
Benjamin Carr, Ph.D. 👨🏻💻🧬 · @BenjaminHCCarr
797 followers · 2009 posts · Server hachyderm.io#AMD Has a #GPU to Rival #Nvidia’s #H100
#MI300X is a GPU-only version of previously announced #MI300A supercomputing chip, which includes a #CPU and #GPU. The MI300A will be in El Capitan, a supercomputer coming next year to the #LosAlamos #NationalLaboratory. El Capitan is expected to surpass 2 exaflops of performance. The MI300X has 192GB of #HBM3, which Su said was 2.4 times more memory density than Nvidia’s H100. The SXM and PCIe versions of H100 have 80GB of HBM3.
https://www.hpcwire.com/2023/06/13/amd-has-a-gpu-to-rival-nvidias-h100/
#amd #gpu #nvidia #H100 #mi300x #mi300a #cpu #LosAlamos #nationallaboratory #hbm3
Benjamin Carr, Ph.D. 👨🏻💻🧬 · @BenjaminHCCarr
797 followers · 2005 posts · Server hachyderm.io
#AMD Instinct#MI300 is THE Chance to Chip into #NVIDIA #AI Share
NVIDIA is facing very long lead times for its #H100 and #A100, if you want NVIDIA for AI and have not ordered don't expect it before 2024. For a traditional #GPU, MI300 is GPU-only part. All four center tiles are GPU. With 192GB #HBM, & can simply fit more onto a single GPU than NVIDIA. #MI300A has 24 #Zen4, #CDNA3 GPU cores, and 128GB #HBM3. This is CPU deployed in the El Capitan 2+ Exaflop #supercomputer.
https://www.servethehome.com/amd-instinct-mi300-is-the-chance-to-chip-into-nvidia-ai-share/
#amd #nvidia #ai #H100 #a100 #gpu #hbm #mi300a #Zen4 #cdna3 #hbm3 #supercomputer
Benjamin Carr, Ph.D. 👨🏻💻🧬 · @BenjaminHCCarr
782 followers · 1887 posts · Server hachyderm.io
#Nvidia #DGX #GH200 stitches together 256 superchips
The DGX #H100 is an 8U system with dual Intel Xeons and eight H100 GPUs and about as many NICs. The DGX GH200, is a 24-rack cluster built on an all-Nvidia architecture. At the heart of this super-system is the #GraceHopper chip. Unveiled at March GTC in 2022, blending a 72-core Arm-compatible Grace CPU cluster and 512GB of LPDDR5X memory with an 96GB GH100 Hopper GPU die using the company's 900GBps NVLink-C2C interface.
https://www.theregister.com/2023/05/29/nvidia_dgx_gh200_nvlink/
#nvidia #dgx #gh200 #H100 #gracehopper

Ars Technica RSS feed · @arstechnicarss
2 followers · 57 posts · Server 0twitter.comNvidia and Microsoft team up to build massive AI cloud computer https://arstechnica.com/?p=1898351 #machinelearning #cloudcomputing #supercomputer #microsoft #Biz&IT #NVIDIA #azure #H100 #AI
#machinelearning #cloudcomputing #supercomputer #Microsoft #Biz #NVIDIA #azure #H100 #AI

TastingTraffic Social® · @InternationalTechNews
16 followers · 735 posts · Server tastingtraffic.net
{kind=link}
{kind=link}
{kind=link}
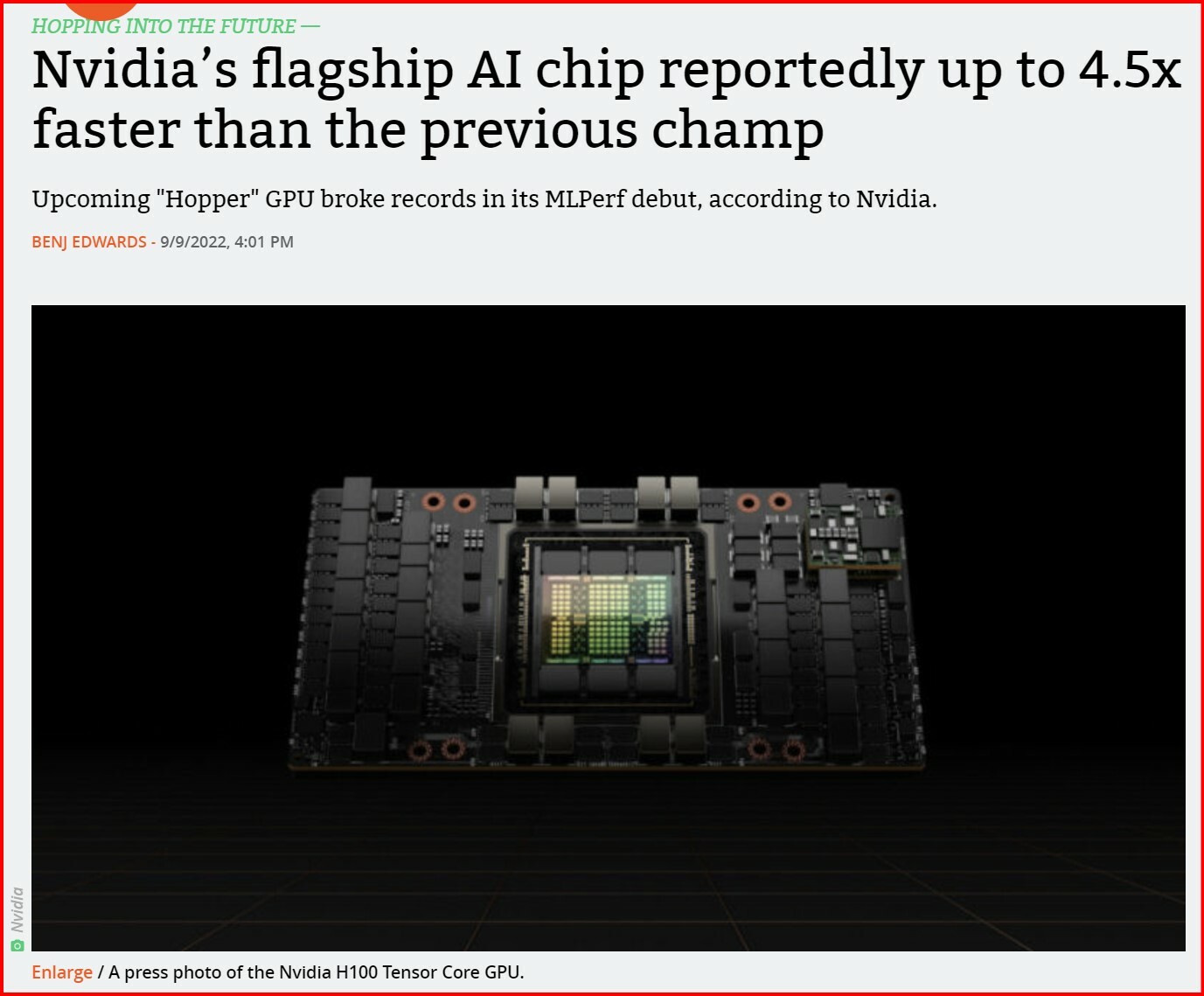
#Nvidia’s #Flagship AI #Chip reportedly up to 4.5x #Faster than the previous champ
Upcoming "#Hopper" #GPU #broke_records in its #MLPerf debut, according to Nvidia.
#Nvidia announced yesterday that its upcoming #H100 "Hopper" #Tensor_Core_GPU set new performance records during its debut in the industry-standard MLPerf benchmarks, delivering results up to 4.5 times faster than the A100, which is currently Nvidia's fastest production AI chip.
The MPerf benchmarks (technically called "#MLPerfTM Inference 2.1") measure "inference" workloads, which demonstrate how well a chip can apply a previously trained machine learning model to new data. A group of industry firms known as the MLCommons developed the MLPerf benchmarks in 2018 to deliver a standardized metric for conveying machine learning performance to potential customers.
In particular, the H100 did well in the BERT-Large benchmark, which measures natural language-processing performance using the BERT model developed by Google. Nvidia credits this particular result to the Hopper architecture's Transformer Engine, which specifically accelerates training transformer models. This means that the H100 could accelerate future natural language models similar to OpenAI's GPT-3, which can compose written works in many different styles and hold conversational chats.
Nvidia positions the H100 as a high-end data center GPU chip designed for AI and supercomputer applications such as image recognition, large language models, image synthesis, and more. Analysts expect it to replace the A100 as Nvidia's flagship data center GPU, but it is still in development. US government restrictions imposed last week on exports of the chips to China brought fears that Nvidia might not be able to deliver the H100 by the end of 2022 since part of its development is taking place there.
Nvidia clarified in a second Securities and Exchange Commission filing last week that the US government will allow continued development of the H100 in China, so the project appears back on track for now. According to Nvidia, the H100 will be available "later this year." If the success of the previous generation's A100 chip is any indication, the H100 may power a large variety of groundbreaking AI applications in the years ahead.
Disclaimer: https://tastingtraffic.net (Decentralized SOCIAL Network) and/or its owners [http://tastingtraffic.com] are not affiliates of this provider or referenced image used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#INTERNATONAL_TECH_NEWS #Nvidia #Flagship #Chip #faster #Hopper #GPU #broke_records #MLPerf #H100 #Tensor_Core_GPU #MLPerfTM