
MTRNord (they/them) · @MTRNord
71 followers · 1605 posts · Server mastodon.nordgedanken.devAnyone here familiar with #cephfs recover? I ran out of space because it isn't reclaiming free space. Any ideas what I need to do?
Reboosts appreciated
#cephfs #ceph #rook #kubernetee

ij · @ij
1992 followers · 6628 posts · Server nerdculture.de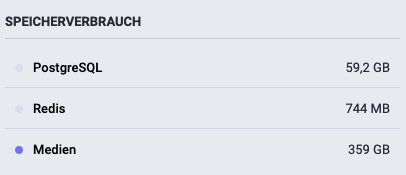
Hmmm, die Mastodon Datenbank finde ich nun auch nicht gerade klein mit 59 GB.
Die fast 400 GB Medien stoeren mich nun mit dem #CephFS zum Glück nicht mehr. Insbesondere nicht, wenn ich die VM dann mal auf einen anderen Host verschieben muss.

vsoch · @vsoch
402 followers · 241 posts · Server mastodon.socialThis is early work - I'll need to work through the same logic using cloud, and once we have that, we need to optimize. It's just exciting after an arduous weekend of failure with #rook and #cephfs. It's OK if things are hard sometimes, but that kind of complexity is a red flag. 🟥
ij · @ij
1972 followers · 6301 posts · Server nerdculture.deirgendwie verstehe ich #CephFS noch nicht so recht....
- Für ein CephFS brauch ich OSDs
- außerdem braucht ein CephFS auch eigene Metadata und Data Pools
- und es braucht offenbar pro CephFS einen eigenen MDS
Wenn ich nun auf einem 3-node Ceph Cluster mehrere getrennte Filesysteme haben will, kann ich maximal 3 haben, weil MDS hier beschränkt.
Oder ist die Idee dann, dass man mit Volumes arbeitet?
ij · @ij
1964 followers · 6246 posts · Server nerdculture.deAlso irgendwie komme ich mit #CephFS noch nicht so ganz klar:
Ich hab einen Pool, ein CephFS, ein Subvolume und die Anleitung:
https://docs.ceph.com/en/quincy/cephfs/client-auth/
Aber wo bekomme ich die client.<id> her? Hmmm...
ij · @ij
1933 followers · 6102 posts · Server nerdculture.deA #Proxmox question again:
How can I change the default mount path for #CephFS? I don't want it to be under /mnt/pve/<STORAGE_ID>/ as described in https://pve.proxmox.com/wiki/Storage:_CephFS, but maybe on /srv/pve/<STORAGE_ID> instead.
Editing the path after creation in storage.conf feels wrong to me...

Sortiermodus · @newdefined
218 followers · 7699 posts · Server troet.cafe
Sortiermodus · @newdefined
218 followers · 7688 posts · Server troet.cafe
{kind=link}
{kind=link}

· @jokeyrhyme
66 followers · 908 posts · Server aus.socialHmmm, I think installing this helm chart of the #CephFS CSIDriver on my #Kubernetes cluster has ruined it: https://artifacthub.io/packages/helm/ceph-csi/ceph-csi-cephfs
Every node is pegged at 100% CPU usage, only able to respond to a small fraction of pings, and not responding to `kubectl` at all
There's a warning about this at https://www.talos.dev/docs/v0.14/guides/storage/#storage-clusters :
> Also, if your cluster is small, just running Ceph may eat up a significant amount of the resources you have available.
I just wasn't expecting 100% of my resources to be consumed, and just by the CSIDriver
This isn't even the actual CephFS cluster that I'd need to be able to store files, this is just the driver to connect to such a cluster, and it is all-consuming!
I'm going to leave this for a few hours and see if this converges on a working state by itself, otherwise I'm going to have to wipe and start with a fresh cluster :S
So kids, don't do CephFS