
Saad Mahamood · @Saad
22 followers · 126 posts · Server sigmoid.social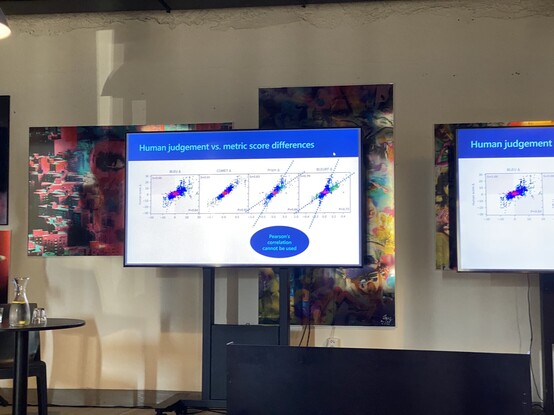
At the PraticalD2T workshop today at INLG 2023. Some really interesting findings looking correlation between automatic and human evaluations and accuracy.

Maria Keet · @keet
59 followers · 124 posts · Server fediscience.orgOur CoSMo content selection modelling language in the Abstract Wikipedia newsletter of today: https://meta.m.wikimedia.org/wiki/Abstract_Wikipedia/Updates/2023-08-31 #AbstractWikipedia #modelling #NLG
#NLG #modelling #abstractwikipedia

SIGGEN · @siggen_acl
10 followers · 3 posts · Server fediscience.orgHello Fediverse! Here's an #introduction to SIGGEN, the ACL special interest group for #NaturalLanguageGeneration
Beginning with the 1st International Workshop on #NLG in 1990, SIGGEN has been organising events for the discussion, dissemination and archiving of research topics and results in the field of #TextGeneration (where a text doesn't necessarily have to be written, of course).
The name is usually pronounced [ˈsɪɡ.ʤɛn].
#textgeneration #NLG #NaturalLanguageGeneration #introduction

Michal Měchura · @lexiconista
94 followers · 352 posts · Server mastodon.ieHow Apple handles agreement and gender in localized UIs: https://developer.apple.com/videos/play/wwdc2023/10153/
Trivial if you’ve been around the block with #NLG and #GrammaticalFramework, but good to see major software vendor caring about *grammar*!
Fav quote: "Grammatically correct food just tastes better."

New Submissions to TMLR · @tmlrsub
171 followers · 503 posts · Server sigmoid.social
Advantage Actor-Critic Training Framework Leveraging Lookahead Rewards for Automatic Question Generation

Benjamin Han · @BenjaminHan
328 followers · 708 posts · Server sigmoid.social6/
Another note is that the paper discussed earlier on learnability of ICL (see https://sigmoid.social/@BenjaminHan/110086575607238350) seems to give theoretical support that random label flipping does not matter (Theorem 1). Can it explain the scaling phenomenon?
#paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 708 posts · Server sigmoid.social6/
nother note is that the paper discussed earlier on learnability of ICL (see https://sigmoid.social/@BenjaminHan/110086575607238350) seems to give theoretical support that random label flipping does not matter (Theorem 1). Can it explain the scaling phenomenon?
#paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 707 posts · Server sigmoid.social5/
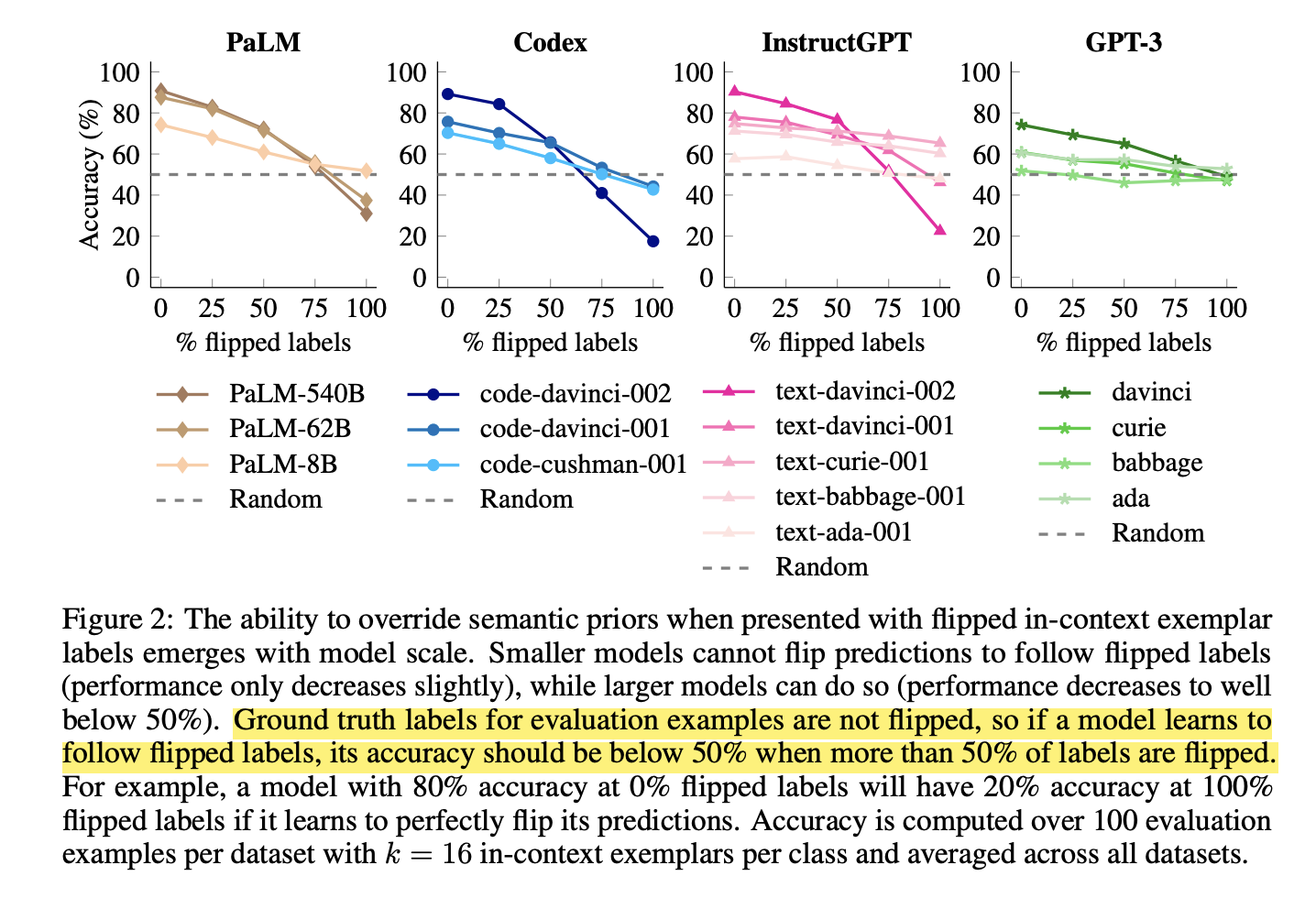
On the surface, these two papers seem to be at odds. While Paper 1 shows that labels do not matter much in ICL, Paper 2 shows they do, but only for larger models (Sec 7). Curiously for #GPT3 covered by both papers, the scaling effect did not show up in the label-flipping experiments (screenshot 5). For this reason, the authors (Paper 2) "consider all GPT-3 models to be “small” models because they all behave similarly to each other in this way." ;-)
#gpt3 #paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 706 posts · Server sigmoid.social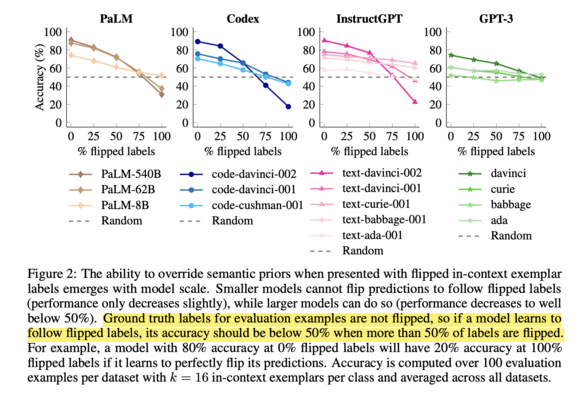
4/
Paper 2 demonstrates that the ability to overcome semantic priors via demonstrations may be an emerging phenomenon with model scale. They show that when labels are flipped in the demonstrations, larger LLMs follow more closely than the smaller ones (screenshot 5), and when labels are swapped with semantically unrelated ones, smaller models suffer more in accuracy (screenshot 6).
#paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 706 posts · Server sigmoid.social4/
aper 2 demonstrates that the ability to overcome semantic priors via demonstrations may be an emerging phenomenon with model scale. They show that when labels are flipped in the demonstrations, larger LLMs follow more closely than the smaller ones (screenshot 5), and when labels are swapped with semantically unrelated ones, smaller models suffer more in accuracy (screenshot 6).
#paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 705 posts · Server sigmoid.social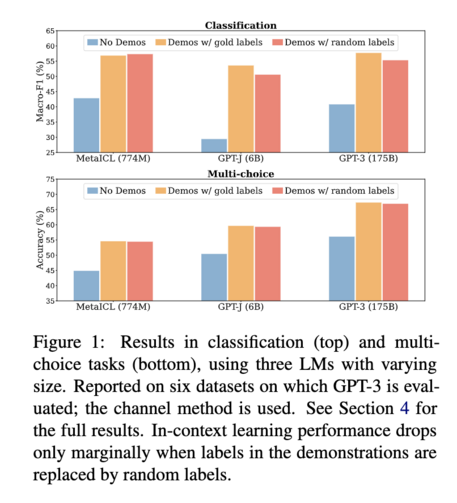
3/
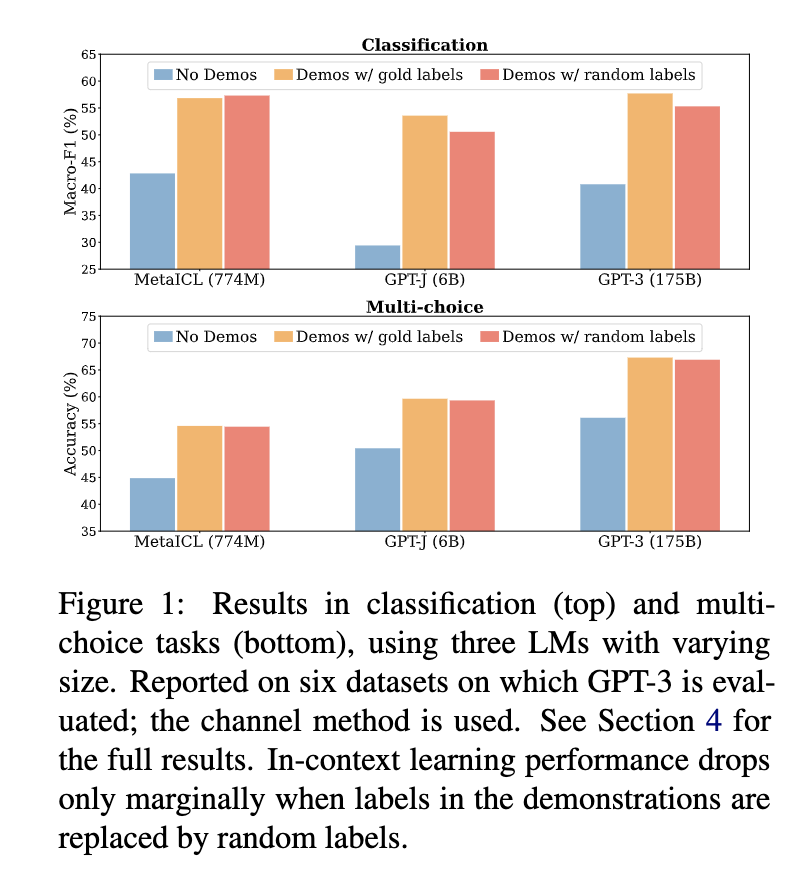
Paper 1 shows that the labels in these demonstrations do *not* matter much. Replacing them with random labels works almost as well as long as there are demonstrations (screenshot 1)! In fact, the other aspects of demonstrations such as the label space (screenshot 2), the distribution of the input text (screenshot 3), and the overall demonstration format (screenshot 4), actually matter more!
#paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 704 posts · Server sigmoid.social2/
Paper 1:
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? http://arxiv.org/abs/2202.12837
Paper 2:
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. 2023. Larger language models do in-context learning differently. http://arxiv.org/abs/2303.03846
#paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 703 posts · Server sigmoid.social1/
In-Context Learning (ICL) is a superpower #LLMs have that allows them to learn a new task from inference-time demonstrations without the need of costly retraining. But can LLMs really overcome semantic priors learned from the pretraining and adapt to novel input-label mappings through just demonstrations? Two recent papers shed light on this for us:
#LLMs #paper #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
328 followers · 703 posts · Server sigmoid.socialIn-Context Learning (ICL) is a superpower #LLMs have that allows them to learn a new task from inference-time demonstrations without the need of costly retraining. But can LLMs really overcome semantic priors learned from the pretraining and adapt to novel input-label mappings through just demonstrations? Two recent papers shed light on this for us:
#LLMs #paper #nlp #nlproc #NLG #generativeAI

Lara J. Martin · @laramar
428 followers · 109 posts · Server sigmoid.socialSeeing the latest wave of arXiv papers, it looks like #ChatGPT / #GPT4 / etc. are being used by all types of AI researchers, and NLP researchers have all become interested in generation. 😂
Welcome, all, to the complicated land of #NLG. We need all the help we can get evaluating these models!
Benjamin Han · @BenjaminHan
325 followers · 691 posts · Server sigmoid.social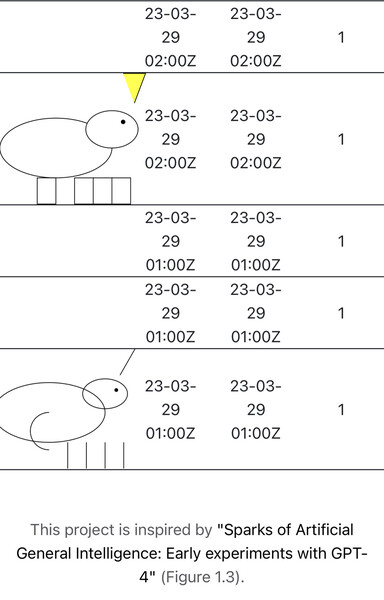
If #GPT4 is a Turing Machine, it’s a very nondeterministic one: Yuntian Deng uses it to draw a unicorn every hour with T=0 at https://openaiwatch.com/.
#gpt4 #nlp #nlproc #NLG #generativeAI
Benjamin Han · @BenjaminHan
325 followers · 686 posts · Server sigmoid.social

Victor Paléologue · @palaio
48 followers · 136 posts · Server fediscience.org
Benjamin Han · @BenjaminHan
315 followers · 677 posts · Server sigmoid.social
4/
Paper 2 shows ICL is PAC learnable (see screenshot 4 & 5 for definition and the final theorem). The intuition is that #LLM undergoing pretraining already learned a mixture of latent tasks, and prompts (demonstrations) serve as to identify the task at hand rather than "learning" it. The proof requires 4 assumptions, with the most important one being that pretraining distributions are efficiently learnable (screenshot 6).
#llm #deeplearning #machinelearning #paper #nlp #nlproc #NLG
Benjamin Han · @BenjaminHan
315 followers · 676 posts · Server sigmoid.social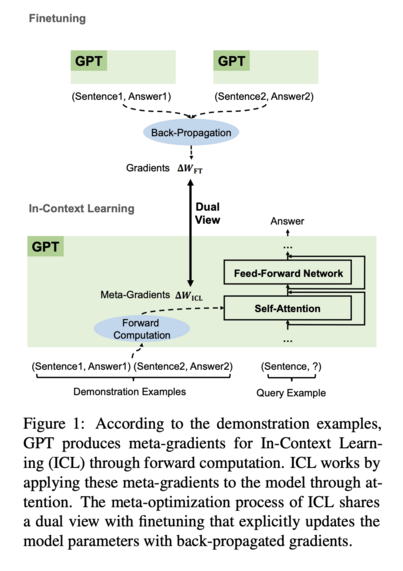
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3/
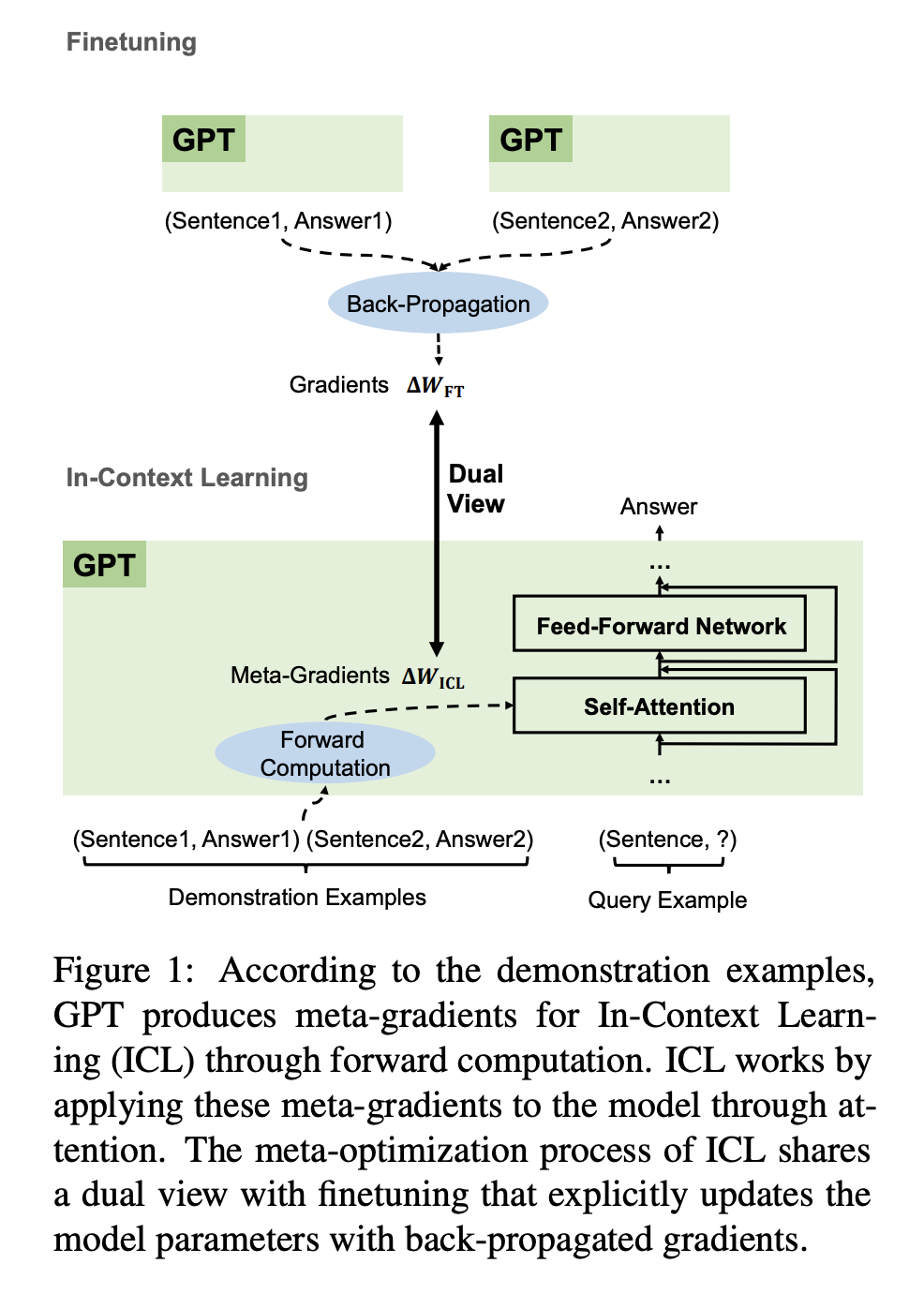
Paper 1 shows ICL works because the attention mechanism is secretly performing gradient descent (screenshot 1 and 2)! Although the LM is frozen, including the W_Q, W_K and W_V projection matrices, attention on the demonstration tokens are not (screenshot 3).
#deeplearning #machinelearning #paper #nlp #nlproc #NLG