
Sascha Wolfer · @sascha_wolfer
448 followers · 319 posts · Server fediscience.org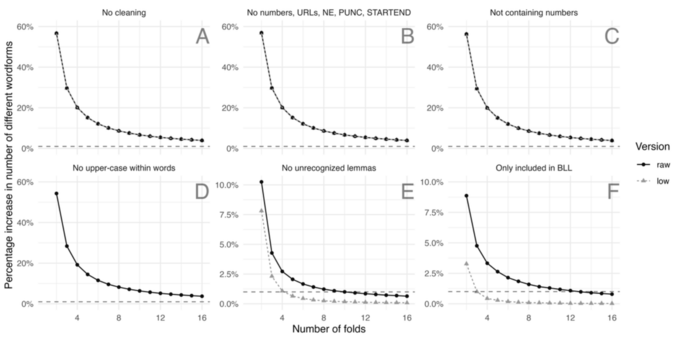
New preprint: We present a new #dataset on the #German #language: DeReKoGram includes uni-, bi-, and trigram frequencies, lemma and POS information for a corpus of around 43 billion tokens.
We evaluate the distribution over the 16 datasets and present a (small) case study on #vocabulary growth.
At https://www.owid.de/plus/derekogram, we provide #Python, #Rstats and #Stata code that should help you getting started with the dataset.
Preprint available at https://doi.org/10.21203/rs.3.rs-3139640/v1.
#linguistics #stata #rstats #python #vocabulary #language #german #DataSet

Pratik Patel · @ppatel
943 followers · 13083 posts · Server mstdn.socialThe MIT researchers found that #MachineLearning models trained for autocaptioning with their dataset consistently generated captions that were precise, semantically rich, and described data trends and complex patterns.
Researchers teach an #AI to write better chart captions.
A new #dataset can help scientists develop automatic systems that generate richer, more descriptive captions for online charts for #blind people.
https://news.mit.edu/2023/researchers-chart-captions-ai-vistext-0630
#generativeAI #a11y #Accessibility #blind #DataSet #AI #MachineLearning

Paweł Kleka · @pkleka
6 followers · 22 posts · Server fediscience.orgI am looking for a dataset with raw data from the WAIS test or other intelligence tests. My mentee is writing her master's thesis about mutualism and wants to reanalyse some actual data. Any help with the source? #opensource #OpenScience #dataset #rstats
#rstats #DataSet #OpenScience #opensource

· @gizz
3 followers · 5 posts · Server mstdn.social🎉 "Ramsauer & Marzahn present a global, hourly #SoilMoisture estimation based on #NASA's #GPM IMERG data and using a site-specific adjusted antecedent precipitation index (#API)"
🌧️🌍
🔗 https://doi.org/10.1080/01431161.2022.2162351
get the pdf here: https://www.tandfonline.com/eprint/6VHQ7JCCJXSPAMG3PVIG/full?target=10.1080/01431161.2022.2162351
Info:
https://www.researchgate.net/publication/368587895_Global_Soil_Moisture_Estimation_based_on_GPM_IMERG_Data_using_a_Site_Specific_Adjusted_Antecedent_Precipitation_Index
#soil #soils #moisture #global #data #DataSet #gpm #NASA #science #soilgrids #mdpi #remotesensing #satellit #ijrs #LMUMünchen #geography #Geodaten #geodata
#geodata #Geodaten #geography #lmumunchen #ijrs #satellit #remotesensing #mdpi #soilgrids #Science #DataSet #Data #global #moisture #soils #soil #api #gpm #NASA #soilmoisture

Shu Daizi · @SDZ
218 followers · 2093 posts · Server mstdn.social
Google's C4 dataset for training AI/LLM includes Literotica, Smashwords, Pornhub, Wattpad
Inside the secret list of websites that make AI like ChatGPT sound smart
https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
#AI #LLM #Dataset #DatasetTraining #Erotica #NSFW #Porn #Literotica #Smashwords #Pornhub #Wattpad
#wattpad #pornhub #smashwords #literotica #porn #NSFW #erotica #datasettraining #DataSet #LLM #AI

Kevin Karhan :verified: · @kkarhan
898 followers · 48815 posts · Server mstdn.social@stux because AI can only learn based off data - and beyond US-English and the official languages of #EU & #UN publications there's no sufficient #dataset to teach it other languages unless you're #Google and can run #Oltmann all day on your search index...
#Oltmann #Google #DataSet #un #EU
Kevin Karhan :verified: · @kkarhan
669 followers · 27540 posts · Server mstdn.social
Datendealerin · @Datendealerin
467 followers · 512 posts · Server fediscience.org
Did you know you can adopt a #DataSet? From now on and all of next week 🧡 #LoveData23 #ICPSR
➡️ Find your new lovable dataset here: https://www.icpsr.umich.edu/web/about/cms/1576

Céline Heuzé · @ClnHz
816 followers · 48 posts · Server mstdn.socialThe #dataset #authorship drama continues.
How frowned upon would it be if "a friend", when forced to add humans who did not contribute, created a profile for their #cat and added them as well? Reasoning being that said cat at least provided moral support and did use the keyboard while the dataset was open, unlike the extra humans. Hypothetically, obviously.
#fbullies #academia #Cat #authorship #DataSet
AV_SP · @AV_SP
143 followers · 42 posts · Server fediscience.orgA fMRI dataset acquired during naturalistic movie watching and narrated recall of a series of short cinematic films
https://www.sciencedirect.com/science/article/pii/S235234092200991X https://openneuro.org/datasets/ds004042/versions/1.0.0
Whole-brain fMRI data from continuous naturalistic tasks (here unguided spoken recall) are rare- this dataset can be reanalyzed using brain areas & functional characteristics not explored in the published articles- &, the behavioral data (transcripts of spoken recall) can be reanalyzed on their own!

Philipp Leitner · @xLeitix
98 followers · 114 posts · Server fediscience.orgThe #ICPE conference is this year again running a data challenge, this year with a #dataset of microbenchmarking data in Java.
https://icpe2023.spec.org/tracks-and-submissions/data-challenge-track/

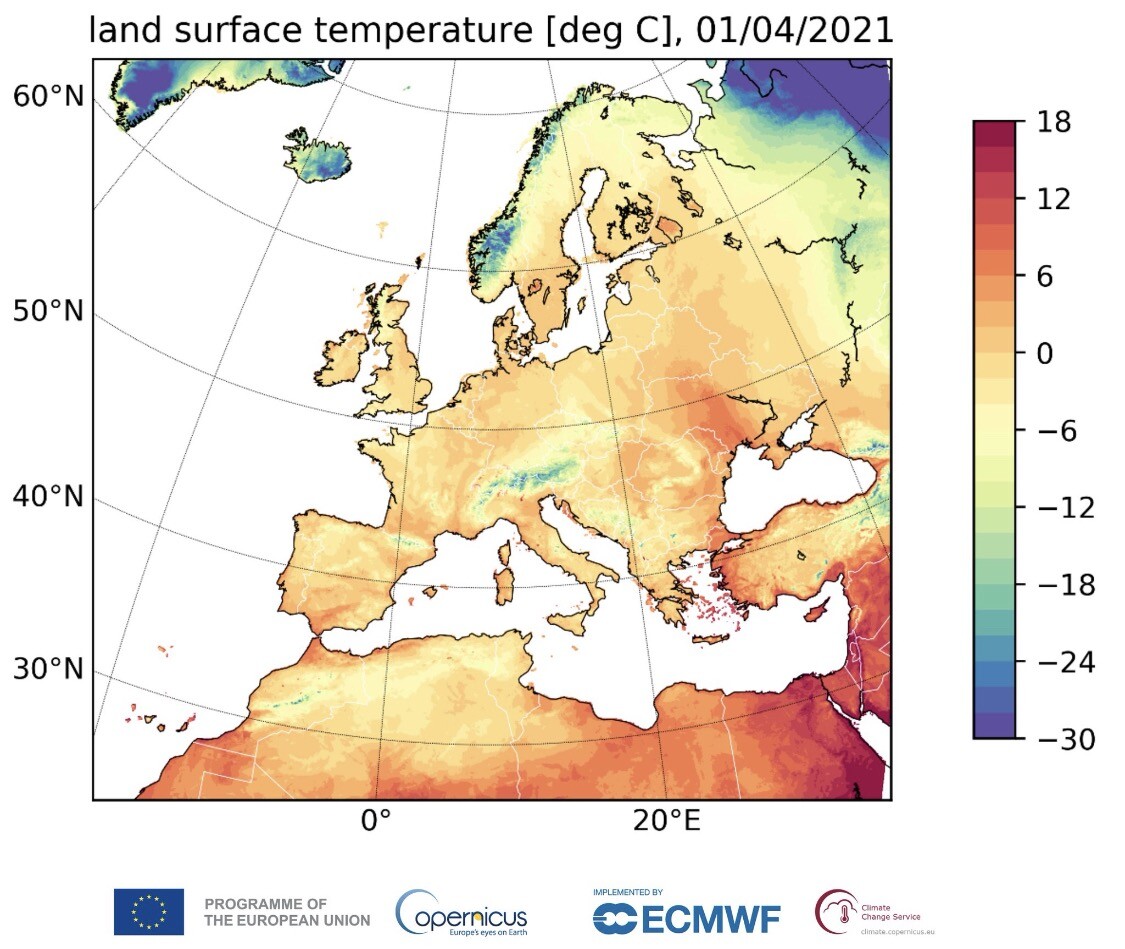
Dr Sam Burgess · @OceanTerra
328 followers · 24 posts · Server fediscience.org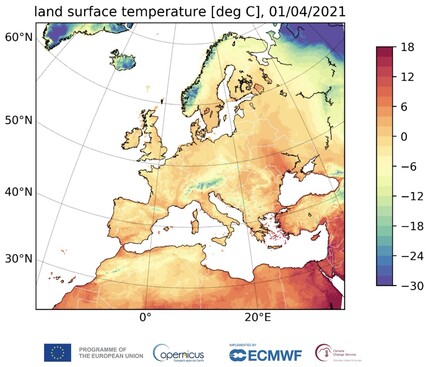
#CopernicusClimate has just published a new #reanalysis #DataSet for Europe.
It provides hourly estimates of surface & soil variables reaching back from 1984 at the same enhanced horizontal resolution of 5.5km as CERRA.
Access it via #C3S Climate Data Store: bit.ly/3MM8LLg
#Climate #opendata #C3S #DataSet #Reanalysis #CopernicusClimate

Steven P. Sanderson II, MPH · @stevensanderson
2 followers · 7 posts · Server mstdn.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
If you want to quickly find #skewed #features in a #dataset in #r then you can use my #r #package {healthyR.ai}
There is a function called hai_skeweed_features() that will list off the columns that are skewed.
Here is the post: https://www.spsanderson.com/steveondata/posts/rtip-2022-11-14/
#package #r #DataSet #features #skewed

Technology Tales · @technology_tales
7 followers · 81 posts · Server mstdn.socialLearning computing languages
Over the years, I have taught myself a number of computing languages with some coming in useful for professional work while others came in handy for website development and maintenance. The collection has grown to include HTML, CSS, XML, Perl, PHP and UNIX
https://technologytales.com/2021/04/11/learning-computing-languages/
#Programming #Scripting #Software #Computing #Data #DataSet #Graphs #Language #Languages #OpenSource #Programminglanguage #Python #R #SAS
#sas #r #Python #programminglanguage #OpenSource #languages #language #graphs #DataSet #Data #Computing #Software #scripting #Programming
Technology Tales · @technology_tales
13 followers · 96 posts · Server mstdn.socialLearning computing languages
Over the years, I have taught myself a number of computing languages with some coming in useful for professional work while others came in handy for website development and maintenance. The collection has grown to include HTML, CSS, XML, Perl, PHP and UNIX
https://technologytales.com/2021/04/11/learning-computing-languages/
#Programming #Scripting #Software #Computing #Data #DataSet #Graphs #Language #Languages #OpenSource #Programminglanguage #Python #R #SAS
#sas #r #Python #programminglanguage #OpenSource #languages #language #graphs #DataSet #Data #Computing #Software #scripting #Programming