
Micky · @mickylindlar
314 followers · 958 posts · Server digipres.clubYves Maurer now presenting the Luxembourg web archive:
in operation since seit 2016 (legal deposit since 2009), 120.000 seeds (3.000 of those not in .lu), 621 TB WARCs, 5.2 Mrd. URIs .... and a staff of 2
#nestorWebarchivierung
Micky · @mickylindlar
314 followers · 957 posts · Server digipres.club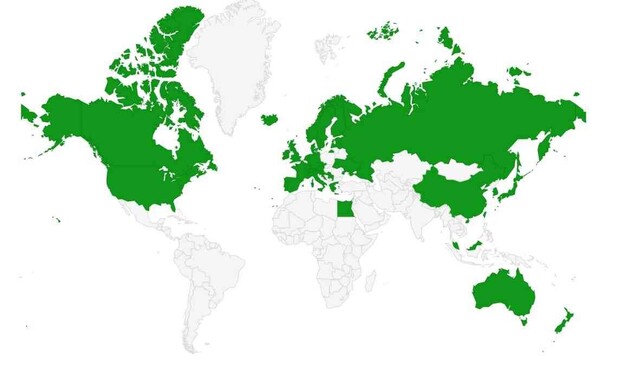
{kind=link}
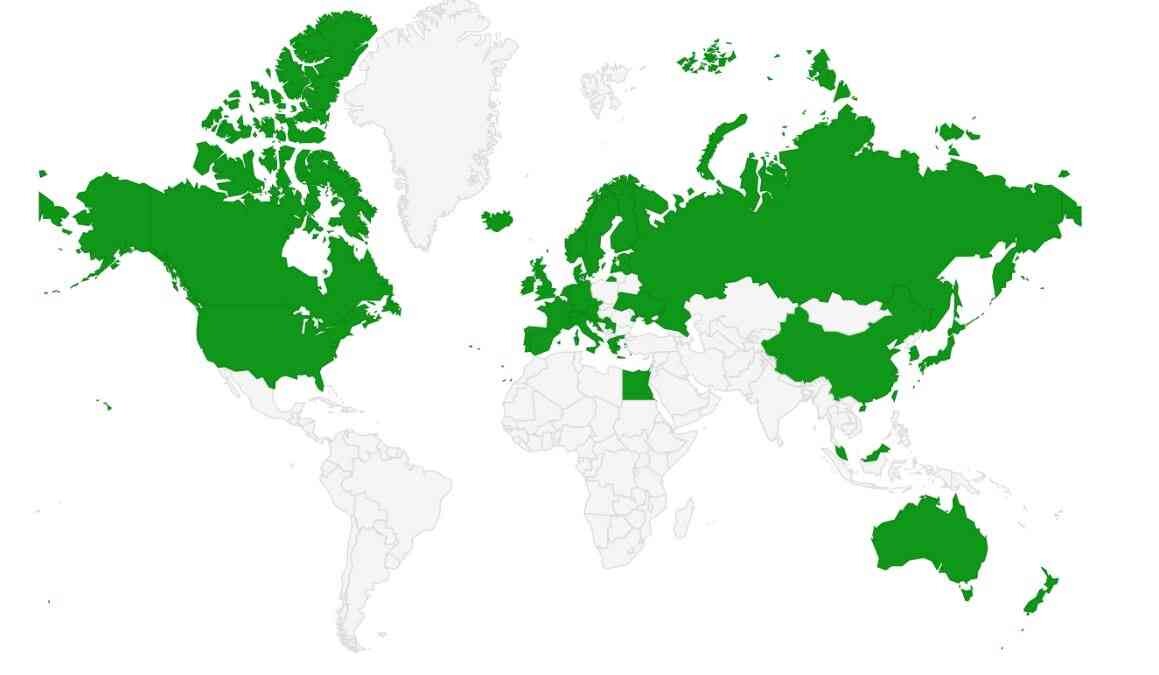
Nadezhda Povroznik is showing this WIkipedia "Map of Web archiving initiatives worldwide in April 2021". While it's not updated to reflect the actual current state, it really highlights a huge gap in global information archiving #nestorWebarchivierung
See https://en.wikipedia.org/wiki/List_of_Web_archiving_initiatives
Micky · @mickylindlar
314 followers · 957 posts · Server digipres.clubTolle Präsentation rund um partizipative Webarchivierung von Barbara Bossert & Leonie Rodrain von der ZLB Berlin ... es geht um Vorbeugung gegen Selection Bias, Cultural Humility & integrative Archivpraxis. Sehr gut gefällt mir der Leitsatz "Nicht nach Objektivität streben sondern Subjektivität transparent machen". Ich wünschte, dass dieses auch in (großen) wissBibs Einzug halten würde. Open Science in Verbindung mit Sammlungspraxis to the Resuce !? #nestorWebarchivierung
Micky · @mickylindlar
313 followers · 954 posts · Server digipres.clubrealizing once again that i know far too little about webarchiving. to me it always looks like ... "we collect these things, dump them somewhere and there's some tool that renders them in the browser. the hardest part is collecting stuf."
is that true? I find that in other materials the hardest part is the actual preservatoin stuff like profiling content, identifying risks, etc.
What am I missing?
#nestorWebarchivierung
Micky · @mickylindlar
313 followers · 954 posts · Server digipres.clubbsz - the library service center of the german state of baden-wurtemberg, has been offering webarchiving as a service since 2006. since 2017 the service is offered on basis of / in cooperation with ArchiveIt. WARCs are in addition stored as a second copy at KIT Karlsruhe to ensure the harvests are available within Germany. Currently approx 600 domains are harvested.
#nestorWebarchivierung #nestor
#nestor #nestorwebarchivierung
Micky · @mickylindlar
313 followers · 954 posts · Server digipres.clubGerman National Library (DNB) embarked on a "German Twitter Archiving" spree before the Twitter APIs closed. Total of 220 Mio Tweets from 5.8 Mio accounts between 03/2006 - 06/2011 were collected (640 GB). Only text collected, no media (if present only as links). This is only 6% of the identified German tweets based on language code. DNB is looking to close gap through donations. #nestorWebarchivierung