
C. · @cazabon
169 followers · 4177 posts · Server mindly.social#European countries' laws can be very different from #English common-law countries' (and E.U. #law even stranger), so I make no claim about those.
But you are #mistaken about #Canadian (and I believe all other English common-law countries) law - #facts #absolutely cannot be #copyrighted. You cannot stop someone #writing a #story based on facts you reveal in your story.
See https://ised-isde.canada.ca/site/canadian-intellectual-property-office/en/guide-copyright#faq , question (2), in addition to other places.
#european #english #Law #mistaken #canadian #facts #absolutely #copyrighted #writing #story #commonlaw
C. · @cazabon
169 followers · 4177 posts · Server mindly.socialThat is already the #law; #facts cannot be #copyrighted. Ideas cannot be copyrighted. Only a particular #expression of an #idea can be copyrighted.
If #newspaper A prints a scoop, newspaper B or website C is already free to write their own #article using facts from it. They can't just #copy the #article and change a few words, but they absolutely can use every fact from the original, and even #quote it with #attribution.
#Law #facts #copyrighted #expression #idea #newspaper #article #copy #quote #attribution

DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net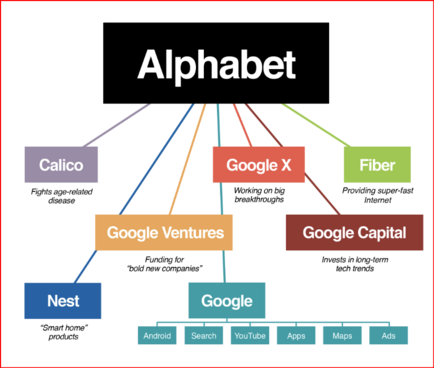
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net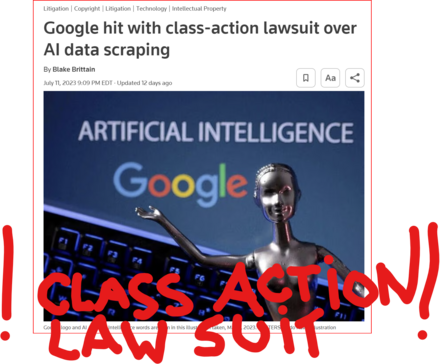
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

coupland · @coupland
60 followers · 157 posts · Server cryptodon.lolWARNING, WARNING! #AI companies are training their models using #copyrighted books and essays!
It probably won't reproduce it in full but it could quote from it, could incorporate general principles and writing style into its own style, and may even reuse the knowledge it harvested from reading many copyrighted works to later do for-profit work. All from reading other peoples' books! Exclamation mark! Exclamation mark!
You know, JUST LIKE HUMANS DO EVERY DAY.
DavidV.TV ® · @DavidVTV
5 followers · 1706 posts · Server tastingtraffic.net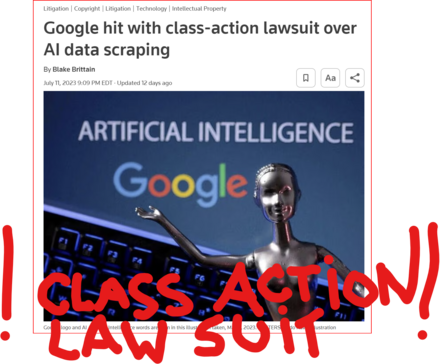
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1698 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1697 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.net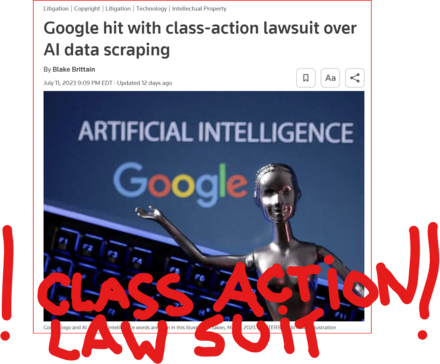
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2981 posts · Server tastingtraffic.net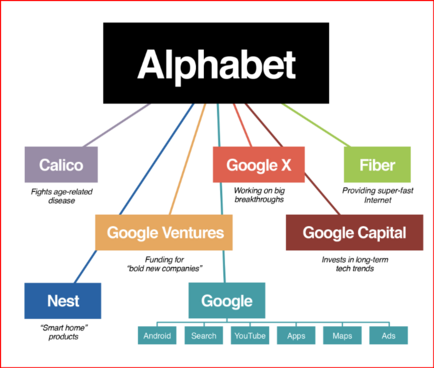
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.net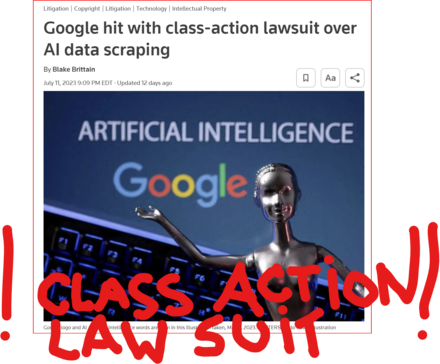
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

Charlie McHenry · @CharlieMcHenry
341 followers · 742 posts · Server connectop.usGenerative AI’s copyright problem grows as lawsuits pile onto OpenAI, Google, Meta - the #AI giants are training their LLMs on our data, sometimes #copyrighted material. I’ve long maintained it is time for the tech giants to PAY US for access to our data. #legal #ArtificialIntelligence #copyright https://fortune.com/2023/07/12/generative-ai-copyright-lawsuits-silverman-openai-google-meta/
#ai #copyrighted #legal #artificialintelligence #copyright

Geekmaster 👽:system76: · @Geekmaster
182 followers · 1343 posts · Server ioc.exchangeHeads up: DO NOT install or use #Timu. That shit sends all your datas to servers in mainland China. Want proof? Quick Google search will show you. Plus, their vendors are #stealing #copyrighted material and infringing #trademarks from legitimate #Amazon SMB sellers.
#cybersecurity #donothackyourself #china #chinaAPT #ShittyShoppingApp #BuyAmerican
#timu #stealing #copyrighted #trademarks #amazon #cybersecurity #donothackyourself #china #chinaapt #shittyshoppingapp #buyamerican

🥥 Tucker Carlson's Nuts 🥥 · @JStatePost
697 followers · 16423 posts · Server newsie.social@AbandonedAmerica
🥥 Methinks it's time for some class-action lawsuits against Alphabet (Google) for unauthorized use of #copyrighted material in their #AI ##LLM training.
#LegalEagles, what say ye? 🥥
#copyrighted #ai #llm #legaleagles

petersuber · @petersuber
4238 followers · 1005 posts · Server fediscience.org
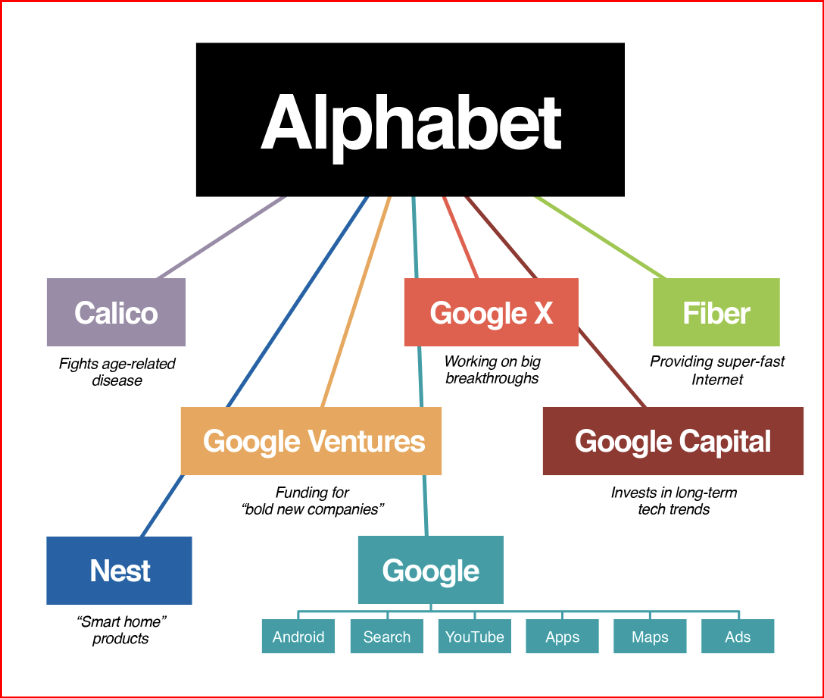{kind=link}
{kind=link}
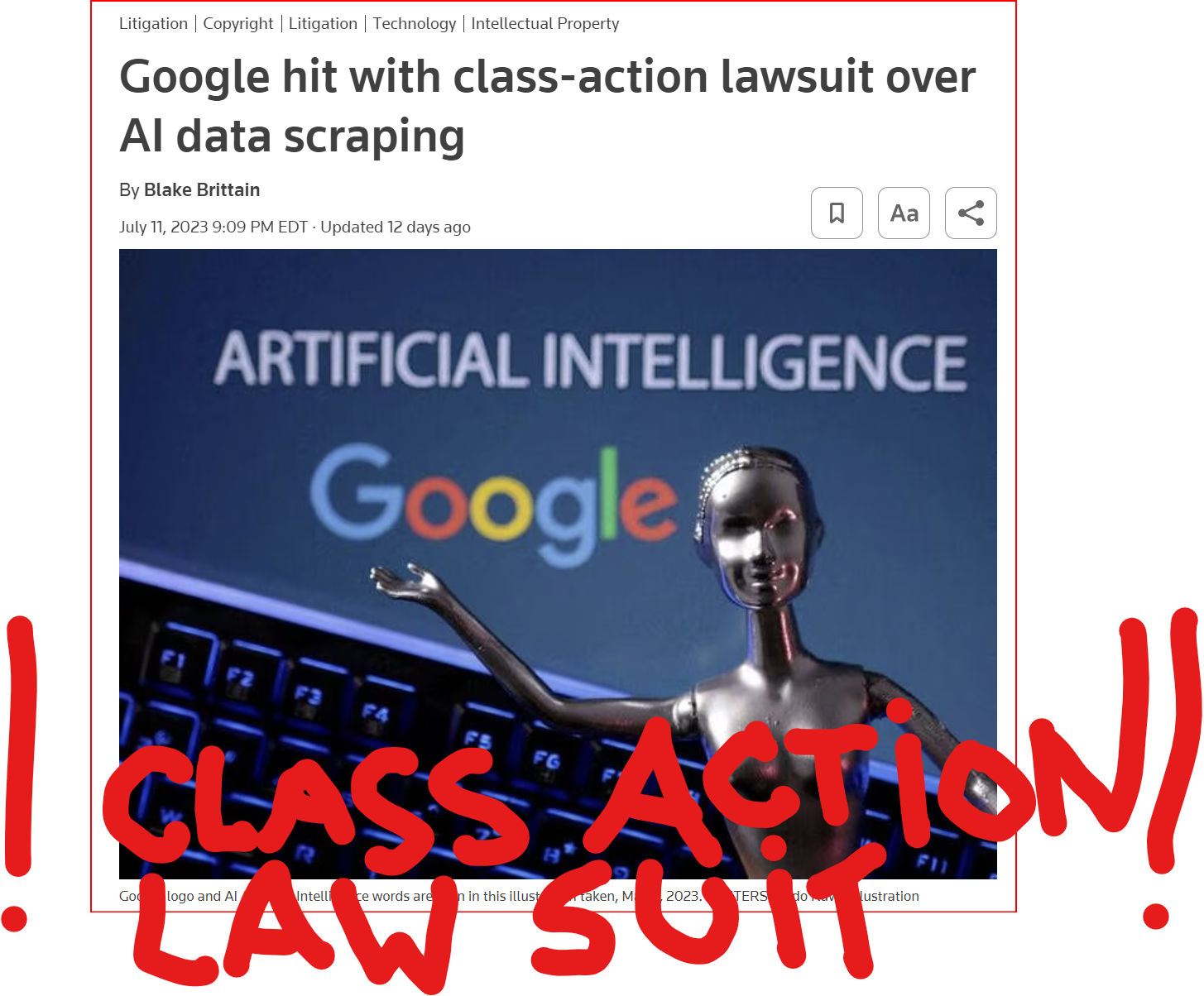{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#Japan will allow #AI tools to train on any #copyrighted material “regardless of whether it is for non-profit or commercial purposes, whether it is an act other than reproduction, or whether it is content obtained from illegal sites or otherwise."
https://technomancers.ai/japan-goes-all-in-copyright-doesnt-apply-to-ai-training/
PS: For better or worse, and plowing under all legal complexities, this is a bold move that I imagine will be matched by equal and opposite bold moves in other jurisdictions.
#llm #copyright #copyrighted #ai #japan

Gary · @empiricism
219 followers · 772 posts · Server ecoevo.social#capitalism is harmful for humans (even, or especially, the rich ones sense of #justice ). Capitalism is #unsustainable. #ecosystem #biosphere #ClimateChange
Not #copyrighted ideas to help end #capitalism
Idea for artists. Imagine a sheep that has been newly shaved. The sheep is shivering in the cold.
The "generous" sheep shearing capitalist farmer is offering to sell the sheep it's own wool.
#irony of capitalism
#capitalism #justice #unsustainable #ecosystem #biosphere #climatechange #copyrighted #irony #economy #sustainability #parody #psychology
Gary · @empiricism
219 followers · 772 posts · Server ecoevo.social#capitalism is harmful for humans (even, or especially, the rich ones). Capitalism is #unsustainable. #ecosystem #biosphere #ClimateChange
Not #copyrighted ideas to help end #capitalism
Idea for artists. Imagine a sheep that has been newly shaved. The sheep is shivering in the cold.
The "generous" sheep shearing capitalist farmer is offering to sell the sheep it's own wool.
#irony of capitalism
#capitalism #unsustainable #ecosystem #biosphere #climatechange #copyrighted #irony #economy #sustainability #parody #psychology