
FelixCLC (16 weeks of 🐌 HR) · @fclc
502 followers · 1935 posts · Server mast.hpc.social
Well shit: https://www.phoronix.com/news/Linux-6.6-x86-microcode
Looks to me like this may screw over those of use relying on disabling kernel MC (fallsback to bios MC) for #AVX512 on AlderLake
Need to look deeper and ping some folks
FelixCLC (still waiting on HR) · @fclc
489 followers · 1780 posts · Server mast.hpc.socialSomething doesn't fit in the register article covering AVX10.
An #Intel fellow comments that AVX10 requires 256 bit or larger implementations, yet there's an *explicit* carve out in the spec for 128 bit implementations, & that carve out means that you *must* plan for AVX10.N/128, instead of having a true baseline of AVX10.N/256
the specific passage is "[... ] 256 bit instructions will be the minimum width required by the AVX10 instruction set."
https://www.theregister.com/2023/08/15/avx10_intel_interviews/
#HPC #AVX512 #avx10

Linh Pham · @qlp
499 followers · 2801 posts · Server linh.socialDouble yikes in CPU vulnerabilities! Both articles are from #ServeTheHome
#Intel DOWNFALL Ultra-Scary #AVX2 and #AVX512 Side channel Attack Discovered
New Inception Vulnerability Impacts ALL #AMD Zen CPUs Yikes
https://www.servethehome.com/new-inception-vulnerability-impacts-all-amd-zen-cpus-yikes-phantom/
#servethehome #intel #avx2 #avx512 #amd #security

Benjamin Carr, Ph.D. 👨🏻💻🧬 · @BenjaminHCCarr
967 followers · 2482 posts · Server hachyderm.io
Intel #AVX10 is a new #ISA that includes "all the richness" of #AVX512 and additional features/capabilities while being able to work for both P/E cores. Intel says AVX10 will be "the vector ISA of choice" moving forward.Very exciting from hardware perspective with Intel's #opensource track record around new ISA support it means we'll likely start seeing software enablement preparations begin soon so that everything is upstream and ready by time supported processors ship.
https://www.phoronix.com/news/Intel-AVX10
#avx10 #isa #avx512 #opensource

Jason Pester (GameDev) · @jay
335 followers · 536 posts · Server mastodon.gamedev.place💡 Interesting news... Intel AVX-512 becomes AVX10
I remember a year or two ago, Pixar had worked with Intel to take advantage of AVX-512 in its XPU tech, but then Intel seemed to limit AVX-512 support to only a few of its CPUs. AVX10 seems like good news 👍
Intel Is Making Big Changes To The x86 ISA With APX And AVX10 Extensions
https://hothardware.com/news/intel-apx-and-avx10-extensions
#HotHardware #Intel #AVX512 #AVX10 #CPU #Vector #Tensor #Math #Pixar #XPU #CGI #ComputerGraphics #3D #Rendering #GameDev #DCC #AI #ML
#hothardware #intel #avx512 #avx10 #cpu #vector #Tensor #math #pixar #xpu #cgi #computergraphics #3d #rendering #gamedev #dcc #ai #ml

Qiita - 人気の記事 · @qiita
23 followers · 764 posts · Server rss-mstdn.studiofreesia.com
Felix LeClair (waiting on HR) · @fclc
473 followers · 1625 posts · Server mast.hpc.social@enp1s0 Specifically this would be using AVX512IFMA, which uses a 52 bit signed integer borrowed from the FP64 SIMD unit that internally accumulates to int104.
Based off the paper, I think this means we can 2 cycle over what Tsuki did with Alg3/4 and exceed whats needed to compete with cursed 2xfp64 setups.
Also relevant is that next gen Sierra Forest, Grand Ridge, Arrow Lake, Lunar Lake are all getting AVX-IFMA (a weaker, but usable version of the AVX512IFMA extension)

Hanno Rein · @hannorein
445 followers · 481 posts · Server botsin.space
The code is of course freely available in the REBOUND package (https://github.com/hannorein/rebound). To use the new fast WHFast512 integrator you need a CPU with #AVX512 instructions. If you don't have one, you should at least check out the paper to see what we do. You'll get rewarded with some fancy #latex #tikz illustrations of the algorithm!
Hanno Rein · @hannorein
441 followers · 470 posts · Server botsin.space🚨 New paper!
We re-implement the symplectic WHFast integrator for planetary systems using #AVX512 instructions. We get an almost 5x speedup for a typical integration of the Solar system.
This is a big deal because no matter how much money you spend buying a cluster or GPUs, you just cannot accelerate small N-body integrations. They are inherently sequential. But now a 5 GYr simulation that used to take a week to finish only takes 1.4 days.
Felix LeClair(received offers) · @fclc
411 followers · 1322 posts · Server mast.hpc.socialThe feature I miss the most from Twitter on Mastodon is quote tweets, explicitly of my own for the use case of related but divergent technical threads.
Working on the #GPGPU && #AVX512 accelerated build of #PETSc to enable faster execution of #OpenFOAM as of now and all the relevant threads would have to be independent threads and hard to cross reference as new threads/tangents pop up.
#gpgpu #avx512 #petsc #openfoam

Phoronix · @phoronix
2759 followers · 2502 posts · Server noc.social
#GCC @gnutools Lands #AVX512 Fully-Masked Vectorization
https://www.phoronix.com/news/GCC-AVX-512-Fully-Masked-Vector
Original tweet : https://twitter.com/phoronix/status/1670741762535563264
Felix LeClair(received offers) · @fclc
406 followers · 1277 posts · Server mast.hpc.socialBit of a meme, but this is a little like "Aurora/Sunspot" at home.
Single node with the host CPU being Goldencove #AVX512 (same as SPR) and using an Intel GPU (specifically Arc A770) and reading off of flash.
Felix LeClair(received offers) · @fclc
405 followers · 1273 posts · Server mast.hpc.socialSanity check, but looks to me like LLVM (and by extension ICX) are slightly borked in this context?
Code is a version of the intel AMX examples

Felix LeClair (Wants a job😊) · @fclc
379 followers · 866 posts · Server mast.hpc.social#AVX512 extension request: IFMA-52 but lower precision integers.
IFMA-52 is nice because of it's high intermediate precision as well as great throughput (but high latency). I suspect 52 is convenient because of the FP64 FMA unit.
Perhaps an FP32 based IFMA-22 could be doable?
#avx512 #intel #hpc #ai #x86 #yetanotherisaextension

Phoronix · @phoronix
2118 followers · 1656 posts · Server noc.social
.@IntelSoftware @IntelDevTools Releases x86-simd-sort v1.0 Library For High Performance #AVX512 Sorting
-- This is the AVX-512 code that a few weeks back was integrated into #Python #Numpy for 10~17x speed-ups for this quicksort implementation.
https://www.phoronix.com/news/x86-simd-sort-1.0
Original tweet : https://twitter.com/phoronix/status/1633250284825636864
Felix LeClair (Wants a job😊) · @fclc
365 followers · 774 posts · Server mast.hpc.socialIf someone wants to learn assembly using the most up to date ISA's on real hardware that they own, what's actually available for a reasonable cost? Looking at x86, Arm and RISC-V
Vectors ISA: AVX512, SVE2, RISC-V V
Matrix ISA: AMX, SME, RISC-V M
x86_64:
#AVX512 You're in relatively good shape. IceLake is a bargain, as is Tigerlake. Zen4 is pricier, but still accessible
#AMX As of now, it's "SoonTM", mainly depending on what boards will cost for SPR-W. Chip, board and Ram, hopefully sub 1200
Felix LeClair (Wants a job😊) · @fclc
363 followers · 767 posts · Server mast.hpc.social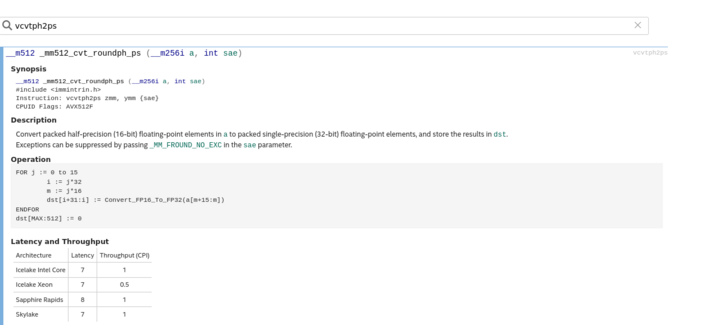
Mixed precision #BLAS things:
#AVX512 foundation gave us conversion instruction for fp16->fp32->fp16 instructions.
Overtime, these instructions got faster and faster. That's great!
From SkylakeX to ICL, we went from Latency7, CPI 1 to Latency7 CPI 0.5!
Great.
But with SPR having dedicated FP16 math extensions, the importance of datatype conversion was "downgraded"
from 7 and 0.5 to 8 and 1
Scalable Analyses · @scalable
1 followers · 25 posts · Server fosstodon.org
Intel releases fast and open source quicksort implementation using AVX-512.
#avx512 #quicksort #intel #numpy
Phoronix · @phoronix
1979 followers · 1478 posts · Server noc.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.@IntelSoftware Publishes Blazing Fast #AVX512 @IntelDevTools Sorting Library, #Numpy Switching To It For 10~17x Faster Sorts
-- Wicked fast (and @OpenAtIntel #opensource) AVX-512 quicksort!
https://www.phoronix.com/news/Intel-AVX-512-Quicksort-Numpy
Original tweet : https://twitter.com/phoronix/status/1625963128646250500
Felix LeClair (Wants a job😊) · @fclc
363 followers · 741 posts · Server mast.hpc.socialIf Xeon-W has #amx I'm super interested in it as a platform.
If it doesn't? It becomes a little uninteresting for me specifically (since I already have #AVX512 Golden Cove, but with less cores/PCIe/mem )
Also hoping that they don't segment AMX between the 2400 and 3400 series....