
mnl mnl mnl mnl mnl · @mnl
853 followers · 1016 posts · Server hachyderm.ioWrote (let gpt write) a tiny tool that scans my repos for prompt generators and allows me to quickly generate custom prompts for new apps. For example “api docs for x, 3 example files, 2 doc pages”. Really useful for 50 lines of code.

jdelahanty · @science_is_hard
86 followers · 93 posts · Server social.coop
Oh geeze the #LLMs are going to be digesting their own text in publications even sooner.

Tim Kellogg · @kellogh
943 followers · 3608 posts · Server hachyderm.io
Giorgio Robino · @solyarisoftware
62 followers · 79 posts · Server sigmoid.social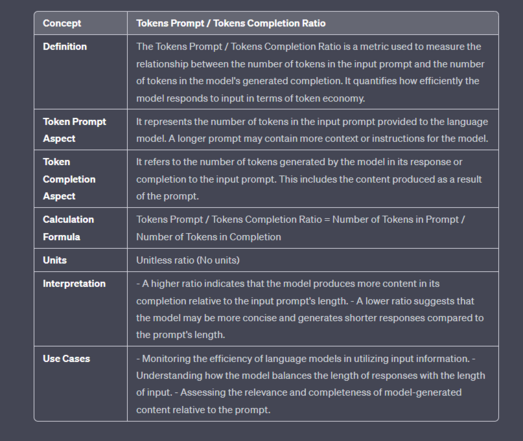
Question for #LLMs prompt engineers (anyone):
What are the most important metrics for measuring LLM completion?
I start with some basics "system" variables:
1. Latency (or response time)
measures the elapsed time of a completion
2. Tokens Throughput = tokens/latency
3. Prompt/Completion tokens ratio
4. there are many more cross ratios maybe useful, involving LLM settings (max_tokens, temperature, etc.)
The final goal is to define some list of common vars to evaluate foundational LLMs.

Osma Suominen · @osma
300 followers · 971 posts · Server sigmoid.socialBerlin, here I come!
It's now four years since the last in-person #SWIB conference. #swib23 may well be the last one, so let's try to cherish the opportunity to meet in one place!
I will be an instructor for the #Annif tutorial on Monday, moderate a session & hopefully give a Lightning talk on Tuesday. Looking forward to great talks & ofc dinner and coffee breaks are often the most interesting!
Feel free to stop by if you want to talk about #Annif, #Skosmos, #LLMs, #metadata, #Fennica etc.
#swib #swib23 #annif #skosmos #LLMs #metadata #fennica

Ben Waber · @bwaber
704 followers · 2741 posts · Server hci.socialNext was an amazing pair of talks by @armedchile (an ingenious method for combining high and low resource language data to build #LLMs that significantly improves translation performance) and Orevaoghene Ahia (subword tokenization effects on LLM costs/performance in different languages) at #Indaba2023. I'll be thinking about both talks for a long time - they have profound implications for the design of #GenerativeAI tech and business models. Highly recommend https://www.youtube.com/watch?v=EVi9qB_1Ccw (3/11) #AI
#LLMs #indaba2023 #generativeAI #ai
Tim Kellogg · @kellogh
943 followers · 3597 posts · Server hachyderm.ioAnother one — why not just use gzip? This paper uses tiny compression algorithms that run great on even embedded devices, and the performance comes close to where #LLMs are at. That would be a massive game changer from the current state https://www.hendrik-erz.de/post/why-gzip-just-beat-a-large-language-model
Tim Kellogg · @kellogh
943 followers · 3596 posts · Server hachyderm.ioNow that #NeuralNetworks have had repeated big successes over the last 15 years, we are starting to look for better ways to implement them. Some new ones for me:
#Groq notes that NNs are bandwidth-bound from memory to GPU. They built a LPU specifically designed for #LLMs
https://groq.com/
A wild one — exchange the silicon for moving parts, good old Newtonian physics. Dramatic drop in power utilization and maps to most NN architectures (h/t @FMarquardtGroup)
mnl mnl mnl mnl mnl · @mnl
849 followers · 964 posts · Server hachyderm.ioFurthermore, #llms are absolute monsters to slice and refactor legacy code, thus improving the longevity of already long-living software that might otherwise be painfully phased out.
2/
mnl mnl mnl mnl mnl · @mnl
849 followers · 963 posts · Server hachyderm.iosummarizing a train of thought from a conversation with @promovicz yesterday, which helped me formulate some of my ideas.
I think #llms allow us to write *less code*. Because they make it easy to generate the boilerplate that ensures longevity and sustainability of software projects: documentation, clean commits, unit tests, tooling, they allow projects to actually live on.
1/
mnl mnl mnl mnl mnl · @mnl
848 followers · 938 posts · Server hachyderm.ioI don’t think mathematica is a Great target language, nor the does prompting in the Mathematica chat enabled seem very good, and it churns through tokens like the king of Spain. My third attempt to get something going yesterday was just as much of a mess (trying to get hilbert curves computed and displayed with @defn ) as my first sessions (doing some geospatial computation / dataset computation).
Not fun.

Nicole Hennig · @nic221
353 followers · 1792 posts · Server techhub.social
Anthropic \ Introducing Claude Pro https://www.anthropic.com/index/claude-pro ($20/mo alternative to ChatGPT Plus) #AI #LLMs #Claude

Wendy M. Grossman · @wendyg
1284 followers · 713 posts · Server mastodon.xyzThis week's net.wars, "Small data", summarizes the talk I gave with Jon Crowcroft at this year's #gikii, arguing that large language models will ultimately prove to be a distraction: https://netwars.pelicancrossing.net/2023/09/08/small-data/ #LLMs #AI #NetWars
Tim Kellogg · @kellogh
942 followers · 3559 posts · Server hachyderm.io
mnl mnl mnl mnl mnl · @mnl
847 followers · 901 posts · Server hachyderm.ioI literally have thousands conversations like these now, from designing video game physics to transaction protocols to monad design patterns for music sequencing to numerous DSLs for everything that strikes my fancy (zine layout? comic book storyboard generation? worldbuilding CMS?).
mnl mnl mnl mnl mnl · @mnl
848 followers · 880 posts · Server hachyderm.iochatgpt trick when applied to programming, don't ask "does X do Y" or "is X Y", instead ask for "give me a test program to show that X does Y".
So for example, if you wonder about the size of a struct in memory, ask it to write the program to compute or measure struct sizes.
always think meta.

Daniel Hoelzgen · @dhoelzgen
30 followers · 7 posts · Server ruhr.socialFor a medical & caretaking project, I experimented with combining symbolic #logic with #LLMs to mitigate their tendency to nondeterministic behavior and #hallucinations. Still, it leaves a lot of work to be done, but it's a promising approach for situations requiring higher reliability.
#logic #LLMs #hallucinations #ai #artificialintelligence #llm #chatgpt

Jeroen SZ 🦣 · @JeroenSH
254 followers · 222 posts · Server lingo.lolArtificial Language Models Teach Us Nothing About #Language | Psychology Today

dragfyre · @dragfyre
839 followers · 4858 posts · Server mastodon.sandwich.net
{kind=link}
{kind=link}
I don't know what I expected. #LLMs #AI #SALAMI #StephenHawking
#LLMs #ai #salami #stephenhawking
Nicole Hennig · @nic221
352 followers · 1778 posts · Server techhub.socialTimeline History of Large Language Models - Voicebot.ai https://voicebot.ai/large-language-models-history-timeline/ (nice!) #AI #LLMs #history