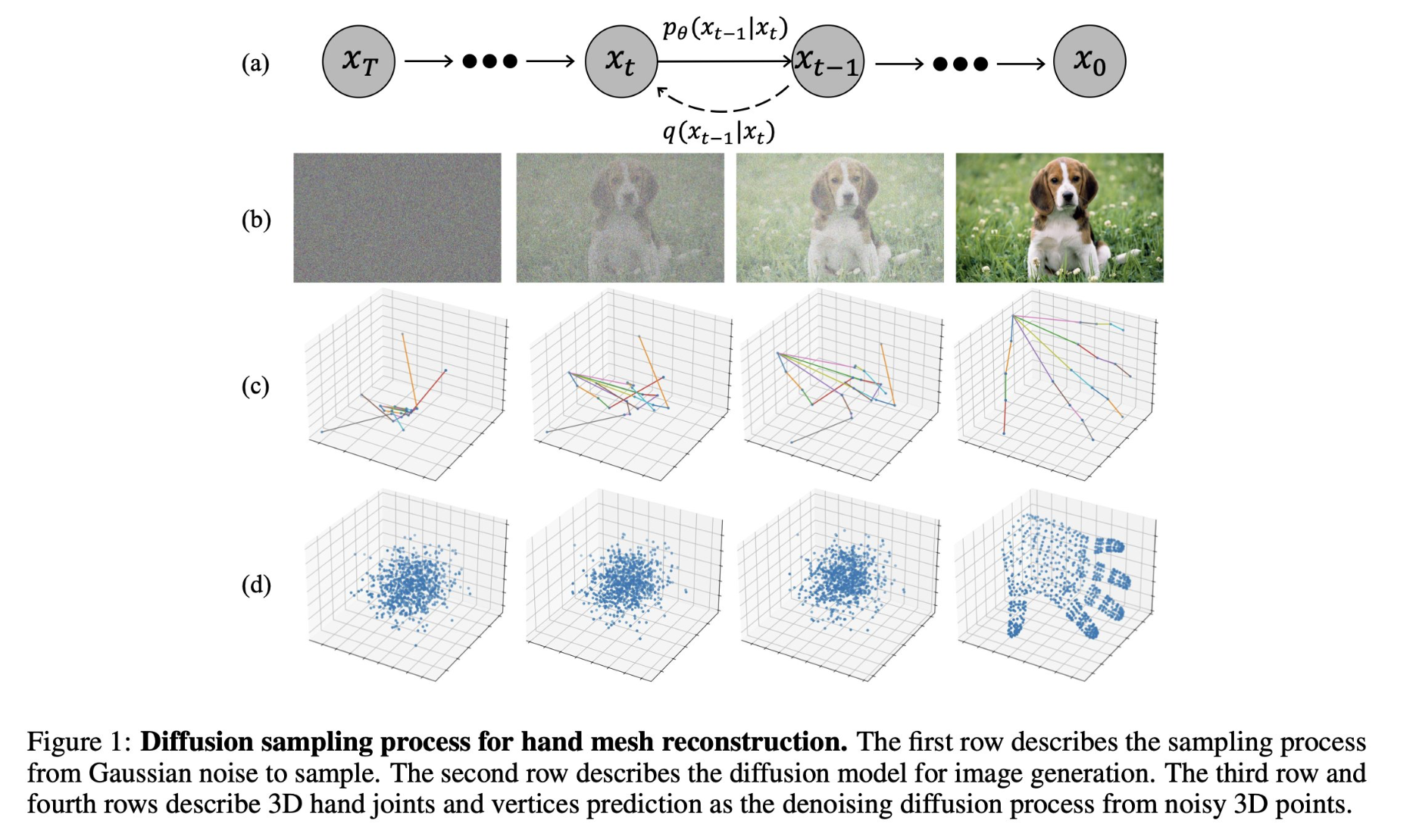
DiffHand: End-to-End Hand Mesh Reconstruction via Diffusion Models
Lijun Li, Li'an Zhuo, Bang Zhang, Liefeng Bo, Chen Chen
tl;dr: diffusion models can do mesh reconstruction.
https://arxiv.org/abs/2305.13705
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1005 followers · 423 posts · Server sigmoid.social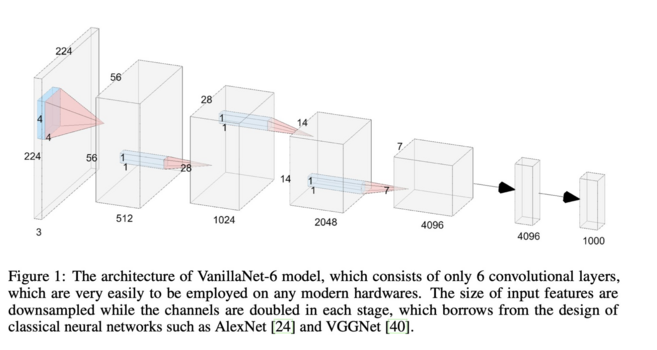
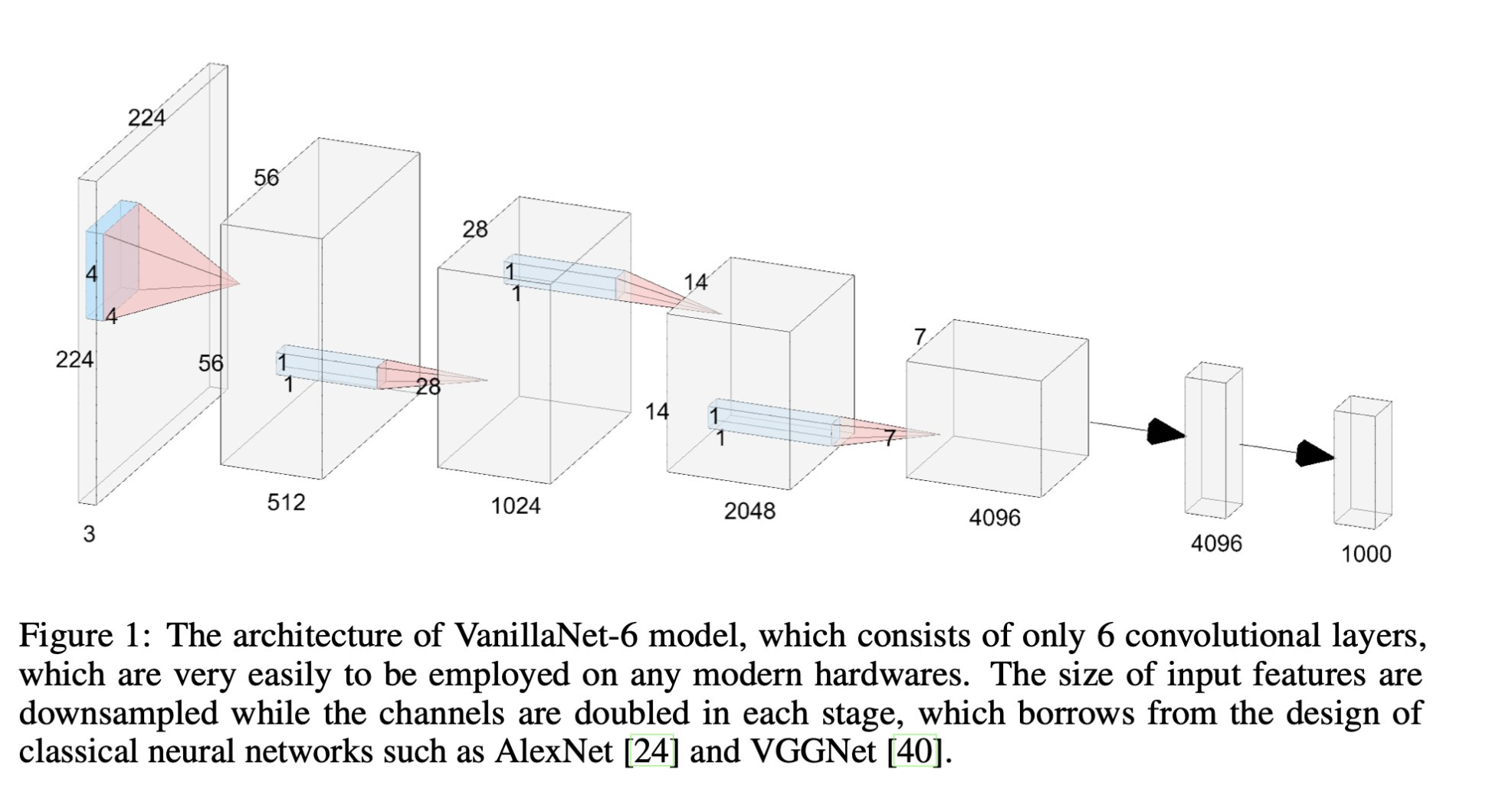
VanillaNet: the Power of Minimalism in Deep Learning
Hanting Chen, Yunhe Wang, Jianyuan Guo, Dacheng Tao
tl;dr: 4x4conv/4->n x {1x1conv->{seriesAct}->MaxPool2x2}.
seriesAct = stack of BN(ReLU(BN(ReLU)))
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1004 followers · 422 posts · Server sigmoid.social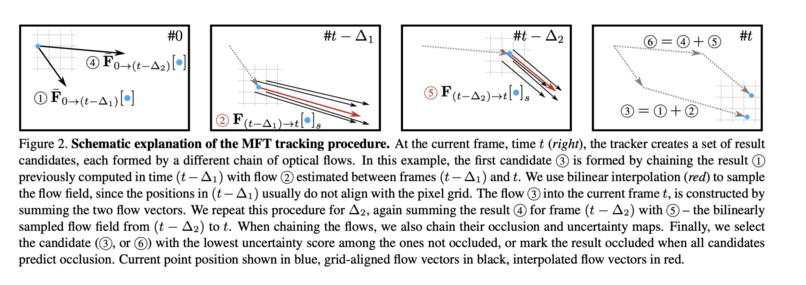
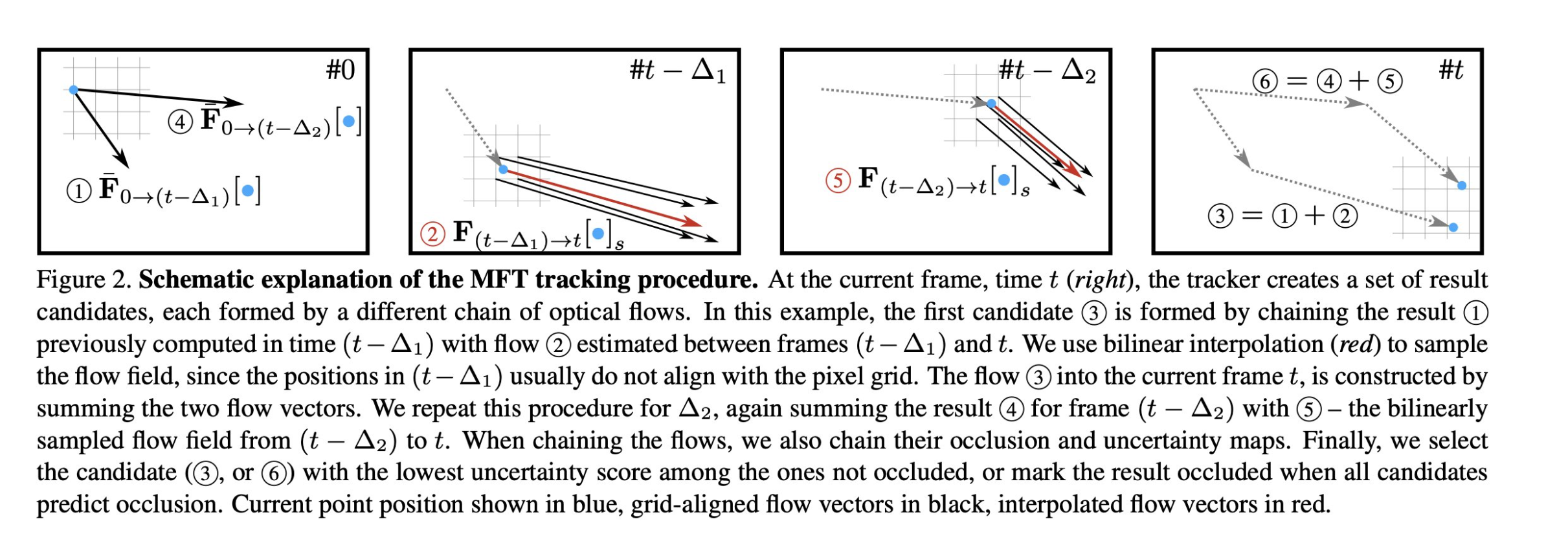
MFT: Long-Term Tracking of Every Pixel
Michal Neoral, Jonáš Šerých, Jiří Matas
tl;dr: RAFT for frame-sequence + log-frame-sequence. Also propagate uncertainty and occlusion. generate several hypothesis, select least uncertain.
https://arxiv.org/abs/2305.12998
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1004 followers · 421 posts · Server sigmoid.social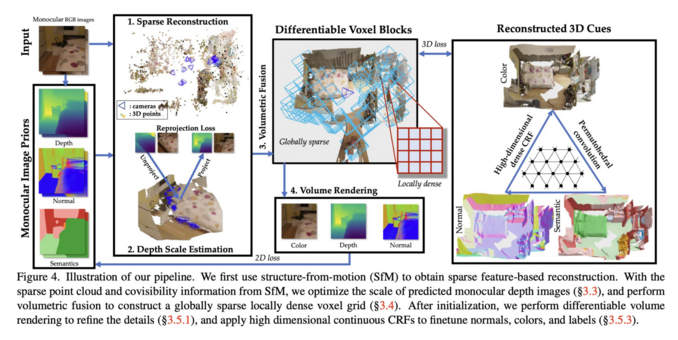
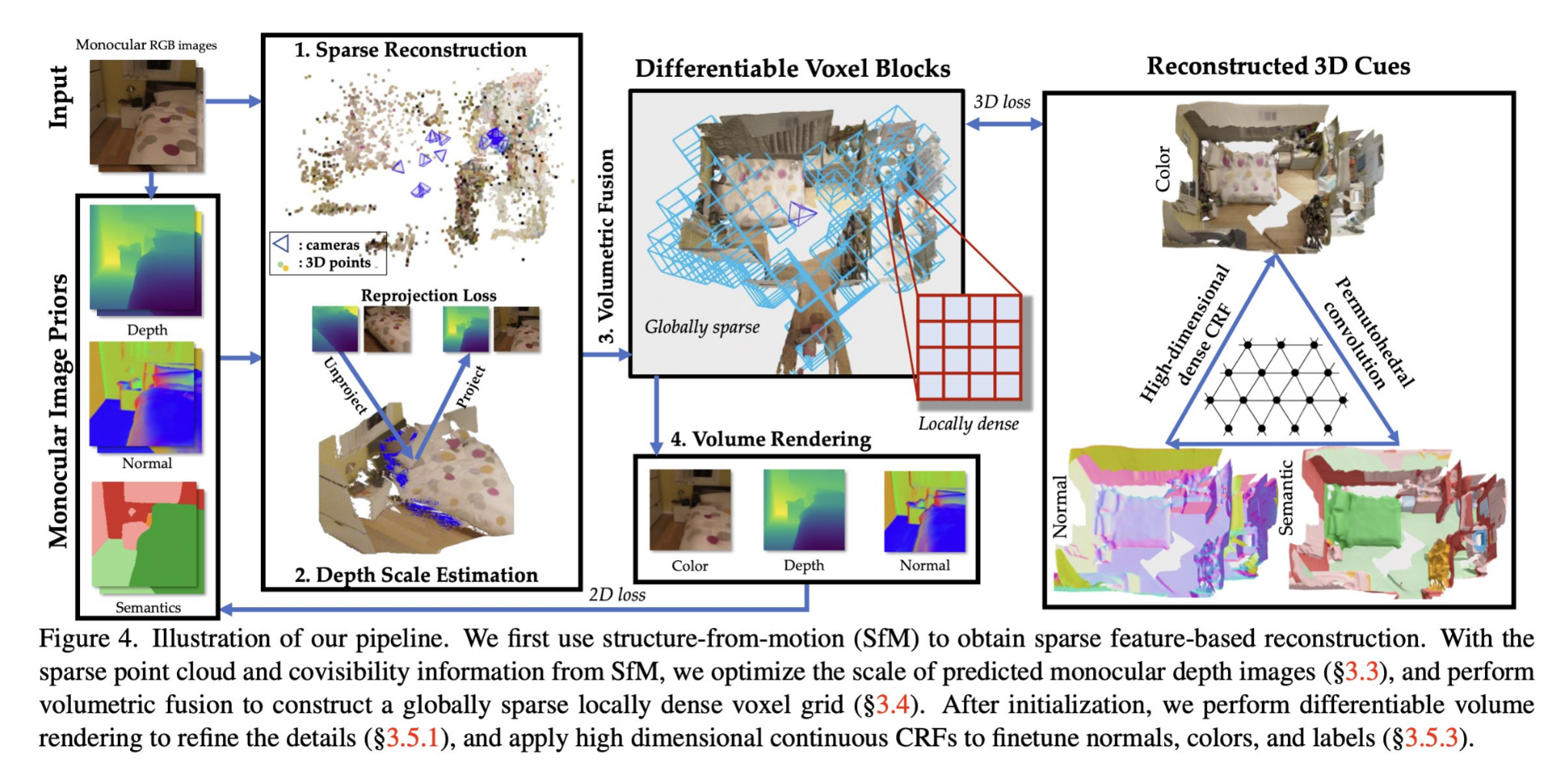
Fast Monocular Scene Reconstruction with Global-Sparse Local-Dense Grids
Wei Dong, Chris Choy, Charles Loop, Or Litany, Yuke Zhu, Anima Anandkumar
tl;dr: monodepth + SfM to init non-zero voxel grid, then densify and refine -> ScanNet scene <30 min
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1004 followers · 420 posts · Server sigmoid.social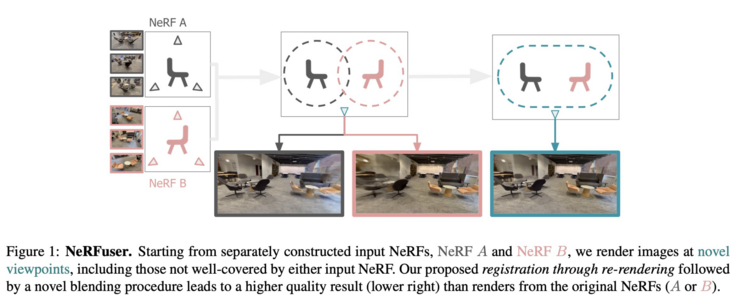
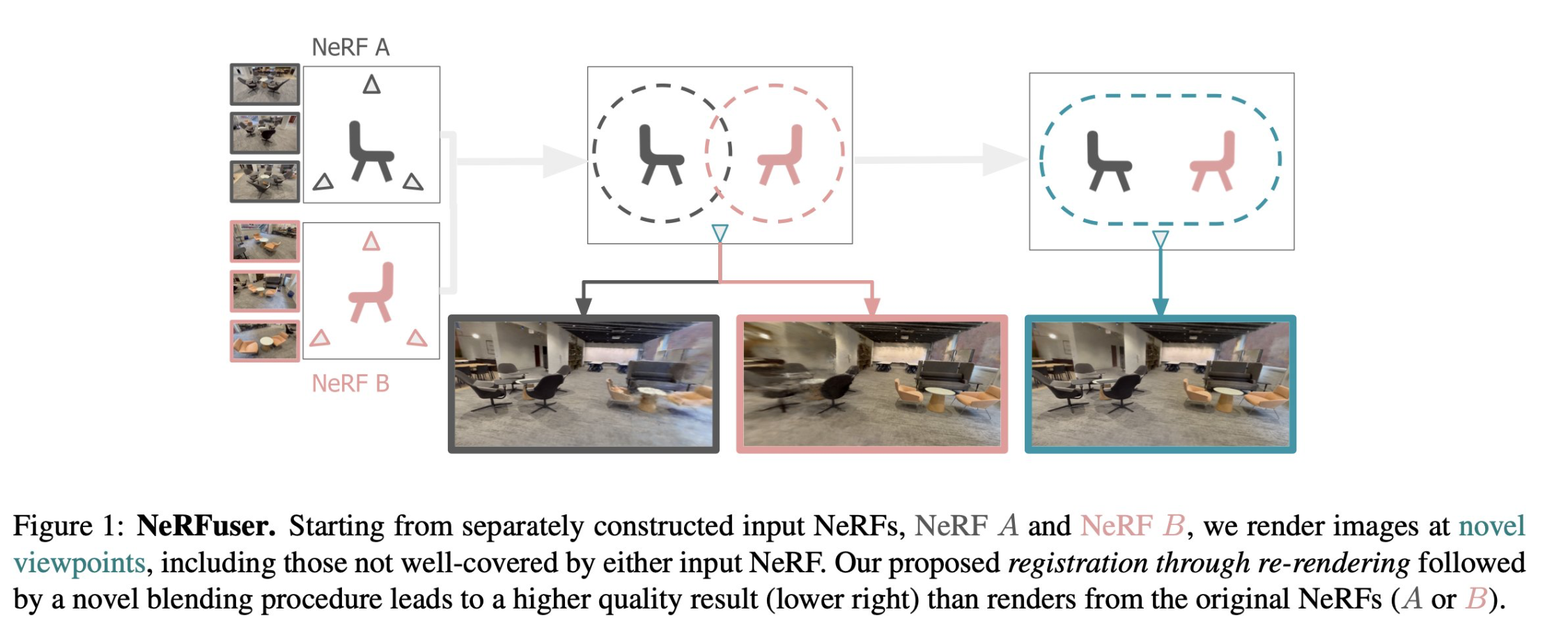
NeRFuser: Large-Scale Scene Representation by NeRF Fusion
Jiading Fang, Shengjie Lin, Igor Vasiljevic, Vitor Guizilini, Rares Ambrus, Adrien Gaidon, Gregory Shakhnarovich, Matthew R. Walter
tl;dr: render->SuperGlue registration->weighted blend
https://arxiv.org/abs/2305.13307.pdf
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1004 followers · 419 posts · Server sigmoid.social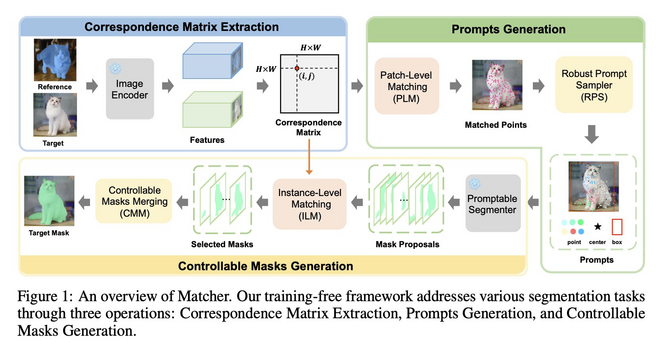
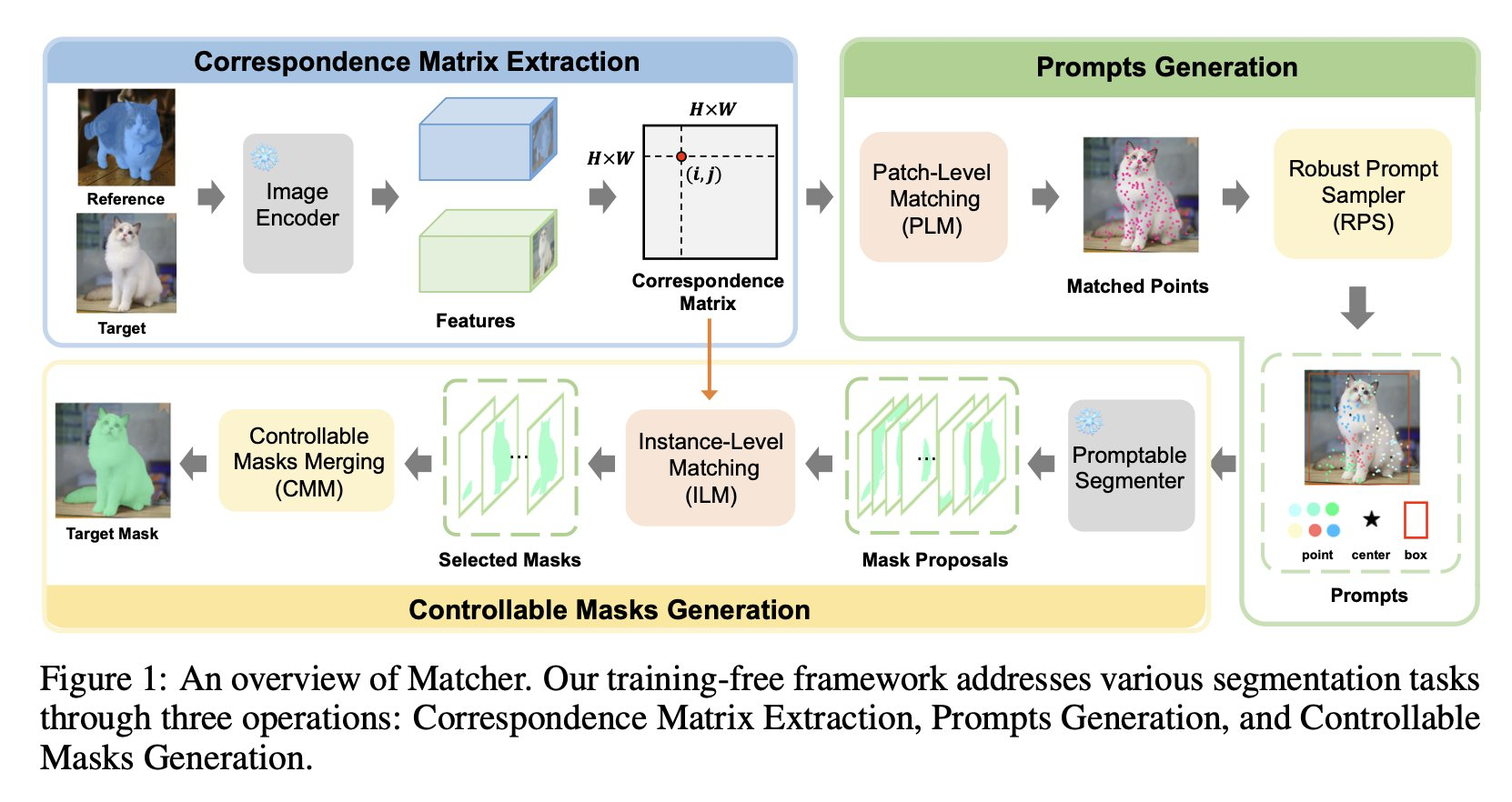
Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
v
Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, Chunhua Shen
tl;dr: segmented reference image of the same class -> use semantic correspondences to segment target image.
https://arxiv.org/abs/2305.13310.pdf
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1004 followers · 418 posts · Server sigmoid.social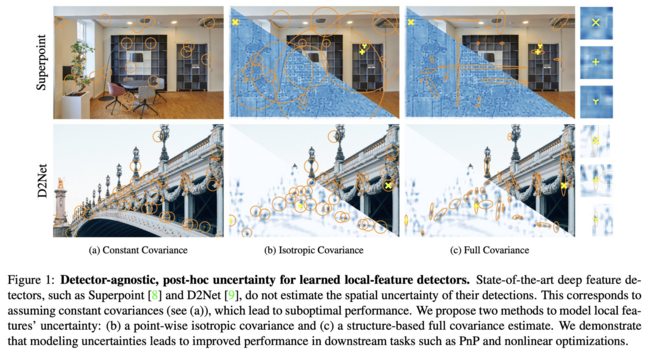
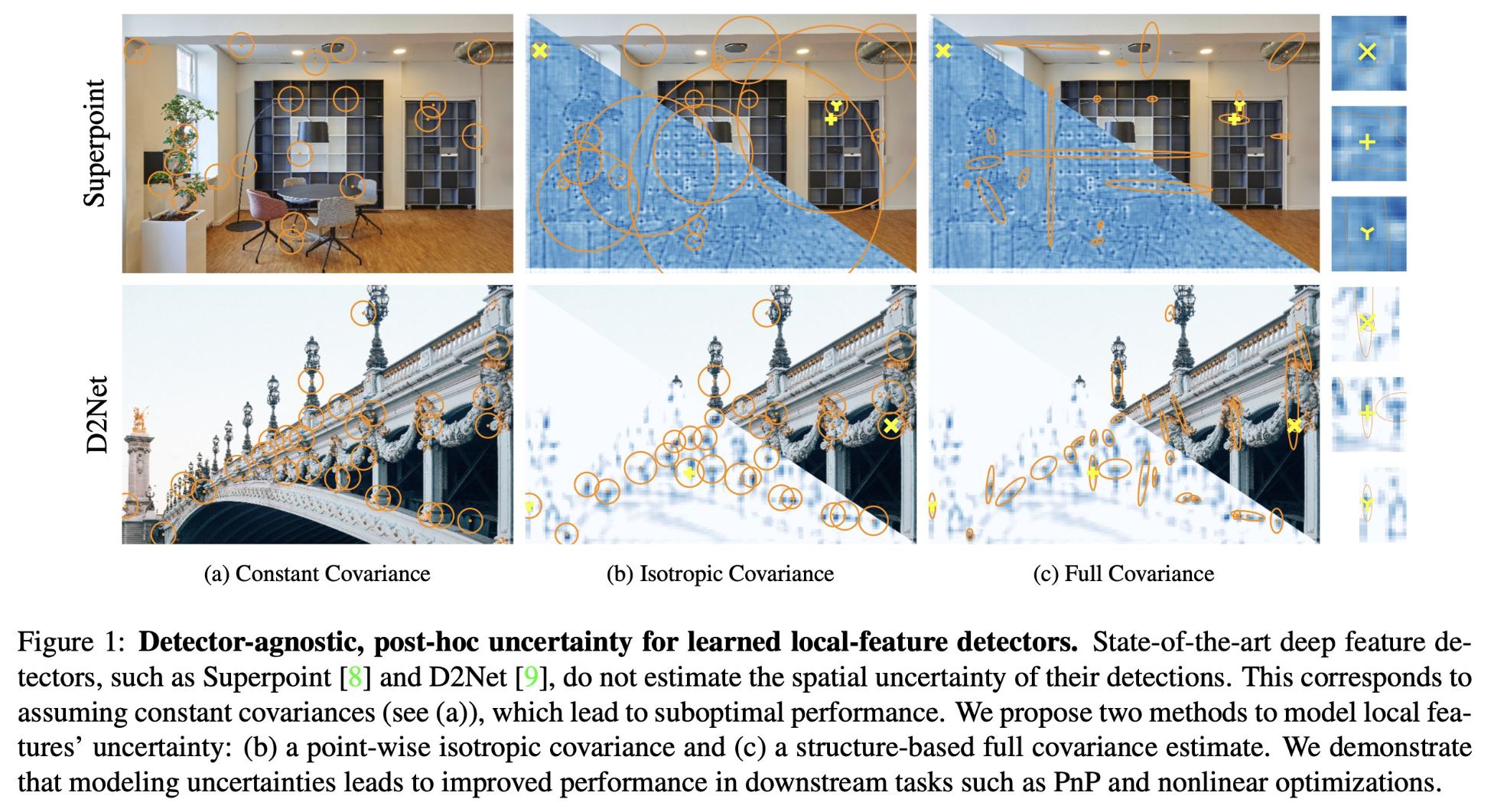
DAC: Detector-Agnostic Spatial Covariances for Deep Local Features
Javier Tirado-Garín, Frederik Warburg, Javier Civera
tl;dr: uncertainty in keypoint position from second moment matrix on scores instead of image (Baumberg-Affine).
https://arxiv.org/abs/2305.12250
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1003 followers · 416 posts · Server sigmoid.social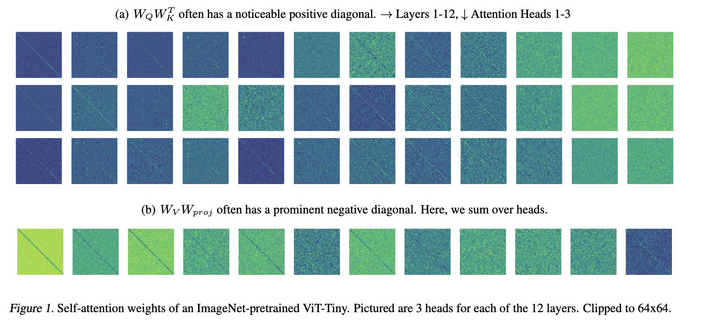
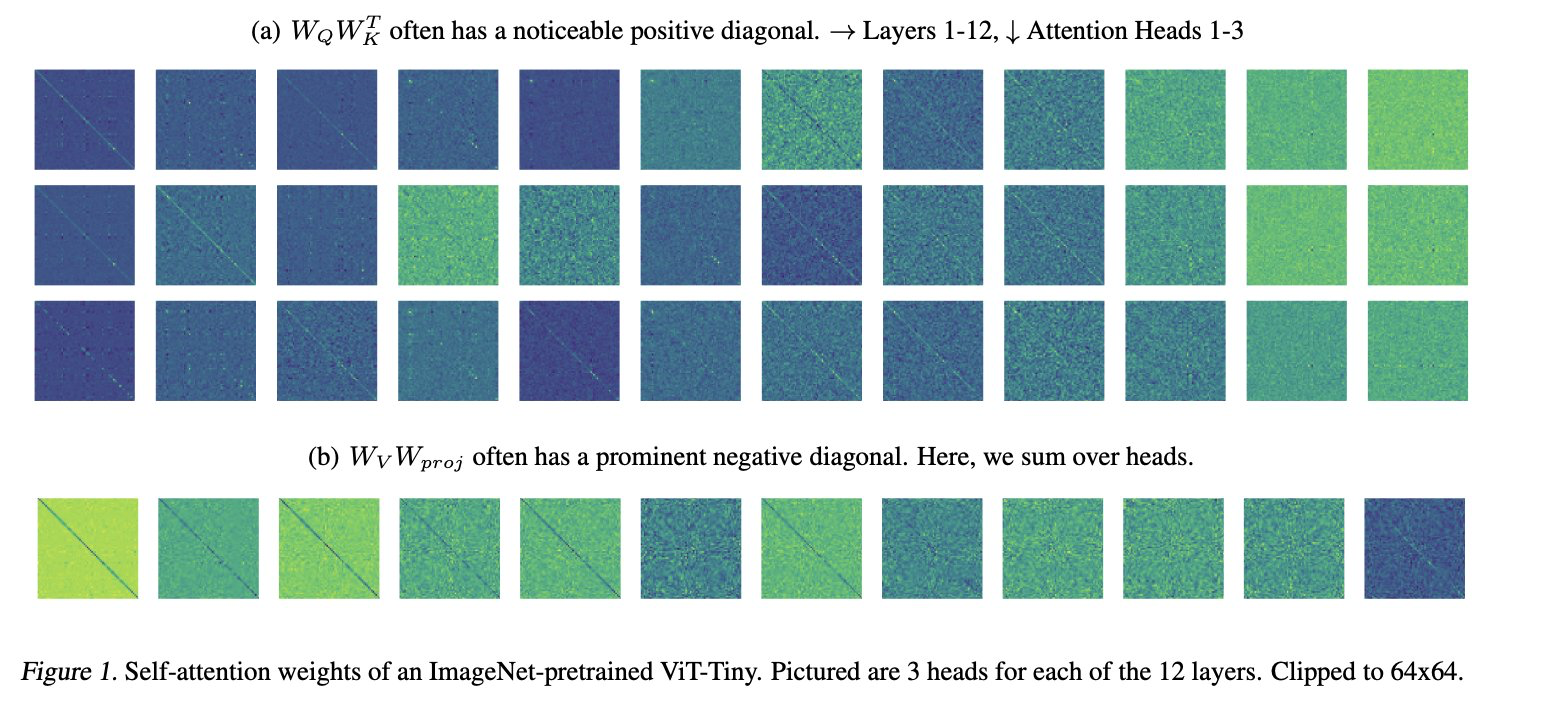
Mimetic Initialization of Self-Attention Layers
Asher Trockman, J. Zico Kolter
tl;dr: Initialize ViT, so the attention maps has diagonal structure, similar to what was observed in trained one
https://arxiv.org/abs/2305.09828
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
1001 followers · 406 posts · Server sigmoid.social
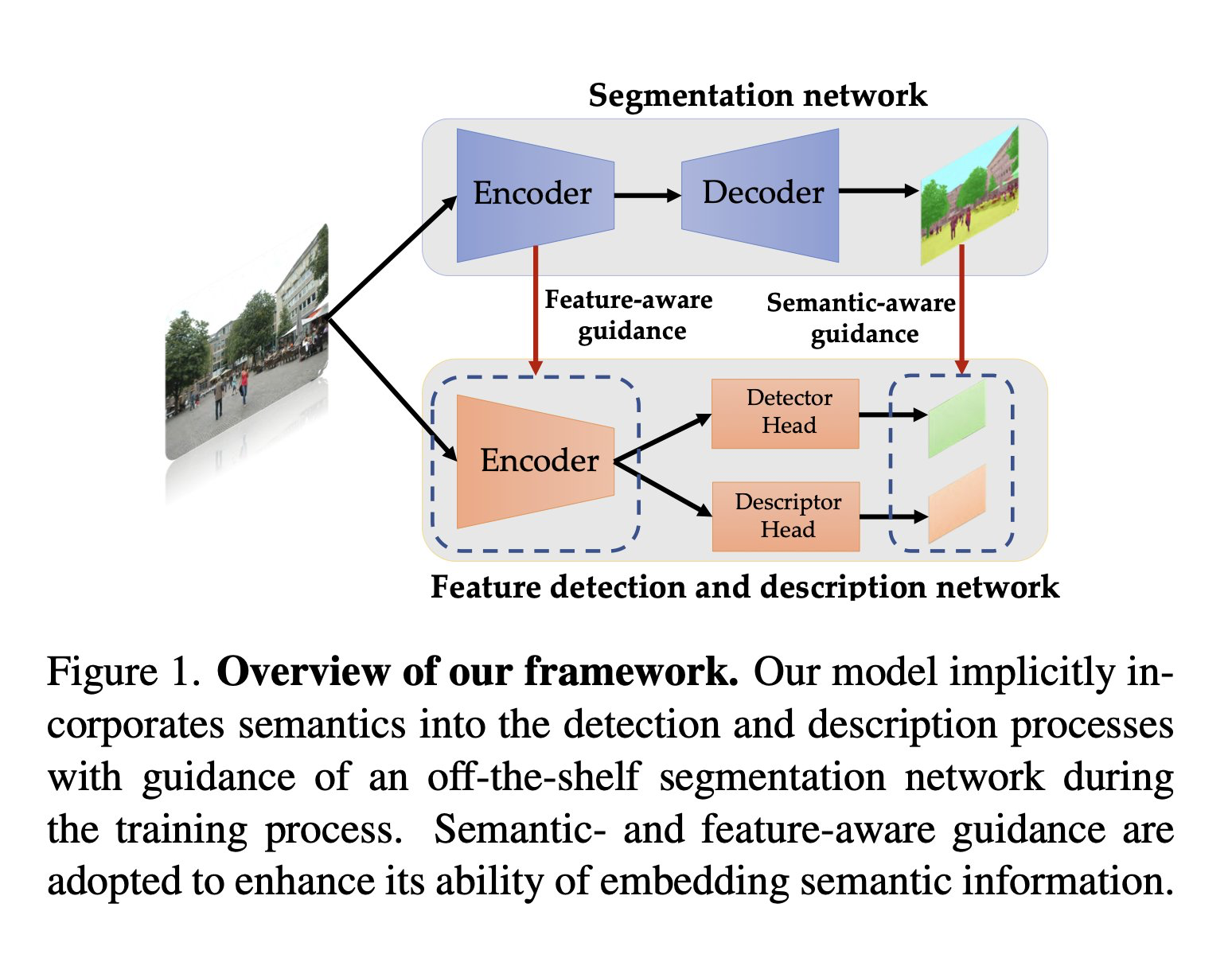
SFD2: Semantic-guided Feature Detection and Description
Fei Xue, Ignas Budvytis, Roberto Cipolla
tl;dr: more principled approach to use segmentation for image matching, than class-name filtering.
#computervision #deeplearning #dmytrotweetsaboutdl #CVPR2023
Dmytro Mishkin 🇺🇦 · @ducha_aiki
998 followers · 404 posts · Server sigmoid.social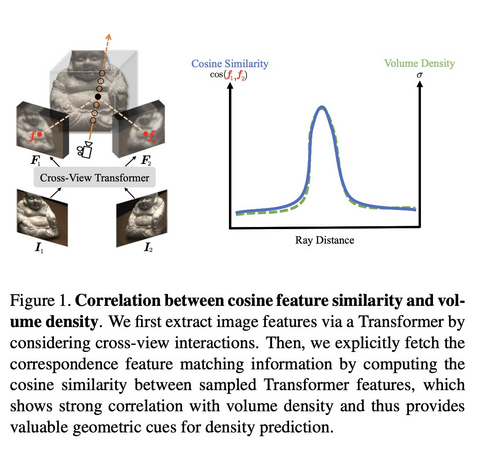
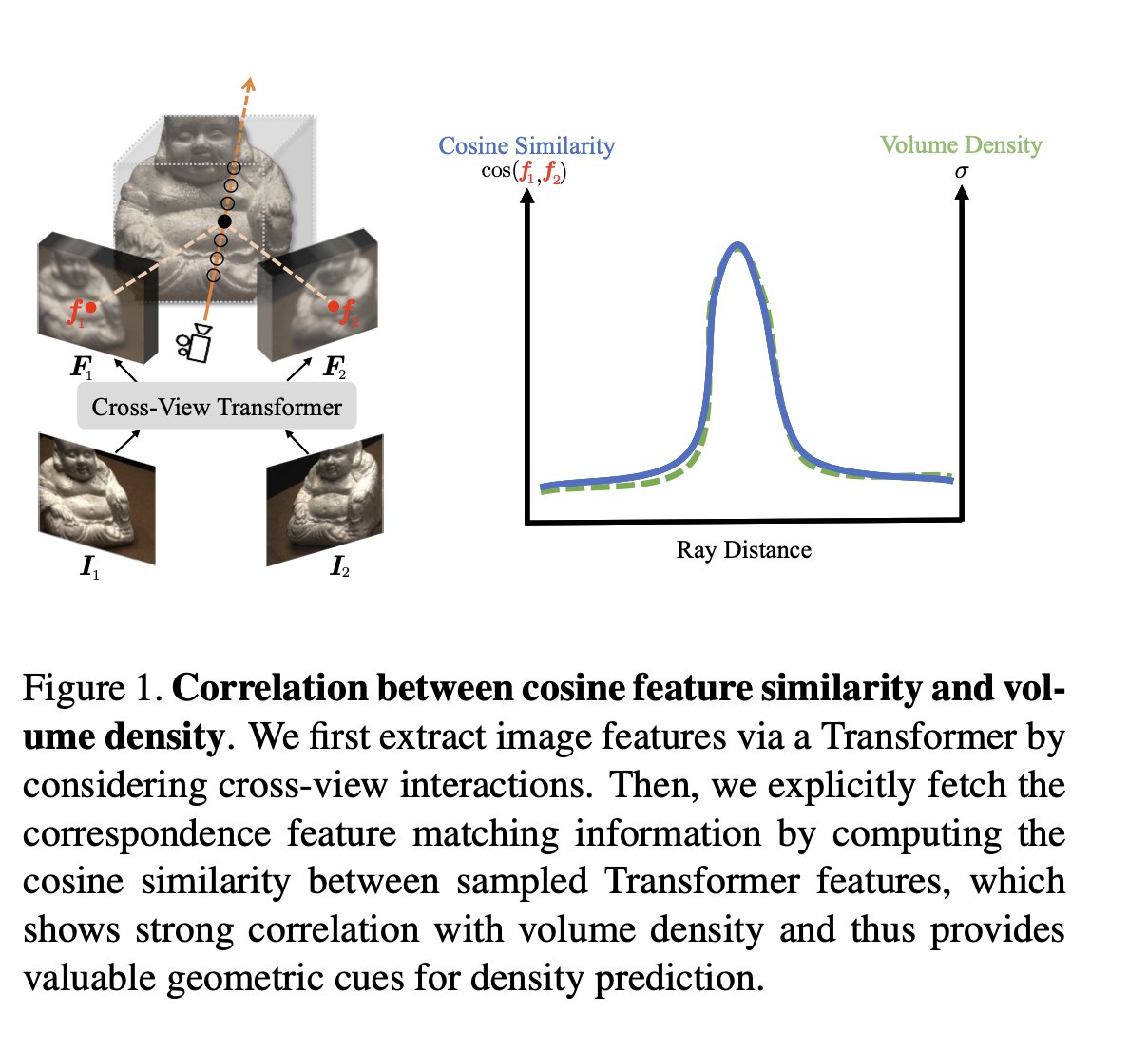
Explicit Correspondence Matching for Generalizable Neural Radiance Fields
Yuedong Chen, Haofei Xu, Qianyi Wu, Chuanxia Zheng, Tat-Jen Cham, Jianfei Cai
tl;dr: correspondence helps density modeling, but frozen GMFlow is not enough - you have to finetune.
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
998 followers · 403 posts · Server sigmoid.social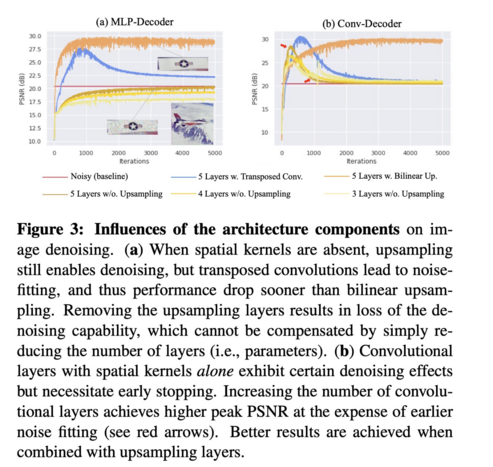
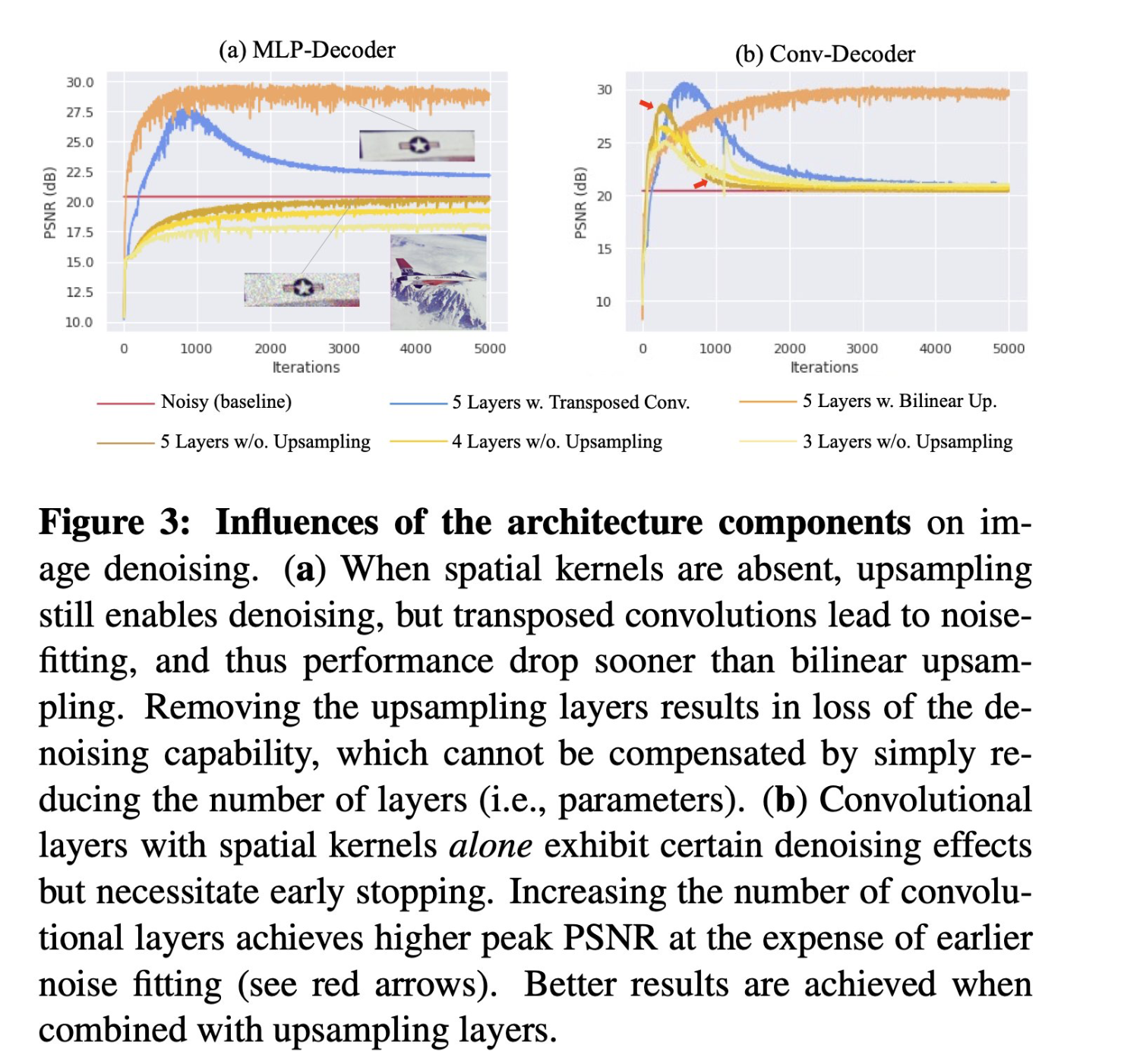
The Devil is in the Upsampling: Architectural Decisions Made Simpler for Denoising with Deep Image Prior
Yilin Liu, Jiang Li, Yunkui Pang, Dong Nie, Pew-Thian Yap
tl;dr: it title. Bilinear upsampling FTW, transposed convolution fits noise.
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
998 followers · 402 posts · Server sigmoid.social
No Free Lunch in Self Supervised Representation Learning
Ihab Bendidi, Adrien Bardes, Ethan Cohen, Alexis Lamiable, Guillaume Bollot, Auguste Genovesio
tl;dr: augmentations define SSL embedding property
https://arxiv.org/abs/2304.11718.pdf
P.S. I call SSL "augmentation-supervised" for years
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
998 followers · 401 posts · Server sigmoid.social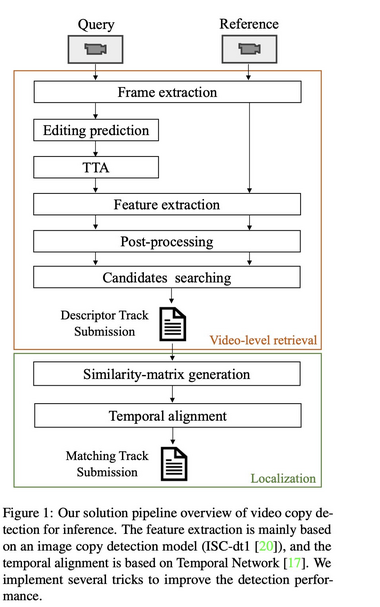
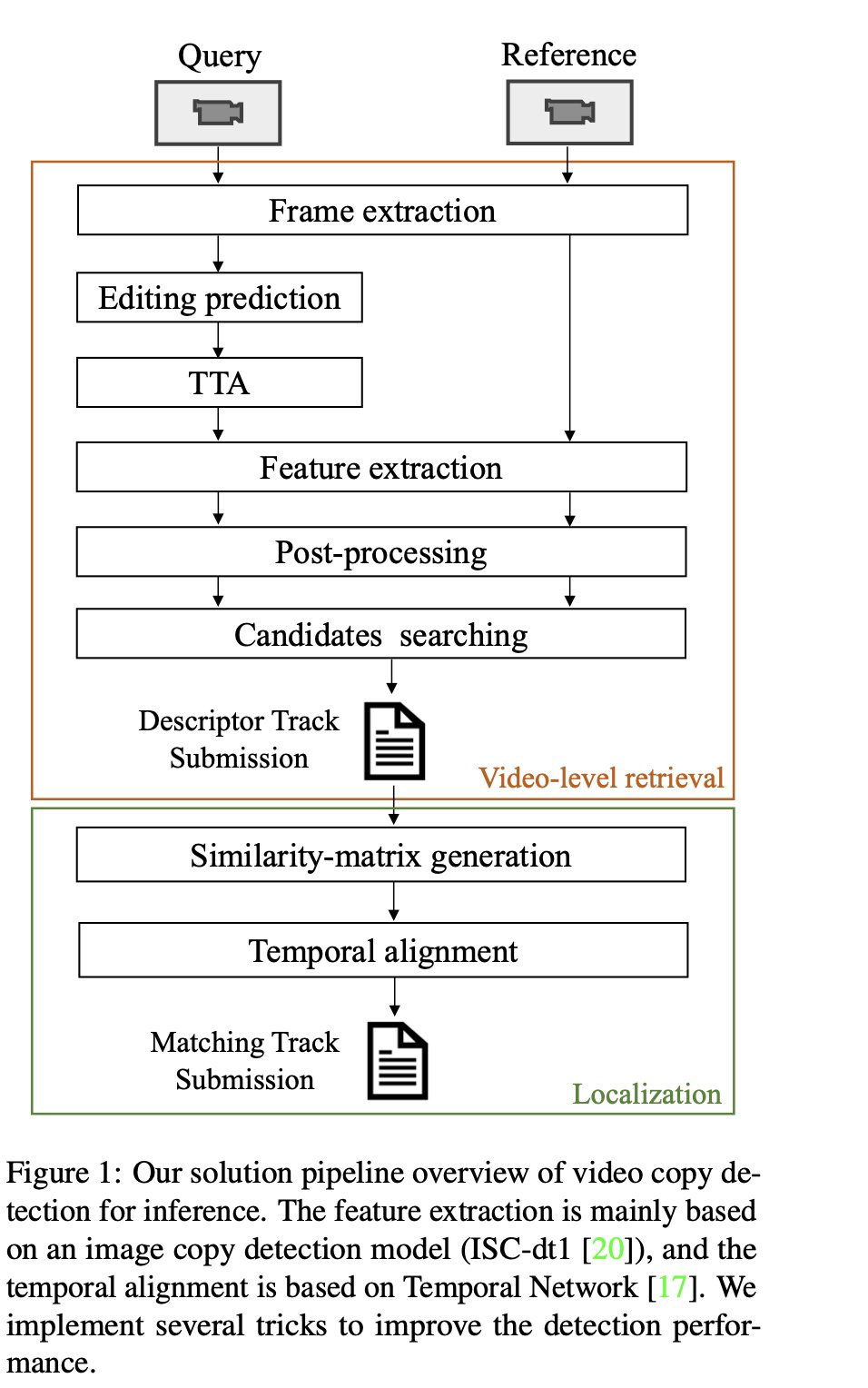
3rd Place Solution to Meta AI Video Similarity Challenge
Shuhei Yokoo, Peifei Zhu, Junki Ishikawa, Rintaro Hasegawa
tl;dr: individual frame editing prediction (SSL) + Temporal Network + video meta-data filtering
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
993 followers · 398 posts · Server sigmoid.social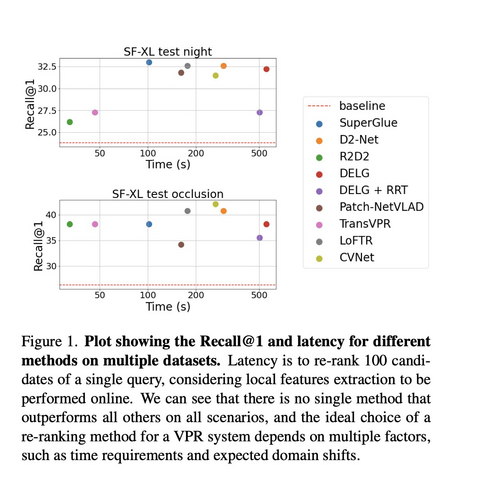
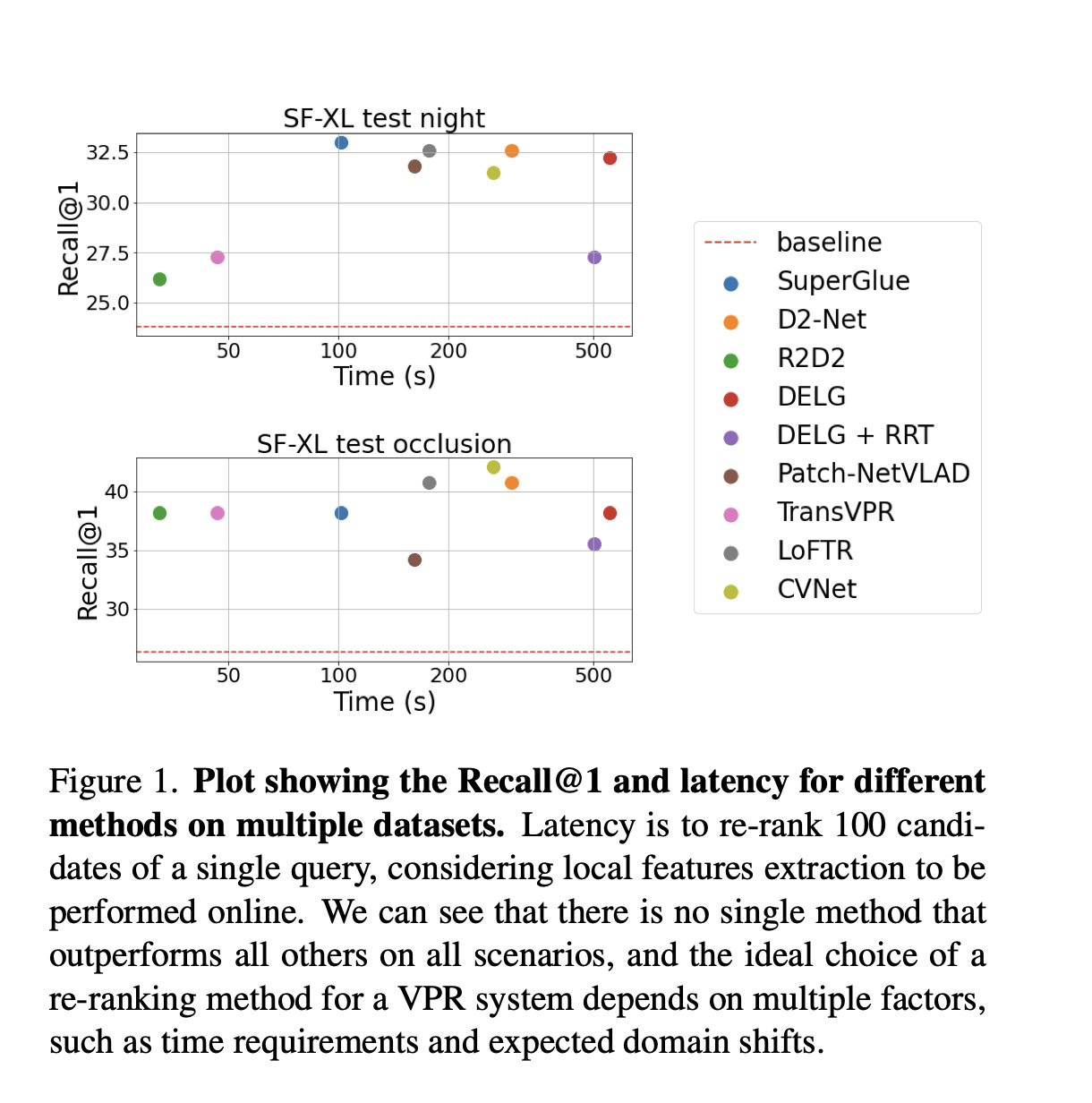
Are Local Features All You Need for Cross-Domain Visual Place Recognition?
Giovanni Barbarani et al.
tl;dr: SG, CVNet and DELG are good for retrieval reranking for VPR, new datasets are far from solved, night imagery is hard not only because of darkness.
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
993 followers · 397 posts · Server sigmoid.social
SiLK -- Simple Learned Keypoints
Pierre Gleize, Weiyao Wang, Matt Feiszli
tl;dr: DISK simplified - trained on random homography with other augmentations -> near SOTA on #IMC2022, better than DISK or SG cosim
Also, padding is detrimental for performance.
#IMC2022 #computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
990 followers · 391 posts · Server sigmoid.social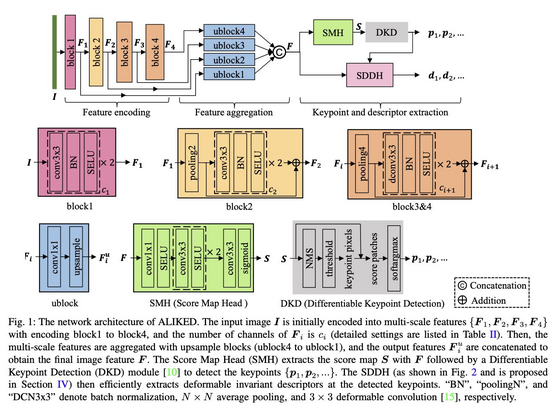
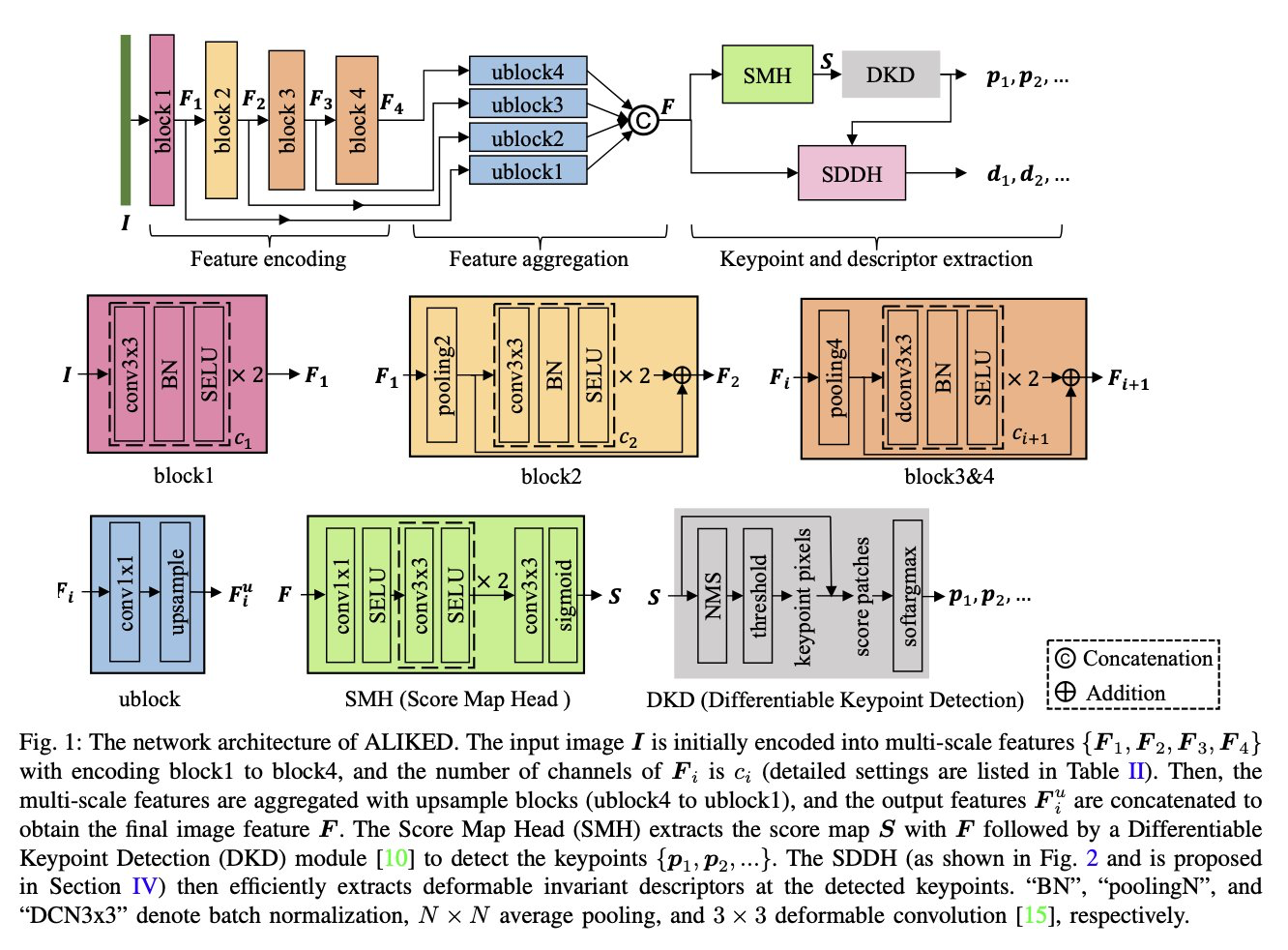
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Xiaoming Zhao, Xingming Wu, Weihai Chen, Peter C. Y. Chen, Qingsong Xu, Zhengguo Li
tl;dr: Journal ALIKE, many arch ablations. as good as DISK, but much faster
https://arxiv.org/abs/2304.03608.pdf
#computervision #deeplearning
#dmytrotweetsaboutDL
#computervision #deeplearning #dmytrotweetsaboutdl
Dmytro Mishkin 🇺🇦 · @ducha_aiki
988 followers · 385 posts · Server sigmoid.social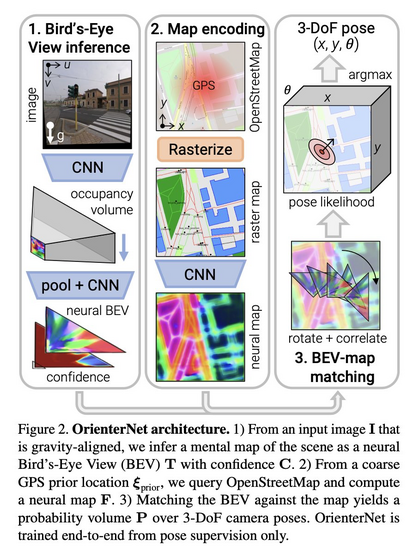
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
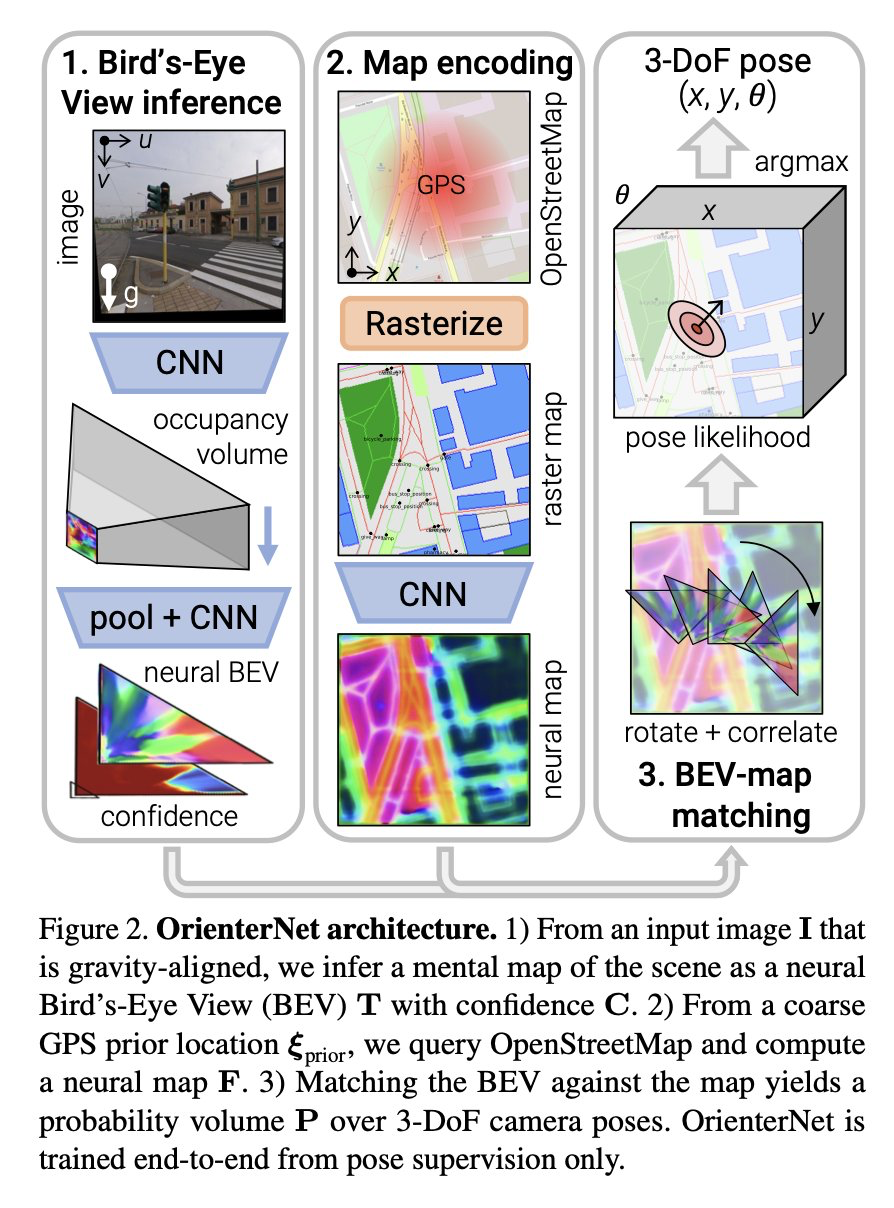
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bulo, Richard Newcombe, Peter Kontschieder, Vasileios Balntas
tl;dr: Photo -> neural bird's view -> matching vs encoded 2D map -> profit!
https://arxiv.org/abs/2304.02009
#computervision #deeplearning
#dmytrotweetsaboutDL
#computervision #deeplearning #dmytrotweetsaboutdl