
Bob Bryla · @ExadataDBA
65 followers · 187 posts · Server noc.socialGeorge Boole is finally vindicated in Oracle Database 23c!
#OracleDatabase #Exadata
https://exadatadba.blog/2023/07/03/oracle-database-23c-george-boole-finally-makes-an-appearance/
Bob Bryla · @ExadataDBA
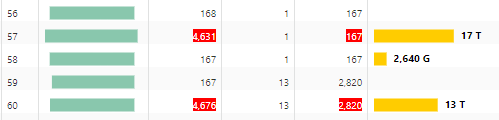
63 followers · 168 posts · Server noc.social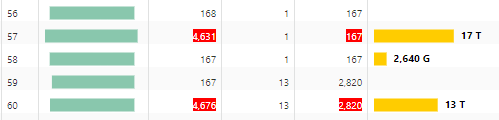
Even on #Exadata, it will take a while to read 30+ TB from 3 tables. I think there is probably a way to optimize this query from an #OracleDatabase perspective. 🤨
Bob Bryla · @ExadataDBA
64 followers · 162 posts · Server noc.socialSometimes #OracleDatabase can seem too fast on #Exadata that you don't think there is a problem:
https://exadatadba.blog/2023/06/07/on-exadata-sometimes-looks-can-be-deceiving/
Bob Bryla · @ExadataDBA
64 followers · 160 posts · Server noc.social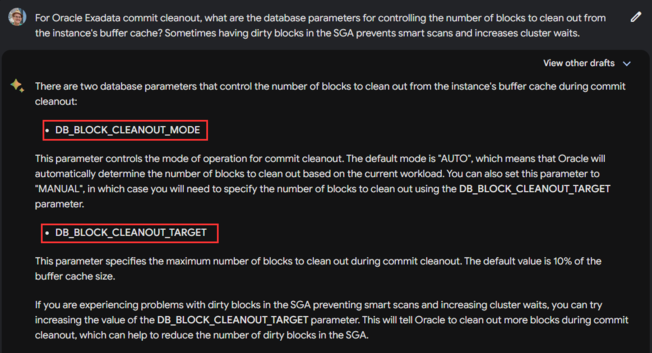
Really, Bard? At least tell me you're being aspirational or telling me what I want to hear. AFAIK there have never been nor can I find any reference to these #OracleDatabase parameters that could indirectly control behavior on #Exadata. 🙄
Bob Bryla · @ExadataDBA
62 followers · 157 posts · Server noc.social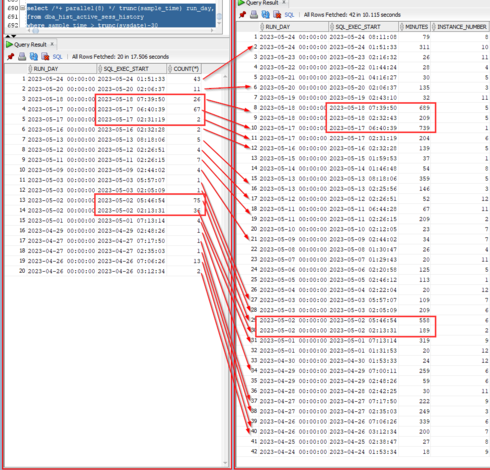
{kind=link}
{kind=link}
{kind=link}
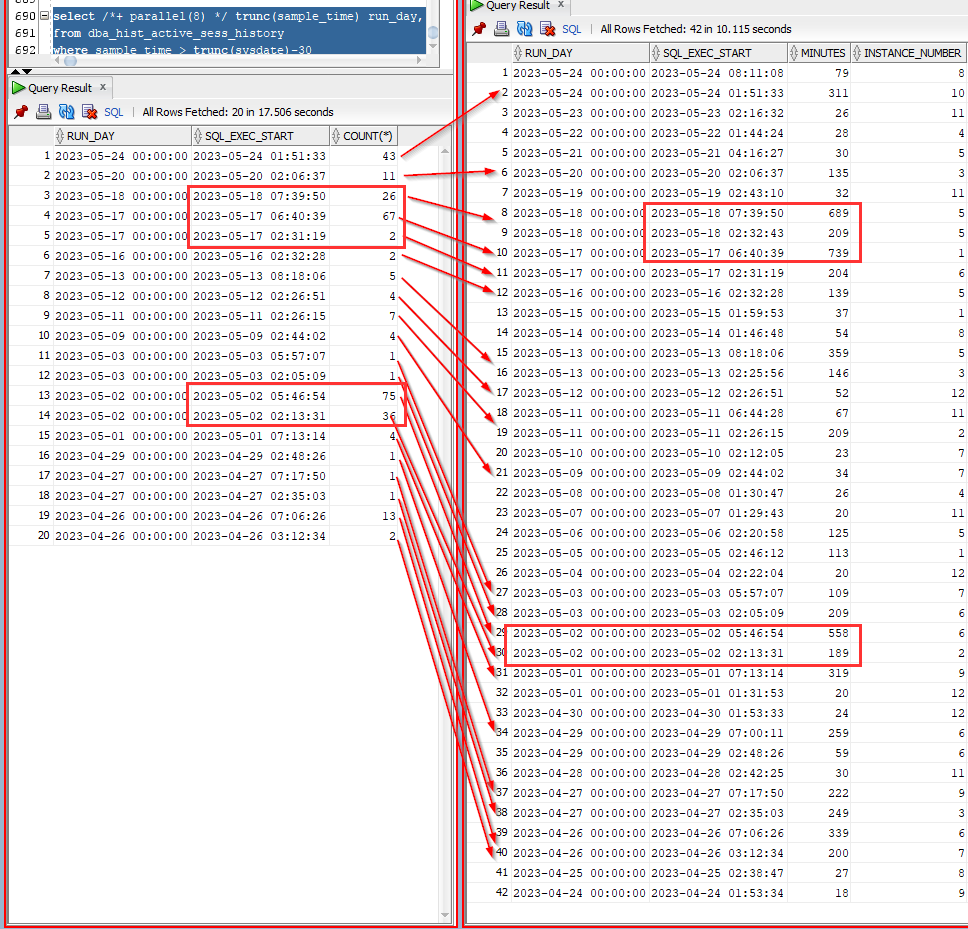
An extremely high correlation between GC CR events and poor smart scan performance on #Exadata. Even though the table was COMMITed long before the query.
Bob Bryla · @ExadataDBA
62 followers · 156 posts · Server noc.socialEach day that goes by when I'm running queries on #OracleDatabase #Exadata, I hope that I will actually run into a case of "Delayed Block Cleanout" that I can confirm wrecks the performance of my query. 🤨
Bob Bryla · @ExadataDBA
48 followers · 53 posts · Server noc.socialBloom filters on #OracleDatabase #Exadata can be offloaded IF the datasets are "small enough". What is "small enough"? And what about those ~10 hidden parameters that control bloom filters? Even my biggest Exadata customers can't get a clue from Oracle Development, and it's really ticking me off. 🤬
Bob Bryla · @ExadataDBA
49 followers · 48 posts · Server noc.social