
Published papers at TMLR · @tmlrpub
564 followers · 600 posts · Server sigmoid.social
A DNN Optimizer that Improves over AdaBelief by Suppression of the Adaptive Stepsize Range
Guoqiang Zhang, Kenta Niwa, W. Bastiaan Kleijn
Action editor: Rémi Flamary.
#optimizers #ImageNet #optimizer
Published papers at TMLR · @tmlrpub
564 followers · 597 posts · Server sigmoid.social
Efficient Inference With Model Cascades
Luzian Lebovitz, Lukas Cavigelli, Michele Magno, Lorenz K Muller
Action editor: Yarin Gal.

New Submissions to TMLR · @tmlrsub
205 followers · 741 posts · Server sigmoid.social
A simple, efficient and scalable contrastive masked autoencoder for learning visual representations
#autoencoders #autoencoder #ImageNet
Published papers at TMLR · @tmlrpub
560 followers · 562 posts · Server sigmoid.social
Learned Thresholds Token Merging and Pruning for Vision Transformers
Maxim Bonnaerens, Joni Dambre
Action editor: Mathieu Salzmann.
Published papers at TMLR · @tmlrpub
553 followers · 555 posts · Server sigmoid.social
Optimizing Learning Rate Schedules for Iterative Pruning of Deep Neural Networks
Shiyu Liu, Rohan Ghosh, John Chong Min Tan, Mehul Motani
Action editor: Mingsheng Long.
#pruning #ImageNet #subnetworks
Published papers at TMLR · @tmlrpub
553 followers · 555 posts · Server sigmoid.social
Foiling Explanations in Deep Neural Networks
Snir Vitrack Tamam, Raz Lapid, Moshe Sipper
Action editor: Jakub Tomczak.
#adversarial #ImageNet #inception
New Submissions to TMLR · @tmlrsub
199 followers · 707 posts · Server sigmoid.social
Synthetic Data from Diffusion Models Improves ImageNet Classification
#ImageNet #inception #generative
Published papers at TMLR · @tmlrpub
546 followers · 527 posts · Server sigmoid.social
Contrastive Attraction and Contrastive Repulsion for Representation Learning
Huangjie Zheng, Xu Chen, Jiangchao Yao et al.
Action editor: Yanwei Fu.
#softmax #representations #ImageNet
New Submissions to TMLR · @tmlrsub
193 followers · 669 posts · Server sigmoid.social
Efficient Inference With Model Cascades
Published papers at TMLR · @tmlrpub
526 followers · 484 posts · Server sigmoid.social
Supervised Knowledge May Hurt Novel Class Discovery Performance
ZIYUN LI, Jona Otholt, Ben Dai, Di Hu, Christoph Meinel, Haojin Yang
Action editor: Vikas Sindhwani.
#supervised #labeled #ImageNet
New Submissions to TMLR · @tmlrsub
183 followers · 624 posts · Server sigmoid.social
Training Vision-Language Transformers from Captions
Published papers at TMLR · @tmlrpub
522 followers · 465 posts · Server sigmoid.social
Training with Mixed-Precision Floating-Point Assignments
Wonyeol Lee, Rahul Sharma, Alex Aiken
Action editor: Nadav Cohen.
New Submissions to TMLR · @tmlrsub
180 followers · 598 posts · Server sigmoid.social
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
#ImageNet #classification #category
New Submissions to TMLR · @tmlrsub
180 followers · 583 posts · Server sigmoid.social
Foiling Explanations in Deep Neural Networks
#adversarial #ImageNet #inception
New Submissions to TMLR · @tmlrsub
180 followers · 583 posts · Server sigmoid.social
Contrastive Attraction and Contrastive Repulsion for Representation Learning
#softmax #representations #ImageNet
New Submissions to TMLR · @tmlrsub
180 followers · 570 posts · Server sigmoid.social
Steerable Equivariant Representation Learning
#ImageNet #steerability #steerable
Published papers at TMLR · @tmlrpub
517 followers · 412 posts · Server sigmoid.social
Guillotine Regularization: Why removing layers is needed to improve generalization in Self-Superv...
Florian Bordes, Randall Balestriero, Quentin Garrido, Adrien Bardes, Pascal Vincent
Action editor: Jinwoo Shin.
#regularization #ImageNet #generalization
New Submissions to TMLR · @tmlrsub
175 followers · 526 posts · Server sigmoid.social
MixTrain: Accelerating DNN Training via Input Mixing

JMLR · @jmlr
657 followers · 212 posts · Server sigmoid.social
'Decentralized Learning: Theoretical Optimality and Practical Improvements', by Yucheng Lu, Christopher De Sa.
http://jmlr.org/papers/v24/22-0044.html
#imagenet #benchmarks #sgd
New Submissions to TMLR · @tmlrsub
172 followers · 514 posts · Server sigmoid.social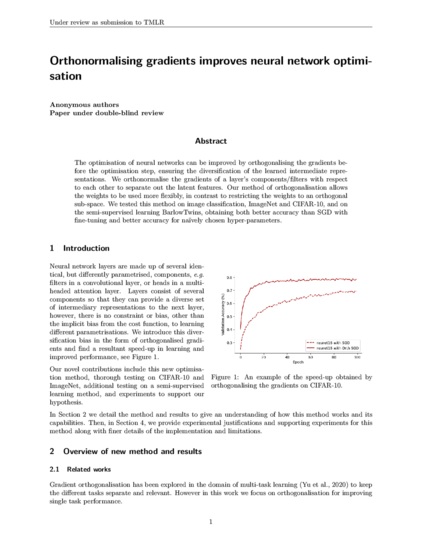
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
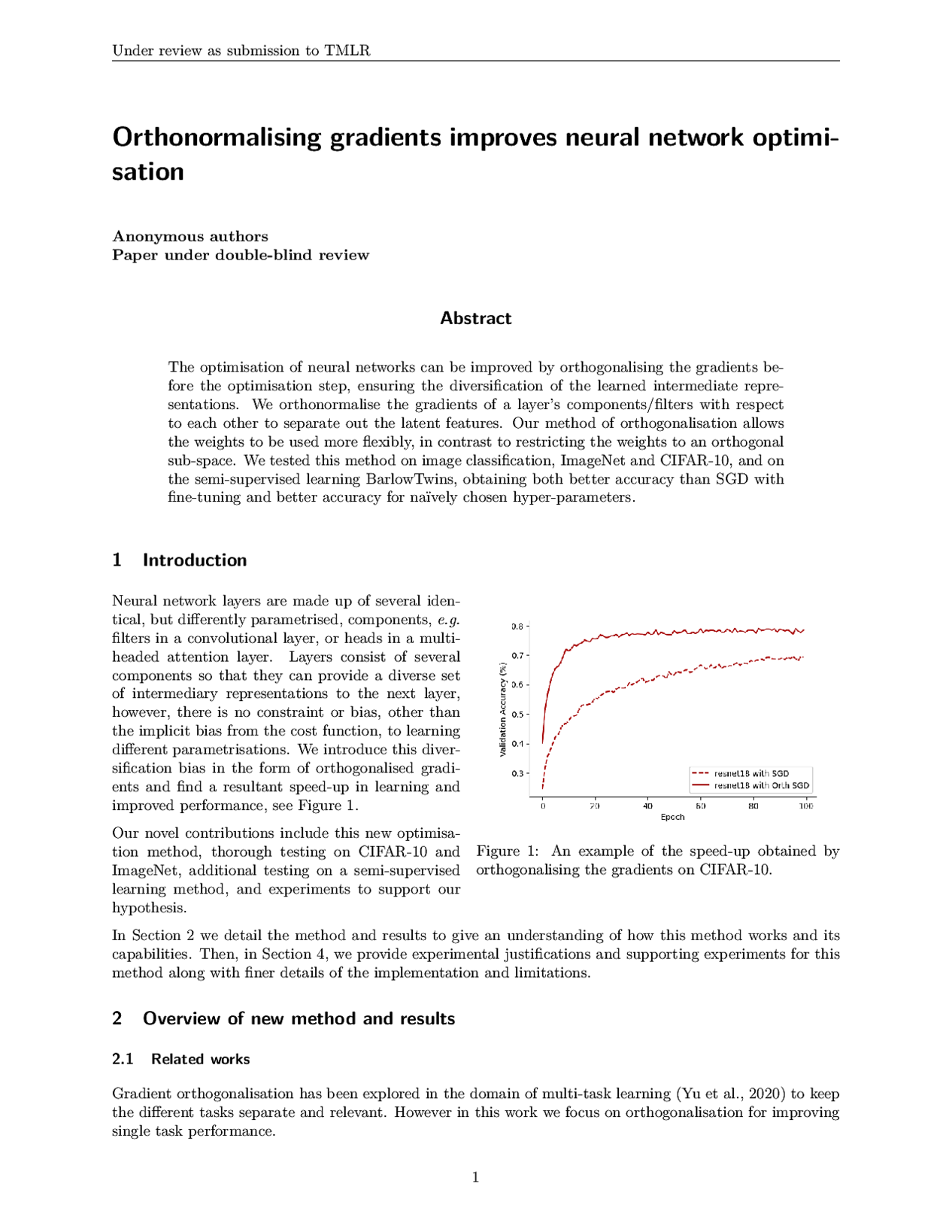
Orthonormalising gradients improves neural network optimisation
#gradients #ImageNet #orthogonalising