
杂食型蓑白(赛里斯地区的形态) · @hiromst
1478 followers · 6111 posts · Server mastodon.social「衬衫的价格是九镑十五便士」。当人类被问到根据该信息回答「衬衫多少钱」时,人脑是可以通过对句子进行结构分析——「价格」是主语、「衬衫」是表语、「是」是谓语、「九镑十五便士」是宾语,从而寻找到问题需要由宾语携带的信息来解答。
但AI(或者说深度学习算法)并不是这样工作的。它并不能真正「理解」句子的结构及其含义,而是将其转换为毫无意义的单元进行数学计算——衬-元素A、衫-元素B、……士-元素L,然后计算各元素之间的关联性(两个元素共同出现的「概率」)。在基于大量材料的类似计算下,算法会逐渐发现元素A(衬)和元素B(衫)一同出现的概率明显高于A与C、D……等一同出现的概率,于是算法认定两者存在关联,记为元素AB,整个句子于是被重新转换为更深层次的元素组合-AB(衬衫)、C(的)、DE(价格)……KL(便士),然后算法对新转换出的元素组合重复上面的概率计算(#过度简化警告)。最终,算法能够通过概率数字建立元素AB与元素GHIJKL之间的关联,于是为包含元素AB的问题返回元素GHIJKL。
↓
杂食型蓑白(赛里斯地区的形态) · @hiromst
1478 followers · 6110 posts · Server mastodon.social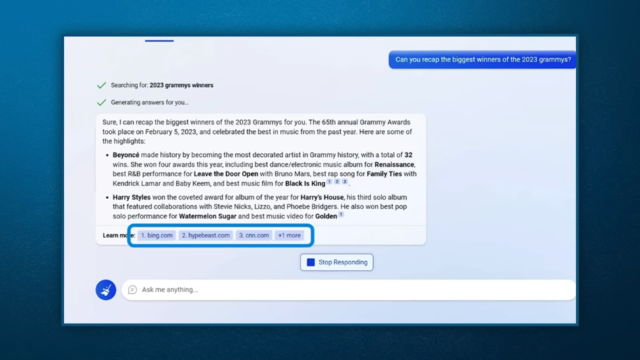
{kind=link}
从目前公开的情报来看,整合了#chatGPT 的#微软 #Microsoft #必应 #bing 搜索引擎在「对原作者/#版权 的尊重」上已经超过了九成九的丝国默嘟象用户,因为它会清晰直接地列出所提供信息的来源链接,而这是目前汉语联邦网络上绝大部分人都做不到的。
https://mastodon.world/@joannastern/109825729497466444
(当然搜索引擎本身对信息的索引涉及到「合理引用」以及避风港原则等的影响,不作展开)
我想就这个话题补充一些信息,因为我发现大部分对#AI 技术的反对者对于它的基本原理是有严重误解的,这影响了祂们观点的准确性。
比如最基础的,AI的反对者普遍会将算法「#人格化」和「#主体化」,反而是AI的支持者可以更好地以「#工具化」「#客体化」的视角审视这类技术。我很高兴看到#新卢德主义 开始出现在话题中,这对于我们梳理#人工智能伦理 有很大帮助。
预先说明:因为我并非技术背景出身,以下嘟文存在着#过度简化 的问题,有任何反驳和补充欢迎加入讨论。
让我们开始吧——
#chatgpt #微软 #microsoft #必应 #bing #ai #人格化 #主体化 #工具化 #客体化 #新卢德主义 #人工智能伦理 #过度简化