
acemaxx · @acemaxxanalytics
275 followers · 3521 posts · Server econtwitter.net
eicker.news #technews · @technews
86 followers · 838 posts · Server eicker.news»#Alphabet’s #Wing partners with #Walmart for drone deliveries in Dallas: Wing says it can deliver to nearby homes in ‘under 30 minutes.’« https://www.theverge.com/2023/8/24/23844975/alphabet-wing-walmart-drone-deliveries-dallas?eicker.news #tech #media
#Alphabet #wing #Walmart #tech #media

C. · @cazabon
171 followers · 4261 posts · Server mindly.socialBesides the impracticality of blocking it, there's another good reason not to do it.
Don't let companies escape the reputations they've earned through their own shitty actions and mistreatment of users.
Don't call Tw*tt*r "X".
Don't call Google "Alphabet".
Don't call Facebook "Meta".
They all did things that turned their names into ugly reminders of their behaviour. Don't help them escape that.
#google #facebook #Alphabet #meta #reputation #rebrand

Dr. Michael Blume · @BlumeEvolution
6655 followers · 5142 posts · Server sueden.social@MartinM Interessant (und wirklich nur zufällig?) ist ja, dass sich das „M“ als #Alphabet-Zeichen für #Wasser-Wege in der Mitte (M-itte) der Buchstabierlisten durchsetzte, auch etwa bei M-eer, M-edien oder den Göttern von Krieg und Handel M-ars & M-erkur. 🤔💧🖖 Du bist ja mit zwei Ms auch so ein verbindender Typ! 😊📚✍️

DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net
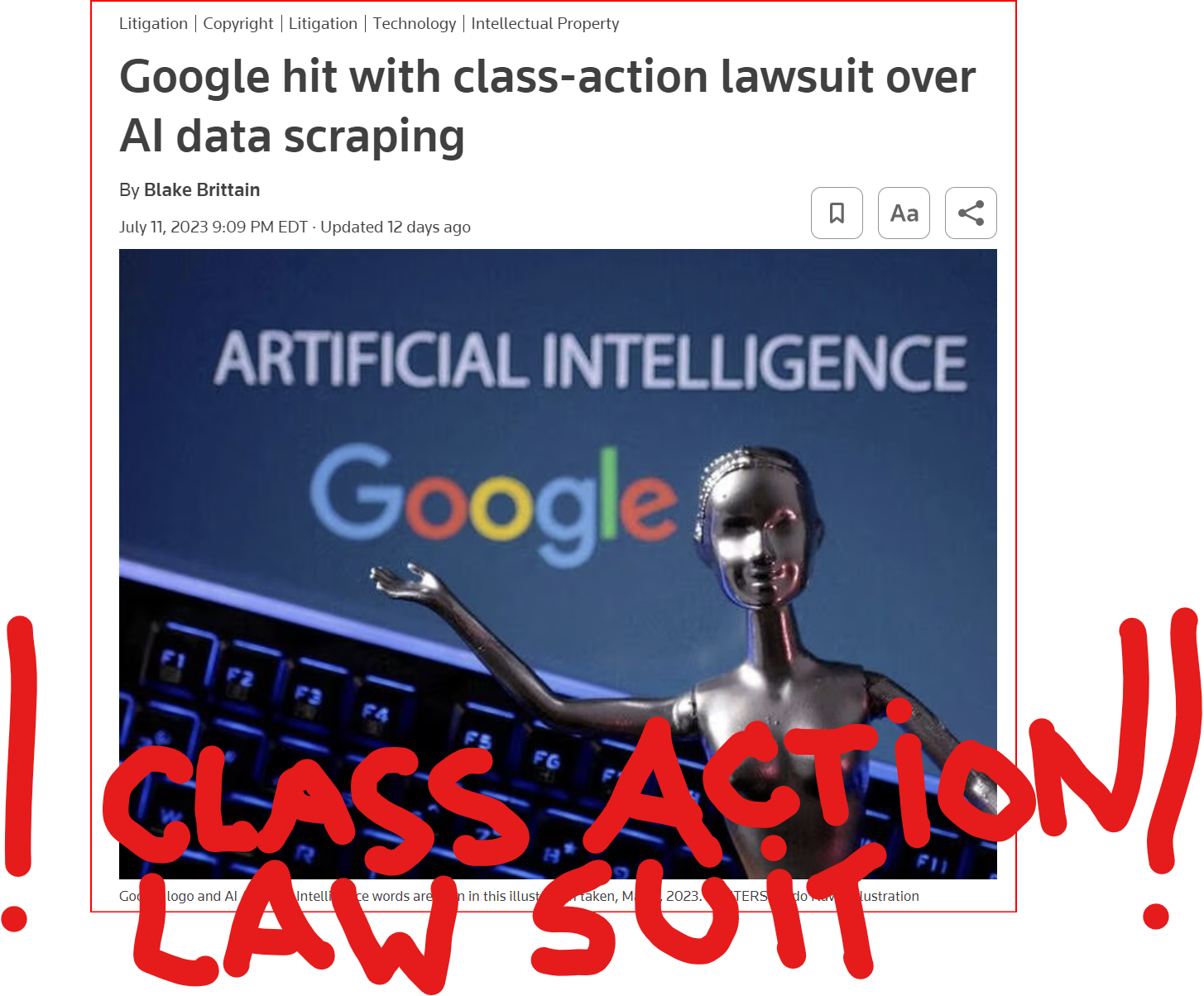
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1706 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1706 posts · Server tastingtraffic.net
GOOD #MORNING WORLD | INTERNATIONAL #TECH NEWS
#Lawsuit Alleges Google #Illegally #Scraped #User_Data for #AI_Development
In this video, we discuss the recent lawsuit against #Google, #Alphabet, and #DeepMind, accusing them of #unlawfully #scraping_data from #millions of #users and #violating #COPYRIGHT_LAWS.
Find out the details of the complaint, including the use of personal and copyrighted works to #train Google's #AI products. Discover the potential legal #implications and the #demands of the #lawsuit.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#MORNING #Tech #lawsuit #illegally #SCRAPED #user_data #AI_Development #google #Alphabet #deepmind #unlawfully #scraping_data #millions #users #violating #COPYRIGHT_LAWS #train #ai #implications #demands #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1698 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1697 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2981 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
acemaxx · @acemaxxanalytics
242 followers · 2981 posts · Server econtwitter.net
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#ArtificialIntelligence and writers - The open letter, which has been set up by the Authors Guild, America’s largest professional organisation for writers, is addressed to the CEOs of #OpenAI, #Alphabet, #Meta, Stability AI, and #IBM - chart @guardian https://tinyurl.com/2nh7s2sf
#artificialintelligence #openai #Alphabet #meta #ibm

Stefan · @kranzkrone
204 followers · 9058 posts · Server quasselkopf.deSo that this is clear once and for all for the Future and as a Note to refer to:
Apple / Google / Meta / Amazon are NOT the good Guy's who do something for Data protection and Privacy but work AGAINST it through Lobbying which is financed with Millions!
All these Companies have earned no Trust but Distrust, ALWAYS and in EVERYTHING they do!
#apple #Alphabet #amazon #meta #dataprotection #privacy
Stefan · @kranzkrone
204 followers · 9058 posts · Server quasselkopf.deDamit das ein für alle Mal klar ist für die Zukunft und als Notiz zum verweisen:
Apple / Google / Meta / Amazon sind NICHT die Guten, welche für den Datenschutz und Privatsphäre etwas machen sondern DAGEGEN arbeiten durch Lobbyismus welcher mit Millionen finanziert wird!
Alle diese Firmen haben kein Vertrauen sondern Misstrauen verdient, IMMER und bei ALLEM was diese tun!
#apple #Alphabet #amazon #meta #dataprotection #privacy

Jan Penfrat · @ilumium
1223 followers · 1307 posts · Server eupolicy.social🎉 In other news:
24 European Parliament lawmakers from the @TheProgressives, #Renew, @eppgroup, @ecrgroup and the @EP_GreensEFA asked Parliament President #RobertaMetsola to suspend #advertising campaigns run through #Google’s parent company #Alphabet and on #YouTube over fears they could be sponsoring Russian #propaganda. They also urged to reallocate the EP’s advertising budgets to “trustworthy" ads methods (think: #TrackingFreeAds).
#renew #RobertaMetsola #advertising #google #Alphabet #youtube #propaganda #TrackingFreeAds #trackingads #SurveillanceAds #Privacy #foreigninfluence