
Chris Wensel · @cwensel
176 followers · 1510 posts · Server fosstodon.org@Cmastication depends on how you access it? If via a query, only partition on the most common predicates.
Repartitioning data for different access patterns is a key use case behind #clusterless and tessellate. See bio for links.
Otherwise yeah, partition via hash to get equal sized bits. Reminds me to add a hash transform to tessellate.
Chris Wensel · @cwensel
170 followers · 1395 posts · Server fosstodon.org
just sayin', if you find chaining sql statements into a data processing dag a bit of a drag, I suggest you spend some time with #clusterless
https://github.com/ClusterlessHQ
declarative decentralized heterogeneous #data flows (in #aws today)
Chris Wensel · @cwensel
171 followers · 1385 posts · Server fosstodon.orggah, finally. now have a #clusterless arc that will automatically update #aws glue table partitions to include newly arrived partitions.
will clean up the aws s3 logs example to include this tomorrow.
the example will show how to provision a database, table with schema (generated from tessellate), and deploy arcs that convert csv to parquet and keep the table partitions up to date.
Chris Wensel · @cwensel
169 followers · 1347 posts · Server fosstodon.orgAsked to start either Gitter or Discord channel for the #clusterless tessellate project by a team in the UK.
I'd prefer to use Github discussions to keep things co-located, more discoverable, and more async. But I've never actually used it for anything. Or seen it used much.
Gitter would be my second choice. but I see now Gitter is on Matrix. don't yet have an opinion on that.
The Wardley Mapping community just moved to Discord from Slack. Seems to work for for that community.
Thoughts?
Chris Wensel · @cwensel
169 followers · 1347 posts · Server fosstodon.orgSo #clusterless uses the AWS CDK and not terraform. Though I did plan to use the version of the CDK that wrapped terraform to manage non AWS infrastructure.
Curious how that community is going to react.
Chris Wensel · @cwensel
169 followers · 1347 posts · Server fosstodon.org
some time ago I re-implemented Twitter-Snowflake https://github.com/twitter-archive/snowflake/tree/snowflake-2010
Was just about to reboot that effort for use in #clusterless Tessellate for #java but a quick search found TSID Creator
https://github.com/f4b6a3/tsid-creator
This is great if you need a locally unique id that fits in 64bits.
Chris Wensel · @cwensel
165 followers · 1301 posts · Server fosstodon.orgadding #aws Glue database and table support to #clusterless
wish me luck.
fwiw, outside of simply provisioning a database or table with a schema, an Arc will be provided to add partitions to the catalog as they arrive keeping table up to date (and blind to corrupt or partial data)
this will make it trivial to have a table around every stage/arc of a pipeline dataset for ad-hoc queries and quality checks.
Chris Wensel · @cwensel
163 followers · 1273 posts · Server fosstodon.orgIn a dream last night I tried to explain #clusterless.
It’s like assembling a train but running it on someone else’s track.
Chris Wensel · @cwensel
161 followers · 1230 posts · Server fosstodon.orgI just pushed a new #clusterless sample application that will continuously convert AWS S3 Access Logs into Apache Parquet. This is an end-to-end real-world application using Clusterless and Tessellate together..
https://github.com/ClusterlessHQ/aws-s3-log-pipeline
Check it out and provide feedback.
Chris Wensel · @cwensel
161 followers · 1230 posts · Server fosstodon.org@Hhildebrand this is great news, I really enjoyed using it on the MR simulation.
I think now i'd like to PoC it to simulate #clusterless latencies/lag and cost-to-serve in #aws data pipelines.
the hard/interesting part is properly instrumenting a clusterless deployment to get real data for the simulator to use.
getting cost estimates before a deployment would be pretty cool.
Chris Wensel · @cwensel
161 followers · 1197 posts · Server fosstodon.orgThe stack could use some work, still unsure about the workflow manager.
But the #clusterless scenario testing tools really help build confidence in the pipelines after a bit of refactoring.
esp when run as a github action:
https://github.com/ClusterlessHQ/clusterless/actions/runs/5625634150
Chris Wensel · @cwensel
159 followers · 1189 posts · Server fosstodon.orga core design element behind #clusterless is that all data artifacts must be inventoried and all work is driven by the inventories.
data (files, objects, etc) can arrive at any rate. but once a manifest of arrivals is complete, a pipeline of work can start. and each workload is responsible for providing an inventory of completed work artifacts.
this allows for any new workload to be injected into the system (event dag), and to be backfilled if needed.
Chris Wensel · @cwensel
159 followers · 1189 posts · Server fosstodon.org
Last night I pushed a new build of Tessellate for download: https://github.com/ClusterlessHQ/tessellate
This release includes MVEL template support in the JSON pipeline definition.
#clusterless #aws #dataengineering
Chris Wensel · @cwensel
159 followers · 1189 posts · Server fosstodon.orgguess I'll head to the pool while I wait for all my new Cascading builds to complete. fixes and features for 4.5 and 4.6 coming.
Also hope to have a new #clusterless tessellate build out this evening with direct support of MVEL expression templates pre-processed in the JSON pipeline file. includes some handy intrinsics for file naming and partitioning.
Chris Wensel · @cwensel
161 followers · 1145 posts · Server fosstodon.org
So Tessellate inherits lots of support for various data formats from Cascading
https://github.com/cwensel/cascading
Even though #apacheparquet dropped Cascading support, we were able to port it over.
Now that Parquet is native to Cascading, it should be easier to add #apacheiceberg support.
This would allow #clusterless to convert data as it arrives into Iceberg continuously for use in #aws Athena or other data front-ends.
Anyone interested in a challenge?
#apacheparquet #ApacheIceberg #clusterless #aws #java
Chris Wensel · @cwensel
161 followers · 1145 posts · Server fosstodon.org
Still working through this concept, but Tessellate will have native built in support for common schema formats that can be referenced by name.
For example, the AWS S3 Access log format: https://github.com/ClusterlessHQ/tessellate/blob/wip-1.0/tessellate-main/src/main/resources/schemas/aws-s3-access-log.json
The AWS Cloudfront logs are up next to support.
Any other log formats that would be nice to have native support for?
#clusterless #aws #dataengineering
Chris Wensel · @cwensel
161 followers · 1145 posts · Server fosstodon.org
Pushed a new build of Tessellate at https://github.com/ClusterlessHQ/tessellate
Now has support for some basic transforms like coerce, rename, discard, copy, and insert.
When back from camping, plan to have a working #clusterless example to share and some reasonable documentation.
Chris Wensel · @cwensel
154 followers · 1105 posts · Server fosstodon.orgJust added some simple console metrics to Tessellate. Tuples read/written and durations. Adding rates is a todo.
Chris Wensel · @cwensel
148 followers · 1010 posts · Server fosstodon.orgI've pushed up the start of the #clusterless documentation to https://docs.clusterless.io/
Thanks to the Antora project for providing the doc framework: https://antora.org
We also now have downloadable package/releases on Github: https://github.com/ClusterlessHQ/clusterless/releases
Additional thanks to JReleaser for implementing the packaging functionality: https://jreleaser.org
Chris Wensel · @cwensel
148 followers · 991 posts · Server fosstodon.org
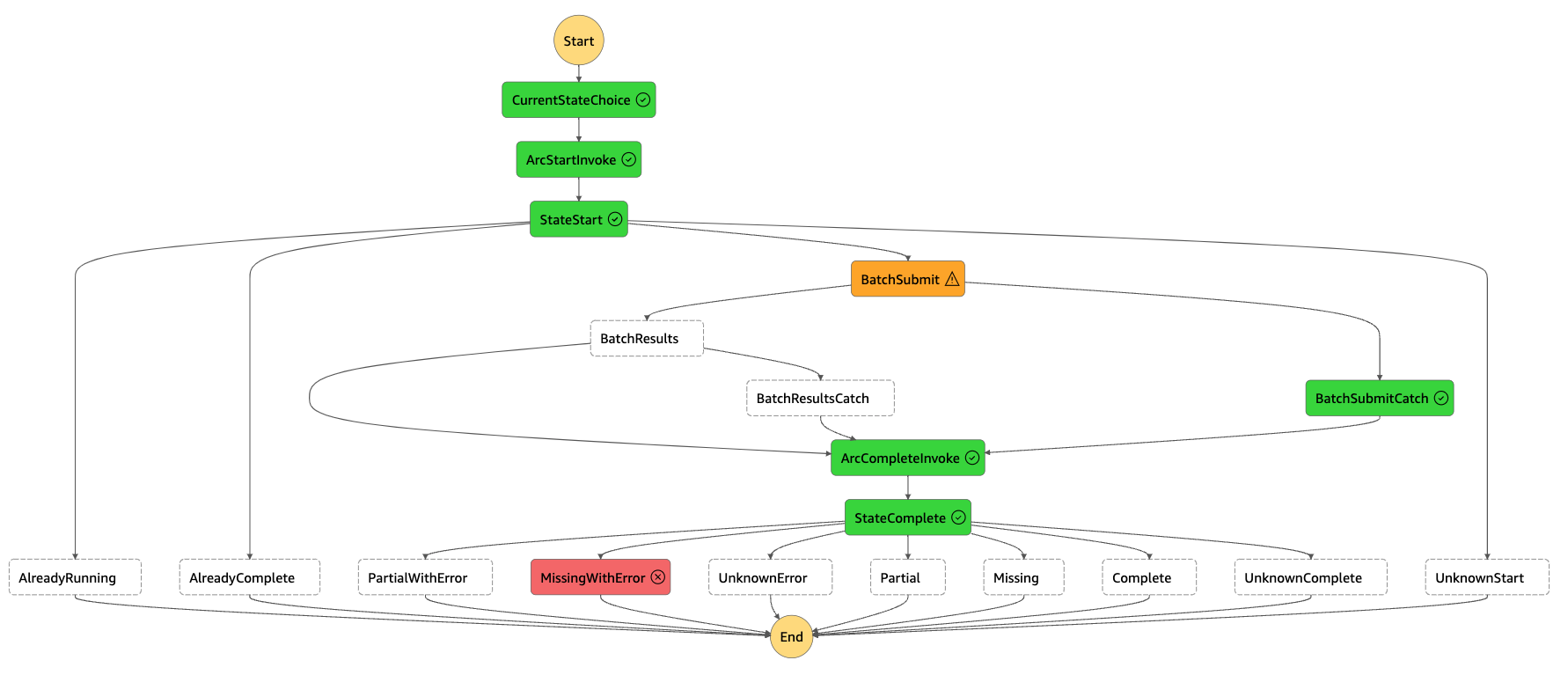{kind=link}
Here is an arc where the workload failed.
#clusterless doesn't care about errors as much as people do, but it does care about missing data more.
errors could be a reason for missing data, but there may be other reasons that aren't errors that need human attention.