
Published papers at TMLR · @tmlrpub
567 followers · 576 posts · Server sigmoid.social
Understanding convolution on graphs via energies
Francesco Di Giovanni, James Rowbottom, Benjamin Paul Chamberlain et al.
Action editor: Guillaume Rabusseau.
#convolutions #convolutional #Graphs

New Submissions to TMLR · @tmlrsub
199 followers · 699 posts · Server sigmoid.social
Dual-windowed Vision Transformer with Angular Self-Attention
#attention #vision #convolutional
New Submissions to TMLR · @tmlrsub
178 followers · 593 posts · Server sigmoid.social
Understanding convolution on graphs via energies
#convolutions #convolutional #Graphs
New Submissions to TMLR · @tmlrsub
180 followers · 580 posts · Server sigmoid.social
A Few Adversarial Tokens Can Break Vision Transformers
#adversarial #convolutional #tokens
Published papers at TMLR · @tmlrpub
516 followers · 390 posts · Server sigmoid.social
Transformer for Partial Differential Equations’ Operator Learning
Zijie Li, Kazem Meidani, Amir Barati Farimani
Action editor: Tie-Yan Liu.
#attention #perceptrons #convolutional

MT Group at FBK · @fbk_mt
5 followers · 7 posts · Server sigmoid.socialOur pick of the week by @mgaido91: Poli et al., "Hyena Hierarchy: Towards Larger Convolutional Language Models"
https://arxiv.org/pdf/2302.10866.pdf
#hyena #AI #LM #convolution #convolutional #LLM
#hyena #ai #lm #convolution #convolutional #llm
Published papers at TMLR · @tmlrpub
507 followers · 307 posts · Server sigmoid.social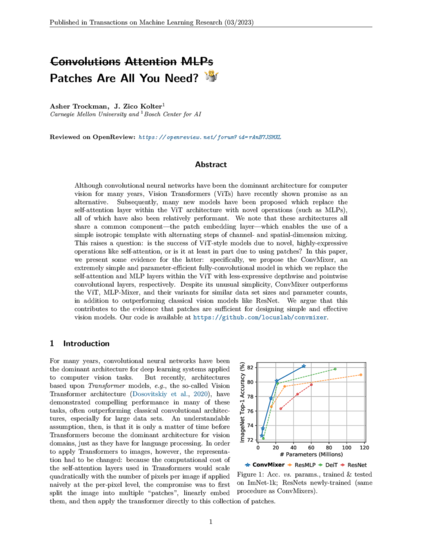
#attention #convolutional #vision

TMLR certifications · @tmlrcert
111 followers · 19 posts · Server sigmoid.social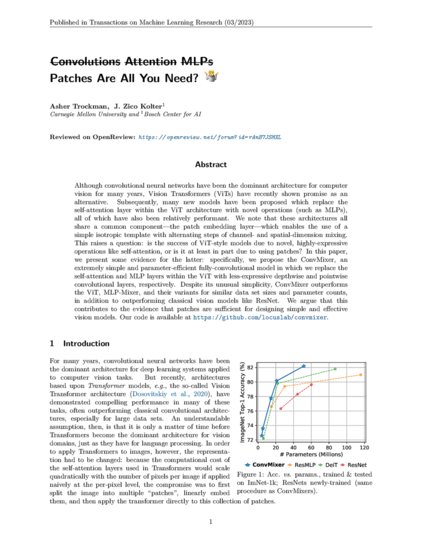
#featuredcertification #attention #convolutional #vision
Published papers at TMLR · @tmlrpub
495 followers · 197 posts · Server sigmoid.social
Optimal Convergence Rates of Deep Convolutional Neural Networks: Additive Ridge Functions
Zhiying Fang, Guang Cheng
New Submissions to TMLR · @tmlrsub
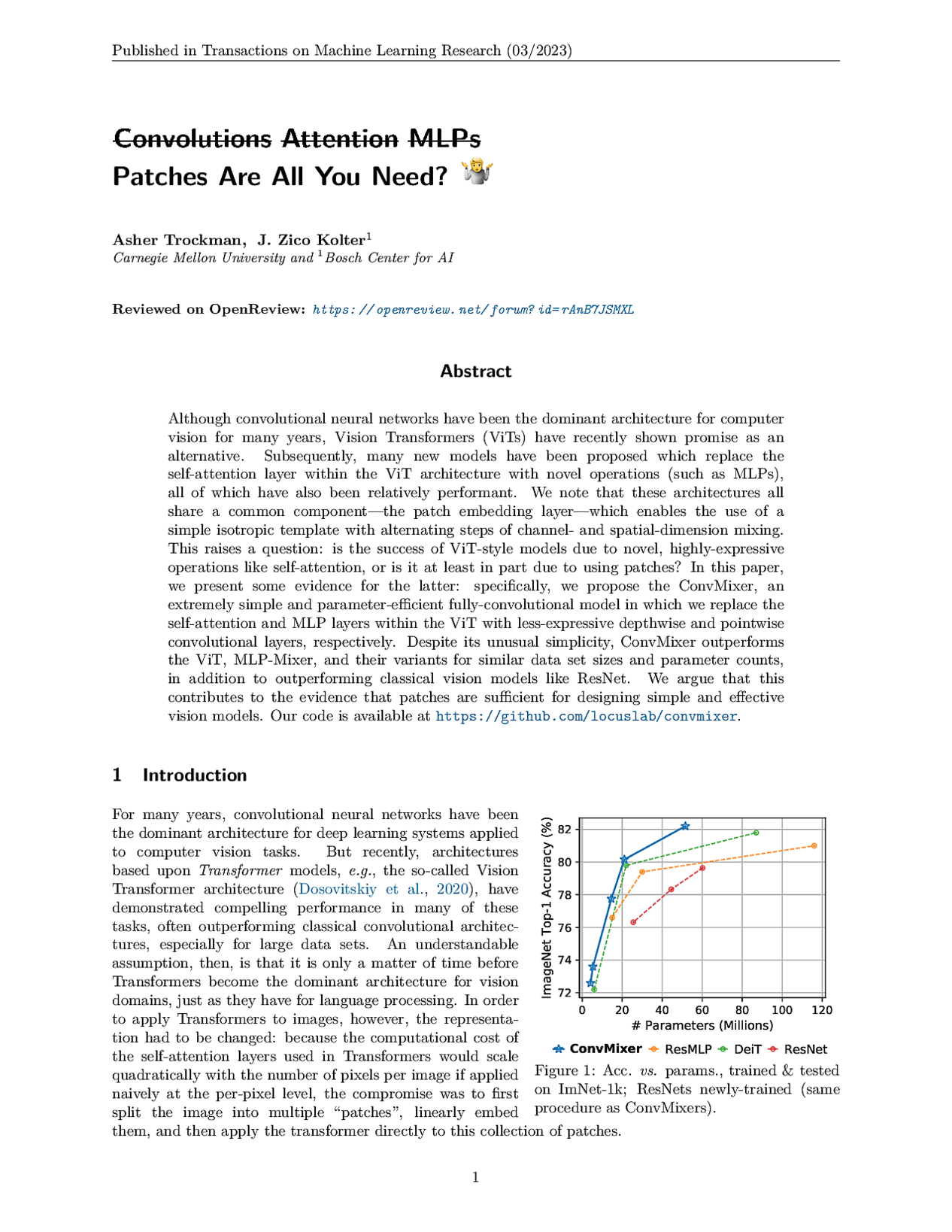
153 followers · 312 posts · Server sigmoid.social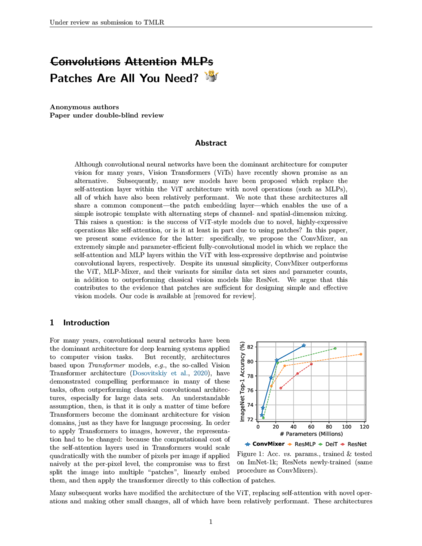
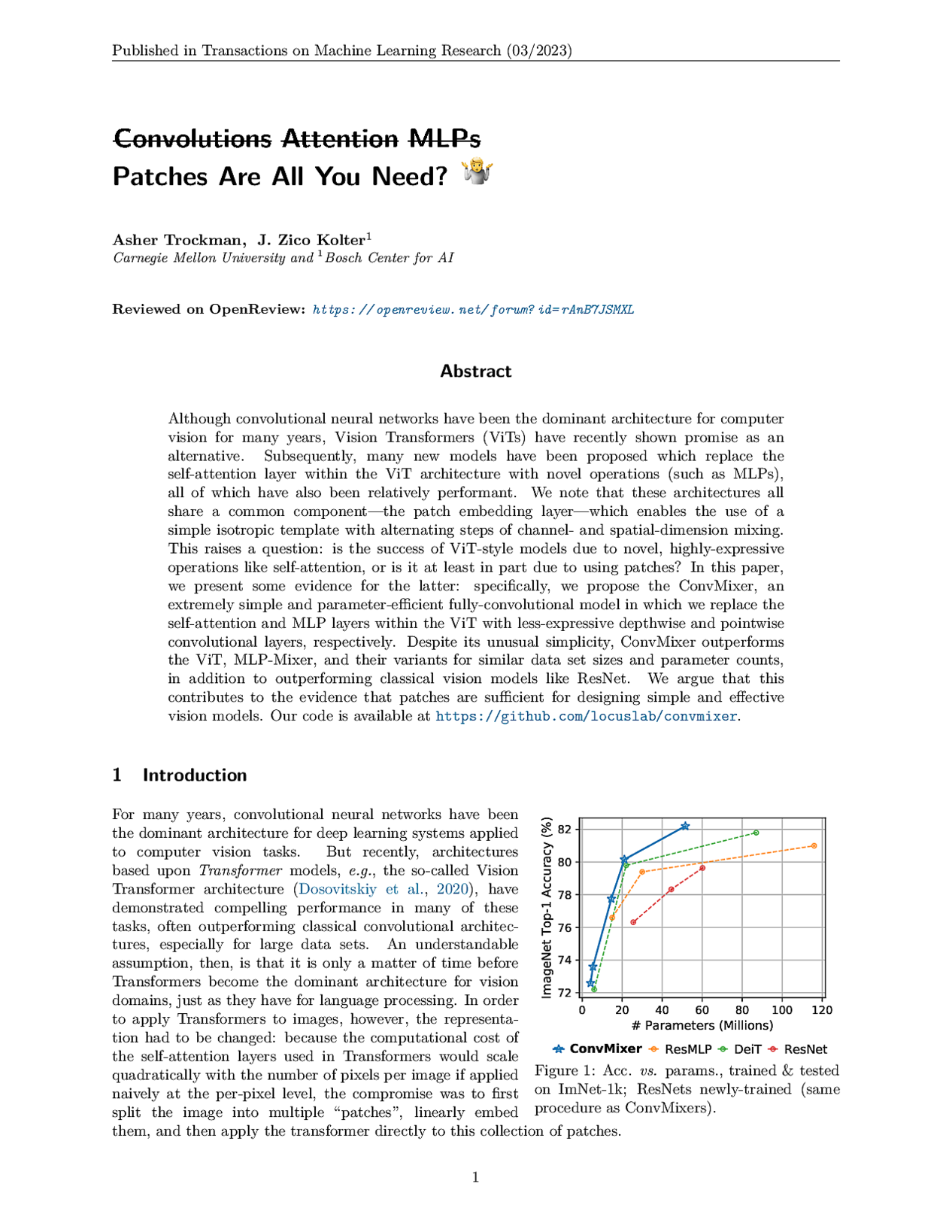
Patches Are All You Need?
#attention #convolutional #vision
New Submissions to TMLR · @tmlrsub
148 followers · 302 posts · Server sigmoid.social
Transformer for Partial Differential Equations’ Operator Learning
#attention #perceptrons #convolutional

JMLR · @jmlr
598 followers · 101 posts · Server sigmoid.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
'ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction', by Kwan Ho Ryan Chan, Yaodong Yu, Chong You, Haozhi Qi, John Wright, Yi Ma.
http://jmlr.org/papers/v23/21-0631.html
#convolutions #convolutional #discriminative
#convolutions #convolutional #discriminative