
Tabular · @tabular
78 followers · 179 posts · Server data-folks.masto.hostA new Tabular Solutions episode is now available with Tabular co-founder Jason Reid. He shows Shawn Gordon how easy it is to set up a Google Colab notebook and use #ApacheSpark to read/write data from Tabular-managed #ApacheIceberg tables.
#iceberg #datalake #datalakehouse #dataengineering #googlecolab #apachespark
#ApacheSpark #apacheiceberg #iceberg #DataLake #datalakehouse #dataengineering #googlecolab

dazfuller :rickwhoah: · @dazfuller
102 followers · 1206 posts · Server mstdn.socialTook some time today to rewrite a local build script I have for my #ApacheSpark #Excel data source. I use it for running tests locally against multiple Spark versions and building jar files to deploy to a test #Databricks instance.
The current script is all in #powershell but I spend very little time in there anymore, so rewrote it as a #nushell script, and it’s so much cleaner and nicer to read
#nushell #powershell #databricks #Excel #ApacheSpark
Tabular · @tabular
71 followers · 152 posts · Server data-folks.masto.host
Our latest Tabular Bits shows you how to secure any compute engine against your Tabular managed #ApacheIceberg tables. We use #ApacheSpark in the example to show how simple it is to change access privileges from Tabular immediately. Less than 3 minutes to find out how this works. Secure your data, not your compute, with Tabular.
#apacheiceberg #ApacheSpark #datasecurity #dataengineering #DataLake #datalakehouse
Tabular · @tabular
71 followers · 146 posts · Server data-folks.masto.hostWe have a new interactive demo available that will let you walk through the steps involved in securing compute engines with Tabular against your Tabular-managed #ApacheIceberg tables. The concept is significant. A single, unified security layer is applied at the data layer, providing security for tools that don't inherently have them, like #ApacheSpark. Secure the data, not the compute.
#apacheiceberg #ApacheSpark #dataengineering #datasecurity #DataLake #datalakehouse

Danica Fine · @thedanicafine
143 followers · 92 posts · Server data-folks.masto.hostCurious to hear from folks, besides #apacheKafka, what are your favorite #streaming technologies? 🤔
#streamingdata #eventstreaming #streamingtechnology #apacheFlink #apacheSpark #apachePulsar
#apachekafka #Streaming #StreamingData #eventstreaming #streamingtechnology #apacheFlink #ApacheSpark #apachepulsar

rmoff 🏃🏻 🍺 🥓 · @rmoff
1153 followers · 800 posts · Server data-folks.masto.host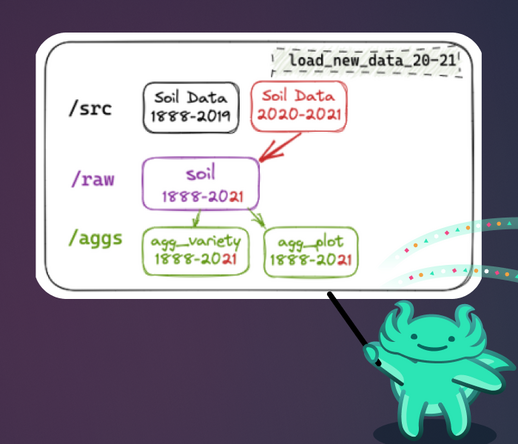
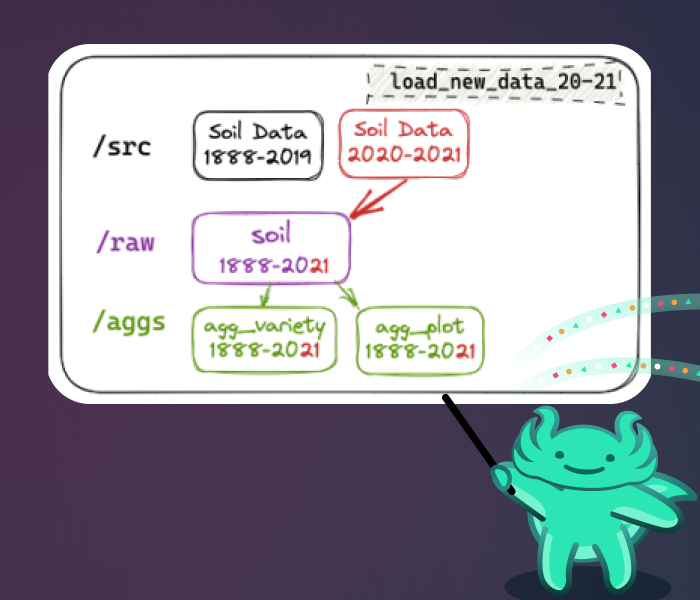
✍🏻 Final part of my blog series on Write-Audit-Publish (WAP), in which I show in detail how to implement it using #apacheSpark, @deltalakeoss, #Minio, and @lakeFS
---
📝part 1: 🙋🏻What is WAP? https://lakefs.io/blog/data-engineering-patterns-write-audit-publish/?utm_campaign=Social%20media%20activity&utm_source=Mastodon&utm_medium=social&utm_content=blog_rm-wap1
📝part 2: 🛠️ Comparing how different tools implement WAP https://lakefs.io/blog/how-to-implement-write-audit-publish/?utm_campaign=Social%20media%20activity&utm_source=Mastodon&utm_medium=social&utm_content=blog_rm-wap2
#ApacheSpark #minio #writeauditpublish #dataengineering #datadon #opensource
Tabular · @tabular
68 followers · 131 posts · Server data-folks.masto.hostThe end of May brings the May edition of the #ApacheIceberg Community News. There is a lot of great content from the community once again with the release of Iceberg 1.3, and significant updates to PyIceberg, with the 0.4.0 release right around the corner. Important support was added for #ApacheSpark version 3.4 and #ApacheFlink version 1.17. There is also significant news from the vendor community and great blog posts from folks like Anuj Syal and Marin Aglić Čuvić.
https://tabular.io/blog/iceberg-202305/
#apacheiceberg #ApacheSpark #apacheFlink
dazfuller :rickwhoah: · @dazfuller
96 followers · 993 posts · Server mstdn.social
Been busy working on updating our #ApacheSpark #Excel data source reader to support Spark 3.4
FileSourceOptions and SparkPath throwing up some changes needed, but prompted a rewrite of the options class which was needed anyway. Unit tests are all passing now for Spark 3.0.1 up to 3.4.0 which is good, now for some manual testing on #Databricks and #AzureSynapse
#AzureSynapse #databricks #Excel #ApacheSpark
dazfuller :rickwhoah: · @dazfuller
95 followers · 981 posts · Server mstdn.social
So my day has involved implementing a new feature into my #ApacheSpark Excel data source. And turning an old pallet into a new planter

Dustin Vannnoy · @dustinvannoy
1 followers · 4 posts · Server data-folks.masto.hostNew video: Your first Spark SQL application.
No Python, no Scala, just SQL.
#ApacheSpark #SQL #dataengineering
#ApacheSpark #sql #dataengineering
dazfuller :rickwhoah: · @dazfuller
95 followers · 981 posts · Server mstdn.socialSometimes it feels very lonely writing #ApacheSpark code using #Scala
But it’s still ducking awesome

Dustin Vannnoy · @dustinvannoy
1 followers · 2 posts · Server data-folks.masto.host
Next step in Apache Spark DataKickstart is available - how to setup Databricks Community Edition. A simple way to get an environment to practice writing Spark code.
#ApacheSpark #Databricks #DataKickstart
#ApacheSpark #databricks #datakickstart
Tabular · @tabular
62 followers · 91 posts · Server data-folks.masto.hostThe @ApacheIceberg newsletter for March is here. Lots of big news with version 1.2, #ApacheSpark, #ApacheFlink and vendor support.
https://tabular.substack.com/p/iceberg-newsletter-mar-2023?sd=pf
Dustin Vannnoy · @dustinvannoy
0 followers · 1 posts · Server data-folks.masto.host
I am creating Apache Spark DataKickstart - free online training. First video released, trying to release a new part to the course every week or so to teach #ApacheSpark as efficiently as I can. Check it out here: https://youtu.be/0kQ7Iq_lG-k

Wojtek · @WojtekWalczak
0 followers · 1 posts · Server awscommunity.socialMy Medium adventure enters a new phase: the first post for a Medium-held publication, Plumbers of Data Science, just got published :)
It's also more technical than my previous writings. The point is to introduce Apache Hudi in a softer way than the official documentation does at the moment. So, if you're interested in starting with Hudi, look no further :)
#apachehudi #apachespark #dataengineering
https://medium.com/plumbersofdatascience/apache-hudi-copy-on-write-explained-563f1d23d34f
#apachehudi #ApacheSpark #dataengineering

Holden · @holden
543 followers · 66 posts · Server tech.lgbtRT @jaceklaskowski
Trying to get the better grip over aggregation execution in #ApacheSpark #SparkSQL and wonder what to google for to learn how to describe the topic in a more academic style.
Used "introduction aggregation" with and without "spark" and found some resources.
Any other recs? 🙏

Kit Menke · @kitmenke
4 followers · 5 posts · Server data-folks.masto.hostCome learn about building near-realtime data pipelines with Databricks in a presentation from Scott Crawford at the STL Big Data I.D.E.A. meetup on Wednesday, December 7, at 5:30 PM (Central time, GMT-6). Bring your questions about Spark, Delta Lake, and Streaming! Hope to see you there. https://www.meetup.com/st-louis-big-data-idea/events/290019672/ #bigdata #apachespark #databricks #streaming #dataengineering
#bigdata #ApacheSpark #databricks #Streaming #dataengineering

rmoff 🏃🏻 🍺 🥓 · @rmoff
629 followers · 129 posts · Server data-folks.masto.host
Quite an interesting way to index multiple tools in the same space - including search engine hits, and LinkedIn supply & demand. Crude, but paints a broad picture that's not unuseful https://gradientflow.com/the-stream-processing-index/
#streamprocessing #data #apachespark #apacheflink #apachekafka
#apachekafka #apacheFlink #ApacheSpark #data #streamprocessing

Zach Wilson · @zach
795 followers · 150 posts · Server data-folks.masto.host
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hey Mastodon! I created a "content directory" for all my content across Linkedin, Twitter, and YouTube.
I spent about 60 hours engineering this over the last 2 weeks.
You can see my content split into categories like #dataengineering #apachespark, #apacheairflow, etc.
I'll be adding a search function soon too so you can find exactly what you're looking for from the mountain of content I've created over the last two years!
Check it out here!
#apacheairflow #ApacheSpark #dataengineering
Zach Wilson · @zach
1115 followers · 177 posts · Server data-folks.masto.hostHey Mastodon! I created a "content directory" for all my content across Linkedin, Twitter, and YouTube.
I spent about 60 hours engineering this over the last 2 weeks.
You can see my content split into categories like #dataengineering #apachespark, #apacheairflow, etc.
I'll be adding a search function soon too so you can find exactly what you're looking for from the mountain of content I've created over the last two years!
Check it out here!
#dataengineering #ApacheSpark #apacheairflow