
Amy Fountain · @amyfou
1782 followers · 271 posts · Server lingo.lolSo I'm lead on a grant proposal that involves several colleagues and is so so so close to successful submission <-- not a complaint!
But wowza, the process is painful in many ways. <-- definitely a complaint.
One of the ways is the thing that just ate 2.5 hours out of my workday, for a task that should take .5 of an hour, that needed to be done by someone other than me, and that was already attempted by others.
Ready?
1/x
#academicchatter #complaint #ugh

Rafael · @ipxfong
300 followers · 1660 posts · Server mastodon.sdf.orgYou know what I miss? Back in the day, when you got a new computer it would be a new experience. New software, new capabilities, maybe even a new community. It's nice not to have to get a new wordprocessor every time I upgrade but it sucks in other ways. I'm going to have to get a new phone soon. There's nothing wrong with the one I have but it's getting EOL'd. The new phone will be a bit faster and maybe have higher resolution but will be otherwise identical. Yay... #complaint #yellingatclouds

DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net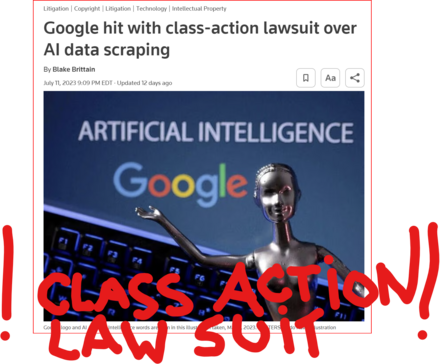
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

MH Speaks · @mch_speaks
0 followers · 10 posts · Server mas.toThis is more of a #complaint than a #poem.
The sun sets over the river with blue hues fading into orange
Somewhere someone whispers “#free them” to the forest
They shout off the mountain top, “free me!”
Squirrels chase each other
Purple eyes darting back and forth
Matching the lavender trees yonder
Shackles spread from the thick branches
Towering over, deep with shadows
Why, my #country?
When will you break these #chains? (Cont)
#chains #country #free #poem #complaint
CryptoNewsBot · @cryptonewsbot
682 followers · 36197 posts · Server schleuss.onlineClass Action Lawsuit Against Tether, Bitfinex Dismissed - A class action lawsuit filed against cryptocurrency firms Tether and Bitfinex was ... - https://news.bitcoin.com/class-action-lawsuit-against-tether-bitfinex-dismissed/ #marketmanipulation #cryptocurrency #tetherbitfinex #jurisdiction #executives #stablecoin #complaint #dismissal #bitfinex #exchange #reserves #unbacked #backing #damages #lawsuit #newyork #injury #owners #ruling #tether #legal #judge #usdt
#USDT #judge #legal #tether #ruling #owners #injury #newyork #lawsuit #damages #backing #unbacked #reserves #exchange #bitfinex #dismissal #complaint #stablecoin #executives #jurisdiction #tetherbitfinex #cryptocurrency #marketmanipulation
CryptoNewsBot · @cryptonewsbot
674 followers · 34755 posts · Server schleuss.onlineBinance, CZ to Seek Dismissal of CFTC Complaint - Crypto exchange Binance and its founder and CEO Changpeng Zhao (CZ) plan to seek t... - https://news.bitcoin.com/binance-cz-to-seek-dismissal-of-cftc-complaint/ #cryptoexchange #cryptoassets #derivatives #regulations #securities #complaint #dismissal #exchange #binance #lawsuit #tokens #legal #rules #case #cftc #laws #suit #sec
#sec #suit #laws #cftc #case #rules #legal #tokens #lawsuit #binance #exchange #dismissal #complaint #securities #regulations #derivatives #cryptoassets #cryptoexchange
CryptoNewsBot · @cryptonewsbot
674 followers · 34749 posts · Server schleuss.onlineCFTC charges Tennessee couple over 'Blessings of God Thru Crypto’ scheme - Despite having no trading experience a Tennessee couple convinced... - https://cointelegraph.com/news/cftc-charge-couple-blessings-of-god-crypto-investment-scheme #commodityfuturestradingcommission #complaint #lawsuit #fraud #cftc #scam
#scam #cftc #fraud #lawsuit #complaint #commodityfuturestradingcommission
CryptoNewsBot · @cryptonewsbot
672 followers · 34730 posts · Server schleuss.online
Ripple vs. SEC — Respite for a Beleaguered Industry - On July 13, 2023, the U.S. District Court for the Southern District of New York (S... - https://news.bitcoin.com/ripple-vs-sec-respite-for-a-beleaguered-industry/ #securitiesexchangecommission #districtjudgeanalisatorres #southerndistrictofnewyork #cryptoassetsecurities #unregisteredoffering #digitalassetlawyers #securitiesactof1933 #investmentcontract #u.s.districtcourt #currencyexchange #secv.w.j.howeyco #u.s.supremecourt #complaint
#complaint #secv #currencyexchange #u #investmentcontract #securitiesactof1933 #digitalassetlawyers #unregisteredoffering #cryptoassetsecurities #southerndistrictofnewyork #districtjudgeanalisatorres #securitiesexchangecommission
CryptoNewsBot · @cryptonewsbot
670 followers · 34575 posts · Server schleuss.onlineBinance, CEO Changpeng Zhao intends to seek dismissal of CFTC complaint - Binance, Changpeng Zhao and former compliance chief Samuel Lim in... - https://cointelegraph.com/news/binance-ceo-plans-motion-dismiss-cftc-complaint-lawsuit #commodityfuturestradingcommission #changpengzhao #complaint #lawsuit #cftc #cz
#cz #cftc #lawsuit #complaint #changpengzhao #commodityfuturestradingcommission
DavidV.TV ® · @DavidVTV
5 followers · 1706 posts · Server tastingtraffic.net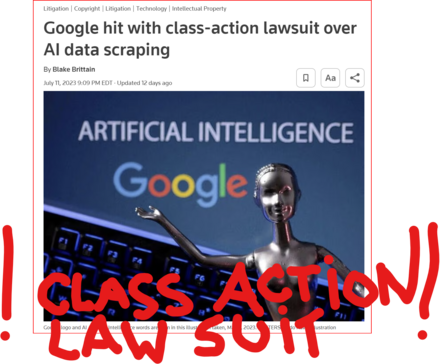
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1698 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1697 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.net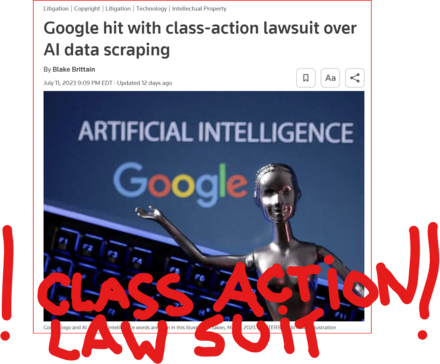
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2981 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.net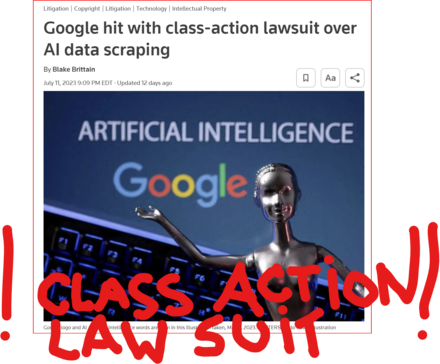
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

TastingTraffic Social® · @InternationalTechNews
17 followers · 5638 posts · Server tastingtraffic.net
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#GUILTY UNTIL PROVEN #INNOCENT IF YOU ARE #LUCKY..
Greg Seevers gives a few reasons why he will likely never marry again. Not only are #NO_SAFETY_NETS or legal protections in place for someone who wants to get married, but he or she can lose EVERYTHING and end up in prison based on FALSE ACCUSATIONS.
False accusations are a #HUGE_PROBLEM in the STATE of #TEXAS.
The falsely accused, instead of being deemed innocent until proven guilty, finds himself or herself in a situation where the accusation is equated with guilt unless the accused can prove himself or herself innocent—just the opposite of the way things are supposed to be. In cases where the accusation amount to perjury, there is #SELDOM_ANY_PUNISHMENT for perjury.
The bottom line is this: #Perjury is allowed in #Family_Court, with little if any consequence to the person committing the perjury. Often perjury appears to be rewarded. #Judges permit perjury, and when a #complaint is made to the Texas State Commission on #Judicial_Conduct, they claim that they can’t do anything about it..
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#FALSE_ACCUSATIONS #guilty #INNOCENT #lucky #NO_SAFETY_NETS #HUGE_PROBLEM #texas #SELDOM_ANY_PUNISHMENT #Perjury #Family_Court #judges #complaint #Judicial_Conduct #INVITE #INTERNATIONAL_TECH_NEWS