
青草风铃🌱 · @LittleGrass
77 followers · 5826 posts · Server go5.dev
青草风铃🌱 · @LittleGrass
77 followers · 5826 posts · Server go5.dev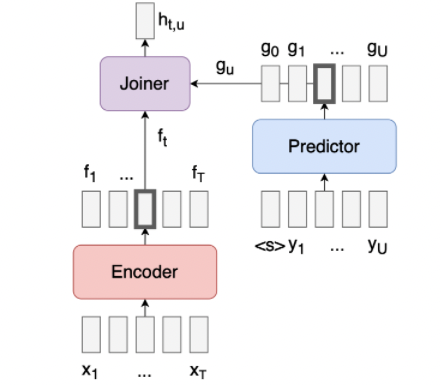
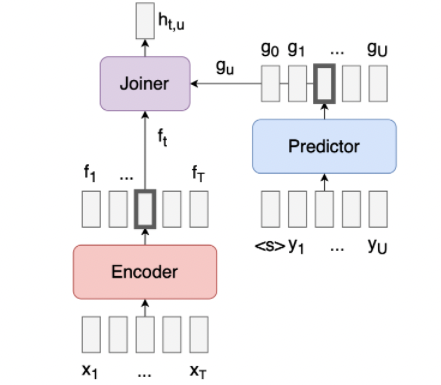
又看一遍突然明白了Transducer的结构。joiner和decoder并没有功能重复,其实joiner更像classic transformer里面那个decoder,要处理encoder output和decoder input,然后生成output,跳过空字符之后传给decoder。这个模型里的decoder就是一个纯纯单decoder了,甚至有的示意图里都不叫它decoder,只叫它predictor(比如这个图),它不处理encoder output,唯一功能就是使用被joiner筛选好的文字预测下一个。
#码碎片 哼哼本宝是如此聪明智慧!
青草风铃🌱 · @LittleGrass
77 followers · 5826 posts · Server go5.dev不过酱紫我就在琢磨这个程序还是可以改进的,比如其实没有必要把信息存到内存里再一起写入。虽然平时都是先放到内存再写,因为这样比较简单,但是lab之类的这不都是很规范的数据,只要代码没错就不会随便卡住。
这种数据乱七八糟的还是应该边读边写!省内存是次要的,反正也占不了多少,主要是如果卡住就会什么都出不来,但是边读边写至少能把正常的都写进去。然后琢磨一下怎么样可以断点重续,不需要每次从头写起。
#码碎片
青草风铃🌱 · @LittleGrass
75 followers · 5180 posts · Server go5.dev半夜学习惊闻(半夜学习原因省略):原来coefficient在scikit learn的linear regression里面和统计的linear regression里面竟然不是一个意思!震撼,R跑出来的系数竟然不是coefficient,统计里面的指的是coefficient of determination也就是R2。更震撼的是我怎么毕业了才悟到啊??
还是#码碎片 一下 :0090:
青草风铃🌱 · @LittleGrass
72 followers · 5057 posts · Server go5.dev
准备速成一下full stack,目前搜集到的看起来不错的顺序是先看帅哥https://www.youtube.com/playlist?list=PLZlA0Gpn_vH8jbFkBjOuFjhxANC63OmXM 打点基础,再跟着这个15hr付费课程做一个项目 https://www.udemy.com/course/react-node-ecommerce/
还有一个评分更高功能更多看起来性价比更高的,但是要46hr感觉我没有这个耐心只会从入门到放弃……https://www.udemy.com/course/node-react/
#码碎片
青草风铃🌱 · @LittleGrass
62 followers · 4732 posts · Server go5.dev实验结果:我说得对,真的会遗忘。宝宝好机智,模型好狗。淦。混着训分着evaluate的代码改好了,等跑完看看结果。
还有一个小小的发现:直接把数据做成Q+A的格式训练效果一般,因为感觉模型识别不出来问题。很简单地改成“Question: Q. Text: A”效果就会好不少,好吧可能也不是特别不少,好一些。感觉是这种定位词能够被模型“理解”。如果换成特殊符号可能会更好一些,但是俺懒得试了。。。就是说prompt engineering也确实不只是在问ChatGPT问题的时候有用!
#码碎片
青草风铃🌱 · @LittleGrass
62 followers · 4732 posts · Server go5.dev刚走在路上琢磨了一下,对于要回答很多问题的模型,也许更好的方法不是一个问题一个问题训,因为每切换一个问题loss都会突然变高(肯定的),然后在这个问题里面的参数变化方向只是在降低在这个问题里的loss,那这样是有可能覆盖也就是模型可能“遗忘”前面的训练结果的。问题穿插着来,整个做成一个大的train loader说不定会好一点额。
下一版代码可以训完第一个问题加一下测试第一个问题的accuracy,然后全训完再测试一下,第一个问题的accuracy,看要不要整个改数据,,记着加呃呃呃!
#码碎片
青草风铃🌱 · @LittleGrass
62 followers · 4732 posts · Server go5.dev今天吃屎一样写了六个小时得出的结论:transformers里面的xxxxxforQuestionAnswering都不能用来回答总结性的问题。这种模型(好像通常是Bert系列)的output是起始和结束的节点的分布,把起始和结束的分布分别做argmax得出的是起始和结束概率最高的节点,也就是模型的作用是用【截取】和【复述】输入来回答。想要总结性的就是得找个有decoder的啊!!!
所以今天写了一下午的结论是这个模型也不适合 :aru_0250:
奄奄一息的#码碎片
青草风铃🌱 · @LittleGrass
62 followers · 4732 posts · Server go5.dev
青草风铃🌱 · @LittleGrass
62 followers · 4732 posts · Server go5.dev
今天搞定的最主要的事:GPT-2作为一个纯粹的decoder,training input是要把input和output都搞在一起的,但!是!搞dataset的时候要设定一个可以把输出部分切掉的function!可以直接call用来把val和test的output切掉!不然就把答案都包含在input里了。常见的方法就是在class dataset里面搞个inference,像这样👇
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4144 posts · Server go5.dev啊对记一笔……昨天发现跑一次崩一次的原因是使用pretrained tokenizer的时候不要瞎鸡儿padding……空了看一下之前要padding的是因为什么。
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4144 posts · Server go5.dev记一笔,fine-tune好像非常容易overfitting。这个好得出乎意料的结果是只跑了一个epoch,而且也没有shuffle,准确率略高于0.68。辛辛苦苦快四小时跑了三个半epoch还shuffle的准确率是,是,是0.007🙂,, 用了很高级的模型的同学本来有0.9,但是private test突然降到0.67,看起来也是那个复杂模型会导致overfitting。
总的来说epoch就是小epoch。以及这次有七万多数据,另外的项目推荐数据量是1w-2w,一个猜测,如果数据量大epoch就要更小。
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev啊对还有如果收敛太快,把hidden layer增加点,神经网络搞复杂点。不过有点存疑啊,如果数据量小的话是不是搞太复杂模型太大而数据小反而表现会下降啊,好像看到过这种论文(的摘要)来着 :0080:
模型本身的层数也可以增加,同学搞到了4但是暂时存疑,不是传说2或者3就足够好了嘛。
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev存模型:
只存parameter:torch.save(model.state_dict(), PATH)
存整个模型:torch.save(model, PATH)
加载模型torch.load(),具体的用的时候再查吧!
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev继续记录,同学的经验全给我偷过来了,今次懒得改模型了,就记一下吧。
- 模型__init__里加dropout;
- DataLoader搞batch的时候shuffle=True,不然的话每次都搞一样的数据效果有限,不过这样每次都要重新加载数据所以训练过程会慢一点;
- 除了看loss也可以看dev_set的f1;
- Adam一开始用小learning rate,1e-4有点太小了,可以5e-4,跑个三十epoch左右换1e-3。吗的写到这意识到我写的是10e-3,这也太大了🆘 脑子进屎啊我为什么给它加了个0!(但还是懒得改了,,
- embedding用pretrained,设置required_grad=False固定embedding,然后跑到三四十的时候再改成True允许back propagation调整。
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev今天没再肉眼观测收敛(……),设置了一下停止训练的收敛条件。因为数据量比较小,跑得还挺快,所以batch size就设置了1没改,理论上应该不会比1更好了!
SGD的learning rate是0.1。理论上两个都调一调会比较好但我懒得搞了就这样吧。。。
表现最好的是Adam收敛后换SGD,然后SGD竟然就完全不收敛硬生生跑了200个epoch……但我不想再增加了!loss都降到0.02了感觉已经overfitting……!收敛条件也完全不高,是最后一个epoch不低于最后三个epoch loss的平均值,aka连续两个epoch没什么卵用。把收敛条件提高也没区别,三个到五个都试过,反正都是不收敛跑完两百个,没什么区别。。。
表现第二好的是Adam收敛后换SGD,不收敛了再切回Adam,这样循环,如果在optimizer是SGD的时候收敛了就结束训练。这个结束太快了,所以为了多训练几个回合,收敛条件设置得比较高,最后一项loss不低于最后五项loss的均值。这个一共跑了38个epoch就停下了,但比Adam直接跑100个epoch提高了差不多2%。
不过100个Adam看起来已经overfitting,肉眼看得到loss开始瞎几把跳。但还是比100个SGD好。你好你完全不收敛的是吗。
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev诶,一个optimize记录:可以先用Adam,learning rate一般10e-3效果比较好,收敛快,收敛之后再用sgd仔细调调(?)
update:1e-3!吗的脑子进了什么东西给加了个0啊!
#码碎片
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev哦对还有没事少用regex。。。数据越复杂用了越后悔,别debug了趁早换方法。。。只有用re.search然后group的时候值得用一下……!
除了自己爬网页也少用BeautifulSoup……!跑都不一定能跑出来别说对不对了!
反向#码碎片 :0080:
青草风铃🌱 · @LittleGrass
61 followers · 4017 posts · Server go5.dev
{kind=link}
{kind=link}
{kind=link}
{kind=link}
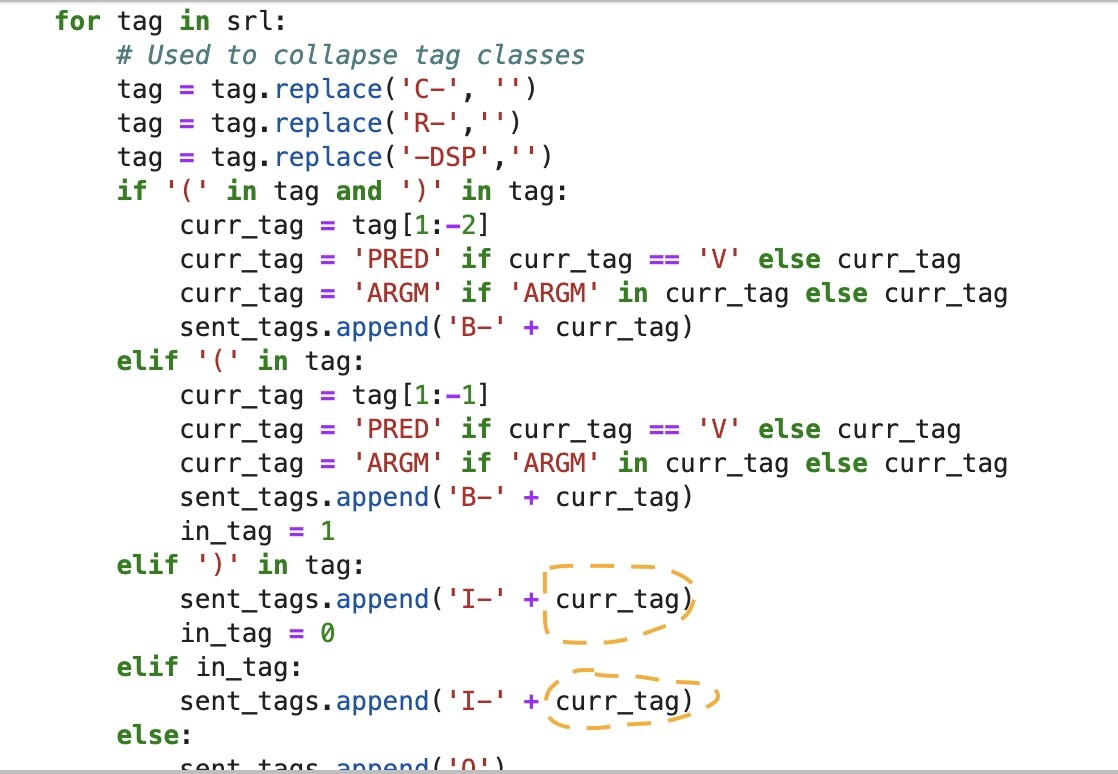
啊对记录一个智慧代码。IOB/SRL tagging和类似的任务适用。看起来在elif里面还没有定义curr_tag,但其实只是这一轮里没有定义。如果走到了这个elif说明前面一定已经有过B-,在B-的那一轮循环里面已经定义过了。
也可以存在stack里,在到达最后一个I-之后把它pop出去,但是如果这样用又需要设置有点复杂的条件,而且一个变量就能解决不用非得整一个stack出来。这样设置条件的话到了新的B-,curr_tag就会自动更新。配合in_tag这种flag可以判断这个登西到底是I-还是O。
关键是设置条件的逻辑!#码碎片