
CrateDB · @cratedb
72 followers · 85 posts · Server fosstodon.orgCheck out our latest tutorial on how to import Parquet files into CrateDB using Python, PyArrow, SQLAlchemy, and Pandas 💡
Our Solution Engineer, Karyn Azevedo, shows you how to do it in a step-by-step tutorial👩🏻💻
Read the full blog post ➡️
https://hubs.ly/Q01M1k7d0
#cratedb #db #database #db #blogpost #technicalblogpost #techcontent #tutorial #Python #SQLAlchemy #ApacheArrow #Parquet #Pandas
#cratedb #db #database #blogpost #technicalblogpost #TechContent #tutorial #python #sqlalchemy #ApacheArrow #parquet #pandas

૮༼⚆︿⚆༽つ | NPC | last boss · @drsensor
106 followers · 432 posts · Server fosstodon.org
#nusa #webassembly devlog
Didn't expected that #wasm GC already in origin trial. Seems I need try if Host Types in wasm GC for JS API work in my case before moving to #ApacheArrow.
https://github.com/DrSensor/nusa/issues/5#issuecomment-1492839313
I wonder if there's a language or compiler that already support wasm GC 🤔 (I doubt rust js_sys and wasm_bindgen already support it)
#nusa #webassembly #wasm #ApacheArrow

FOSSlife · @fosslife
1559 followers · 68 posts · Server fosstodon.org
Inaugural recipients of newly-established FOSS Contributor Fund announced by Bloomberg https://www.fosslife.org/bloomberg-announces-first-recipients-new-foss-fund #FOSS #funding #Bloomberg #software #OpenSource #ApacheArrow #Curl #Celery
#foss #funding #bloomberg #software #opensource #ApacheArrow #curl #celery

François Michonneau · @fmic_
340 followers · 4 posts · Server hachyderm.io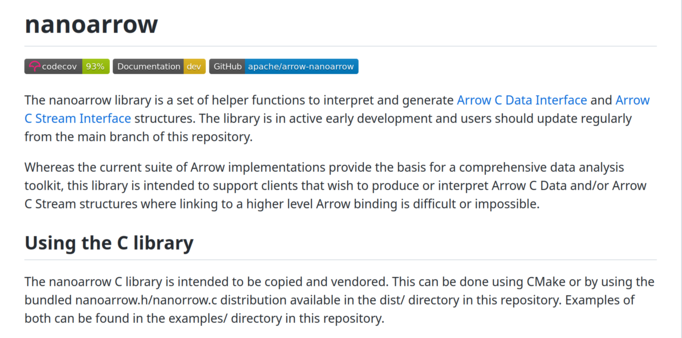
My colleague @paleolimbot has released nanoarrow, a small C library that provides an interface to the #ApacheArrow data structures. There is also an #RStats package for zero-copy conversions with R objects.
* blog post: https://arrow.apache.org/blog/2023/03/07/nanoarrow-0.1.0-release/
* R package: https://cran.r-project.org/web/packages/nanoarrow/index.html
* GitHub repo: https://github.com/apache/arrow-nanoarrow

Sharon Machlis · @smach
2007 followers · 938 posts · Server fosstodon.org
@eamon Although you can use :rstats: for data that won't fit in memory too 😀
@thomas_mock 's lightning talk at last year's Arrow conference
Video https://www.youtube.com/watch?v=LvTX1ZAZy6M
Slides https://jthomasmock.github.io/arrow-dplyr/#/
#rstats #DuckDB #ApacheArrow

Evan Pappas · @epappas
9 followers · 16 posts · Server sigmoid.social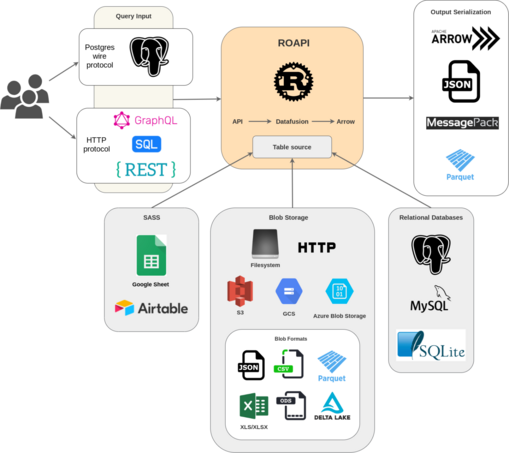
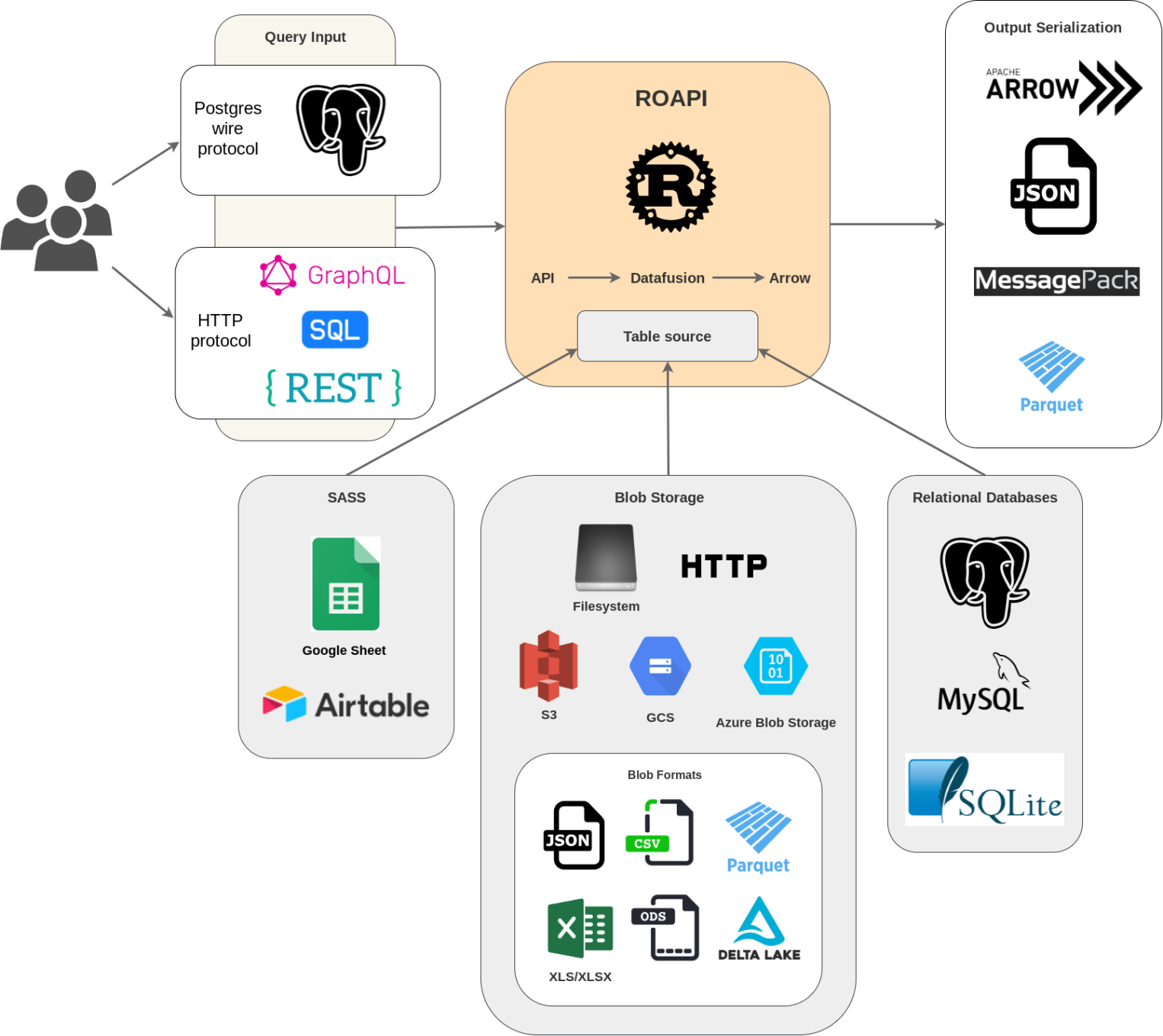
ROAPI automatically spins up read-only APIs for static datasets without requiring you to write a single line of code. It builds on top of #ApacheArrow and #Datafusion (and #rust).
#ApacheArrow #datafusion #rust

Matt Topol · @zeroshade
66 followers · 23 posts · Server data-folks.masto.host
Hey all!
I'll be presenting at #DataCouncil23, a 3-day, community-driven, data science, engineering, analytics & AI event, featuring over 10-tracks and 75+ speakers!
Come down and see me! I'll even have some signed copies of my book "In Memory Analytics with Apache Arrow" to hand out!
Looking forward to meeting lots of interesting people and having great conversations
#ai #community #event #engineering #datascience #analytics #apachearrow #databases
#datacouncil23 #AI #community #event #engineering #datascience #analytics #ApacheArrow #databases

Daniel Hocking · @djhocking
282 followers · 45 posts · Server bayes.clubI was just recommending @djnavarro posts about #ApacheArrow #Parquet and #DataScience in #RStats to someone and decided I'd share here too. She writes fantastic intros and explanations in entertaining posts, tutorials, and courses.
https://blog.djnavarro.net/posts/2021-11-19_starting-apache-arrow-in-r/
https://blog.djnavarro.net/posts/2022-11-30_unpacking-arrow-datasets/
#ApacheArrow #parquet #datascience #rstats

Lucas Longour · @llongour
65 followers · 56 posts · Server mapstodon.space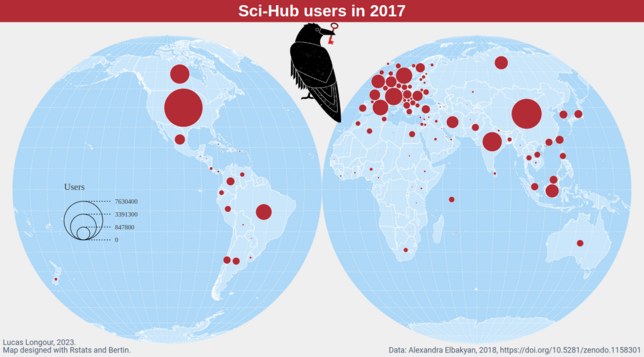
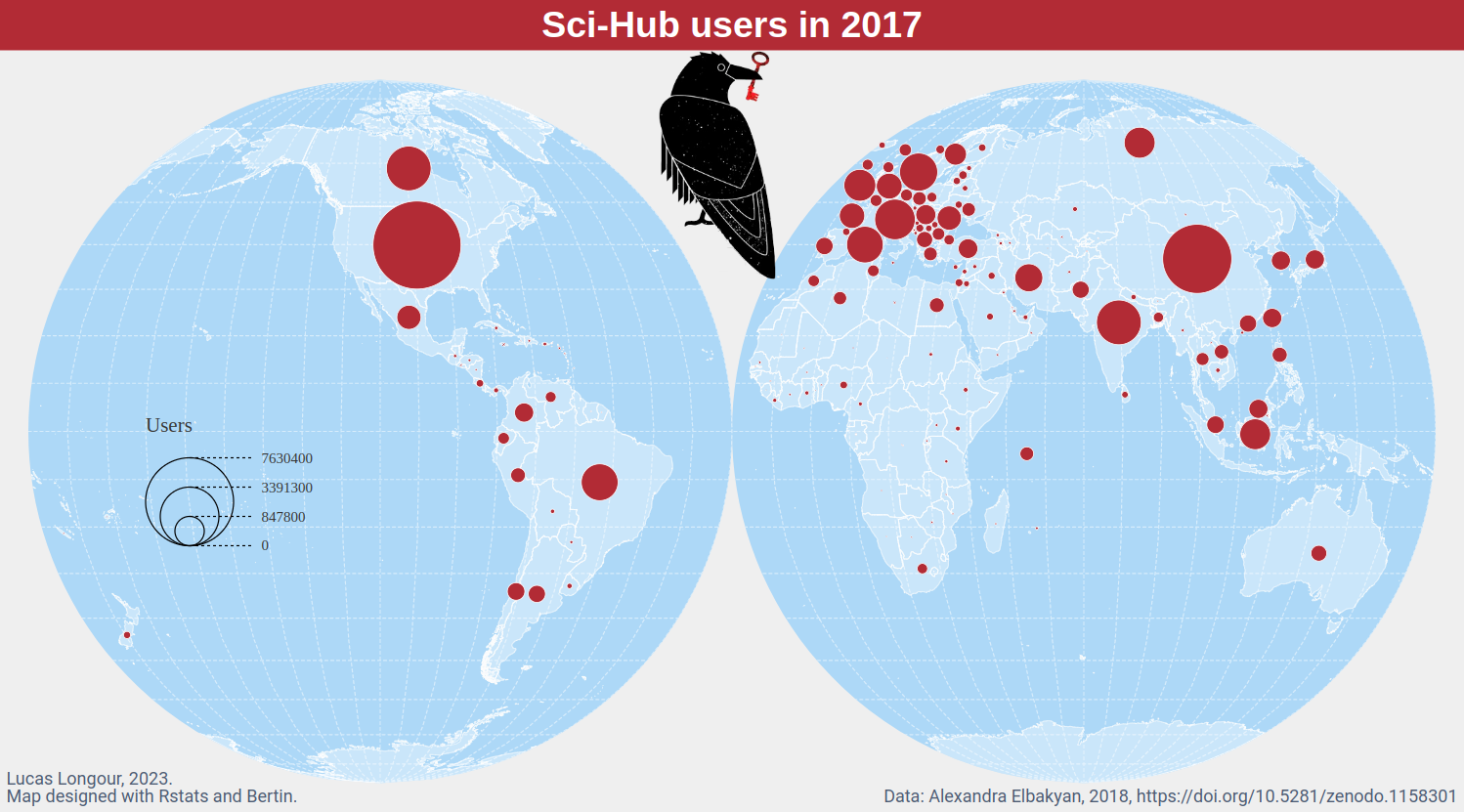
Just discovered the Sci-Hub download log on year 2017 (https://zenodo.org/record/1158301), so let's do a map ... but the original tsv file is very large ~14Go uncompressed. It's the perfect moment to try #ApacheArrow #Rstats package, and to make maps with #bertinjs .
#GISchat
#ApacheArrow #RStats #bertinjs #gischat

Olivier Grisel · @ogrisel
1640 followers · 50 posts · Server sigmoid.socialA short technical blog post by Christian Lorentzen (scikit-learn developer) on some computational aspects of the histograms used in Gradient Boosting Trees in scikit-learn / xgboost / lightgbm:
#DuckDB #ApacheArrow #tabmat #sklearn #pydata #machinelearning
#duckdb #ApacheArrow #tabmat #Sklearn #PyData #machinelearning

· @emauviere
57 followers · 9 posts · Server mapstodon.spaceLe format #ApacheParquet devient mainstream, il a pourtant presque 10 ans. En quoi est-il devenu un successeur crédible à #CSV ?
Quels sont ses rapports avec #ApacheArrow, ou #duckdb ? Comment l'utiliser dans #rstats ou #QGIS ?
Je vous éclaire ici 👇 :
https://www.icem7.fr/outils/parquet-devrait-remplacer-le-format-csv/
#apacheparquet #csv #ApacheArrow #duckdb #RStats #qgis

gianarb :nixos: :vim: :rust: · @gianarb
328 followers · 28 posts · Server m.gianarb.itI am thinking about writing an #ApacheArrow with #golang cheat sheet or something similar. I want to share a few of the lessons I have learned working with it. The pipeline I wrote works kind of fine so, I think it is time to collect what I figured out

Gunnar Morling · @gunnarmorling
797 followers · 111 posts · Server mastodon.online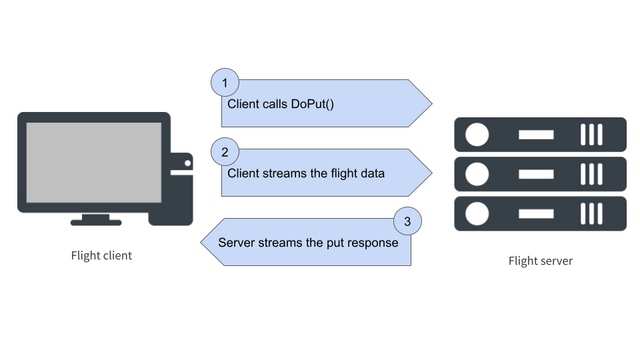
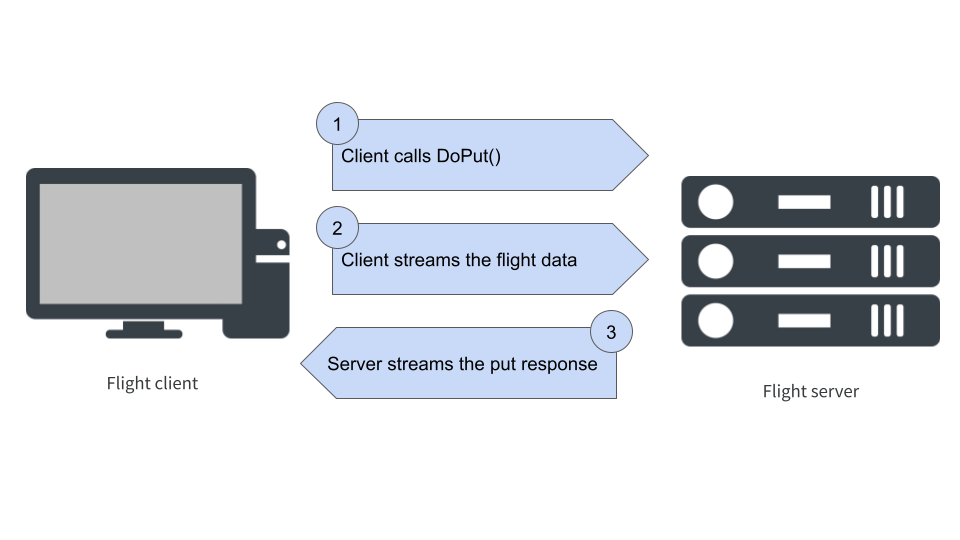
🗣️ "The central idea behind Flight is deceptively simple: it provides a standard protocol for transferring Arrow data over a network"
Great post by @djnavarro; #ApacheArrow Flight (and Flight SQL) is super-interesting, definitely keep an eye on it in '23.

Danielle Navarro · @djnavarro
3896 followers · 832 posts · Server fosstodon.orgSince Hadley has announced it on twitter I will do the honours on here, but I'll forego the pirate-speak out of common decency...
There's a new chapter on #ApacheArrow and Parquet data in R4DS. It's mostly based on my work so please let me know if you spot any problems with the chapter and I promise to annoy Hadley with a pull request fixing it #RStats
Danielle Navarro · @djnavarro
3814 followers · 734 posts · Server fosstodon.org
For reasons unknown she is blogging again. I am so sorry, but should you happen to be curious about how Dataset objects work in the #ApacheArrow #RStats package, and enjoy me being mildly irritable about... things, this post may be of some interest? :blobcatheart:

Kae Suarez · @kaesuarez
49 followers · 31 posts · Server hachyderm.ioHello! I'm Kae, and this is my Hachyderm.
I want to be clear about what's going to happen here.
I am going to be making a lot of posts that are me floundering with tech. That's the point. As a person in #DevRel, I think it's important to be honest about floundering now and then, and let others, especially engineers, see some pain points.
Plus, it can be entertaining, and gives me tons of draft material for my blog.
I hope I can show everyone some cool things!

Nic Crane · @nic_crane
74 followers · 1 posts · Server fosstodon.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A blog post I wrote comparing type inference in the CSV readers in readr and arrow 📦
https://thisisnic.github.io/2022/11/21/type-inference-in-readr-and-arrow/
#rstats #tidyverse #ApacheArrow
Nic Crane · @nic_crane
192 followers · 9 posts · Server fosstodon.orgA blog post I wrote comparing type inference in the CSV readers in readr and arrow 📦
https://thisisnic.github.io/2022/11/21/type-inference-in-readr-and-arrow/
#rstats #tidyverse #ApacheArrow
Danielle Navarro · @djnavarro
3738 followers · 706 posts · Server fosstodon.orgMy favourite trick for working with huge data sets in R. If your dataset is larger than memory and the query result is also larger than memory, you can still use dplyr/arrow pipelines. Example:
library(arrow)
library(dplyr)
nyc_taxi <- open_dataset("nyc-taxi/")
nyc_taxi |>
filter(payment_type == "Credit card") |>
group_by(year, month) |>
write_dataset("nyc-taxi-credit")
Input is 1.7 billion rows (70GB), output is 500 million (15GB). Takes 3-4 mins on my laptop 🙂
Matt Topol · @zeroshade
44 followers · 13 posts · Server data-folks.masto.host@jayatid Agreed! My current job is actually full-time working on the #ApacheArrow #golang and #parquet libraries. My book on Arrow also includes Go examples (in addition to Python and C++), but I'm still looking for any opportunities or assistance in building the community, haha.