
Francesco Tisiot · @ftisiot
302 followers · 127 posts · Server hachyderm.io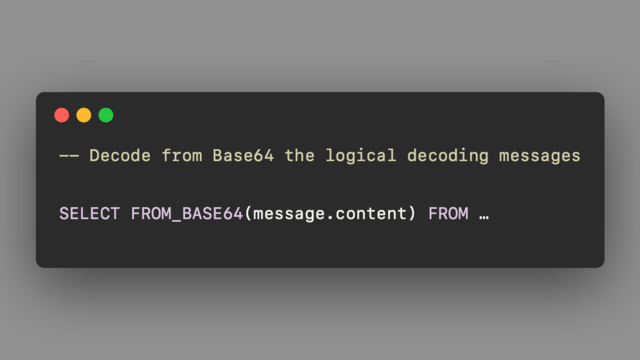
Was experimenting today with #Debezium and the #PostgreSQL logical decoding messages.
The message is encoded in #ApacheKafka based on the binary.handling.mode parameter, with base64 being the default
Glad that #ApacheFlink has a native SQL function to decode from base64: FROM_BASE64
More info:
- Debezium logical decoding messages https://debezium.io/documentation/reference/stable/connectors/postgresql.html#postgresql-message-events
- ApacheFlink FROM_BASE64 function https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/functions/systemfunctions/#string-functions
#debezium #postgresql #ApacheKafka #apacheFlink
Francesco Tisiot · @ftisiot
302 followers · 127 posts · Server hachyderm.io
Need to build/parse #JSON payloads using #SQL? Check #ApacheFlink functions!
- JSON_BUILD_OBJECT to build an object based on a series of keys and values
- JSON_ARRAYAGG to aggregate values into an array
- JSON_VALUE to retrieve a single field from a JSON object
- JSON_QUERY to retrieve multiple nested records from a JSON object
Francesco Tisiot · @ftisiot
300 followers · 121 posts · Server hachyderm.io
Test your #ApacheFlink SQL with Docker!
https://github.com/Aiven-Open/sql-cli-for-apache-flink-docker
Francesco Tisiot · @ftisiot
300 followers · 119 posts · Server hachyderm.io
SQL Client for #ApacheFlink on Docker now available for Apache Flink 1.17.1!
Thanks to Sergey Nuyanzin for the speedy review and the help in fixing some problems!
https://github.com/Aiven-Open/sql-cli-for-apache-flink-docker/releases/tag/1.17.1

InfoQ · @infoq
648 followers · 267 posts · Server techhub.social
#CaseStudy – Instacart made the platform easier to use & reduced their operational / infrastructure costs.
How? Building an #ApacheFlink self-serve platform on #Kubernetes at scale.
Check out #InfoQ to learn how they did it: https://bit.ly/44l5tGP
#casestudy #apacheFlink #kubernetes #infoq #softwarearchitecture

Danica Fine · @thedanicafine
143 followers · 92 posts · Server data-folks.masto.hostCurious to hear from folks, besides #apacheKafka, what are your favorite #streaming technologies? 🤔
#streamingdata #eventstreaming #streamingtechnology #apacheFlink #apacheSpark #apachePulsar
#apachekafka #Streaming #StreamingData #eventstreaming #streamingtechnology #apacheFlink #ApacheSpark #apachepulsar

Tabular · @tabular
68 followers · 131 posts · Server data-folks.masto.hostThe end of May brings the May edition of the #ApacheIceberg Community News. There is a lot of great content from the community once again with the release of Iceberg 1.3, and significant updates to PyIceberg, with the 0.4.0 release right around the corner. Important support was added for #ApacheSpark version 3.4 and #ApacheFlink version 1.17. There is also significant news from the vendor community and great blog posts from folks like Anuj Syal and Marin Aglić Čuvić.
https://tabular.io/blog/iceberg-202305/
#apacheiceberg #ApacheSpark #apacheFlink
Francesco Tisiot · @ftisiot
285 followers · 107 posts · Server hachyderm.io

Tibs · @much_of_a
84 followers · 204 posts · Server hachyderm.io@ftisiot I'm obviously biassed, because I work at Aiven and @ftisiot is a colleague, but I loved this, and I do love the data dances one can do with #ApacheKafka and #ApacheFlink
Francesco Tisiot · @ftisiot
278 followers · 68 posts · Server hachyderm.io
Need to convert #ApacheKafka topics from JSON to AVRO (bonus points for using #SchemaRegistry)?
Check how you can do it with #ApacheFlink
#ApacheKafka #schemaregistry #apacheFlink
Francesco Tisiot · @ftisiot
278 followers · 67 posts · Server hachyderm.ioNeed to covert #ApacheKafka topics from JSON to AVRO (bonus points for using #SchemaRegistry)?
Check how you can do it with #ApacheFlink
#ApacheKafka #schemaregistry #apacheFlink
Tabular · @tabular
62 followers · 91 posts · Server data-folks.masto.hostThe @ApacheIceberg newsletter for March is here. Lots of big news with version 1.2, #ApacheSpark, #ApacheFlink and vendor support.
https://tabular.substack.com/p/iceberg-newsletter-mar-2023?sd=pf
Francesco Tisiot · @ftisiot
277 followers · 57 posts · Server hachyderm.io
New blog is out!
One of #ApacheKafka’s mantra is that it preserves message ordering, but, is it true?
Check out the edge cases and how to solve them (also using #ApacheFlink)
#ApacheKafka #apacheFlink #datastreaming

austin ce · @austince
27 followers · 28 posts · Server hachyderm.io
RT @snntrable
📢The CfP for Current22 is closing soon. Me, @alpinegizmo and the rest of program committee are looking forward to more last minute, #ApacheFlink-related submissions.
Happy to give feedback on an abstract upfront via DM.

Danica Fine · @thedanicafine
133 followers · 79 posts · Server data-folks.masto.host#Current23 is the next generation of #KafkaSummit, so expect some #apacheKafka talks. But there's room for everyone! #apacheDruid, #apacheFlink, #ETL, #dataMesh, #machineLearning, #IoT, #databases...
We have room for talks on the unique #devops challenges of monitoring and managing any of these systems; talks on #sociotechnical impact of rearchitecting your business for streaming; #streaming in academia; and just plain fun and geeky sessions.
The list goes on and on!
#current23 #kafkasummit #apachekafka #apachedruid #apacheFlink #etl #datamesh #machinelearning #iot #databases #devops #sociotechnical #Streaming

Francesco Tisiot · @ftisiot
276 followers · 52 posts · Server hachyderm.ioHad the pleasure of being interviewed by @alex_casalboni for the @awscloud podcast in Italian.
Easy part: share my passion about #datastreaming with #ApacheKafka and #ApacheFlink
Complex part: talk about work in Italian after 15 years.
#datastreaming #ApacheKafka #apacheFlink
Francesco Tisiot · @ftisiot
274 followers · 49 posts · Server hachyderm.ioFrom 0 to a complete #streaming #datapipeline in ~12 minutes with @aiven_io for #ApacheFlink!
Check it out!
#Streaming #datapipeline #apacheFlink
InfoQ · @infoq
497 followers · 93 posts · Server techhub.social
You can then use #LogicalDecoding - #Postgres’ change data capture capability - to retrieve the messages from write-ahead log (WAL), process them, and relay them to external consumers.
In this #InfoQ article, Gunnar Morling explores how to take advantage of this feature for implementing three different use cases:
✅ Propagating data between microservices via the #OutboxPattern
✅ #ApplicationLogging
✅ Enriching #AuditLogs with metadata
Learn more: http://bit.ly/3ZiMZnH
#logicaldecoding #postgres #infoq #outboxpattern #applicationlogging #auditlogs #debezium #apacheFlink #microservices
Francesco Tisiot · @ftisiot
271 followers · 34 posts · Server hachyderm.ioIt's incredible to see how a product is born and help shaping it.
After more than a decade in consulting, I joined @aiven_io a couple years ago and got to experience how a new product like Aiven for #ApacheFlink is defined, developed and taken to market.
🧵
Francesco Tisiot · @ftisiot
270 followers · 32 posts · Server hachyderm.io
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Today, 4PM CET, come and learn about #streamprocessing, #ApacheFlink and how you can start creating streaming data pipelines in minutes with @aiven_io
https://landing.aiven.io/webinar/apache-flink-dev-experience/
#streamprocessing #apacheFlink