
Quinn Dombrowski · @quinnanya
2139 followers · 2629 posts · Server mstdn.socialIs there any better news to wake up to than the fact that Norway has digitized All The Books and it's no problem at all to get all their Baby-Sitters Club translations? 🤩 #DigitalHumanities #DataSittersClub #corpora
#corpora #DataSittersClub #digitalhumanities

Michael Piotrowski · @mxp
648 followers · 676 posts · Server mastodon.acm.org
A survey of corpora for Germanic low-resource languages and dialects.
#NLProc #linguistics #corpora https://github.com/mainlp/germanic-lrl-corpora

Joshua McNeill · @joshisanonymous
119 followers · 311 posts · Server h4.io#ZipfsLaw makes it hard to study #lexical #variation in #language, but some features would be difficult even with very large #corpora due to being homophonous with a more frequent feature. One I've come across lately is "I hate it" where the #demonstrative "that" is more common, e.g. in response to seeing a scary clown image.
#linguistics #languagevariation #syntax #morphology #pronouns
#zipfslaw #Lexical #variation #language #corpora #demonstrative #linguistics #languagevariation #syntax #Morphology #pronouns

Matt L. · @humanitiesData
186 followers · 76 posts · Server fosstodon.orgIf you need to wrangle with EEBO-TCP for your text analysis project, consider using the EarlyPrint project corpus. They've done a bunch of preprocessing to transform "the early English print record, from 1473 to the early 1700s, into a linguistically annotated and deeply searchable text archive." Documentation and tutorials are all really thorough. https://earlyprint.org/about/ https://humanitiesdata.com/resources/436 #CulturalAnalytics #dh #opendata #corpora #eebo-tcp
#culturalanalytics #dh #opendata #corpora #eebo

Institut für Deutsche Sprache · @ids_mannheim
427 followers · 94 posts · Server wisskomm.social
📣 #CfP for the 10th International Conference on CMC and Social Media Corpora for the Humanities 2023! Submission deadline: 30 April 2023. More info: 👉https://uni-mannheim.de/cmc-corpora2023/call-for-papers-cfp/ The conference will be held at the University of Mannheim in collaboration with the IDS, from 14–15 September 2023.
#CallForPapers #conference #DigitalHumanities #Corpuslinguistics #Korpuslinguistik #Corpora #SocialMedia #Linguistics #Linguistik #IDSMannheim
#cfp #callforpapers #conference #digitalhumanities #corpuslinguistics #korpuslinguistik #corpora #socialmedia #linguistics #linguistik #idsmannheim

Alexander Huber · @c18ah
284 followers · 173 posts · Server hcommons.social
Have you explored the new #EighteenthCenturyPoetryArchive corpus builder yet? It allows you to quickly create and share collections of poems, editions, or lists of authors with a single link!
https://www.eighteenthcenturypoetry.org/resources/corpusbuilder.shtml
#EighteenthCenturyPoetryArchive #c18th #poetry #18thc #c18dh #ecpa #corpora #readinglists

Contributions · @ConHistCon
66 followers · 10 posts · Server mas.toHow to approach large-scale #corpora and new basic #concepts? In their article „The Rise of Health”, Anne Kveim Lie, Lars G Johnsen, Helge Jordheim and Espen Ytreberg explore the emergence of new #keyconcepts in the post-#Sattelzeit. As a first case study, the explored concept is ‘health’ which is central to the Norwegian welfare state. The study is done based on #digitizednewspapers from the 1950s onwards. Get your copy now at: https://bit.ly/choc_17_2
#digitizednewspapers #sattelzeit #keyconcepts #concepts #corpora

Emily M. Bender (she/her) · @emilymbender
13415 followers · 1471 posts · Server dair-community.social
Berenike Herrmann · @jberenike
216 followers · 24 posts · Server fedihum.org#Literaturwissenschaft, #digital?! Wir suchen w/m/d die @unibielefeld
Studiengang BA Germanistische Literaturwissenschaft mitgestaltet! 🎨 #digitalität #dataliteracy #Curriculum4_0_NRW #corpora
.... befristet auf ein Jahr, 50%, kompatibel o. als Einstieg! https://jobs.uni-bielefeld.de/job/view/2318/wissenschaftliche-r-mitarbeiter-in-m-w-d-fuer-digitale-literaturwissenschaft?page_lang=de
#literaturwissenschaft #digital #digitalitat #dataliteracy #curriculum4_0_nrw #corpora

Martin Schäfer · @demeco_project
94 followers · 41 posts · Server digitalcourage.socialSome hard facts from the British National Corpus #BNC : of the 44 hits for "oddness", 16 come from the same source, which turns out to be D. A. Cruse's "Lexical Semantics" textbook from 1986. Which makes me wonder, not for the first time, whether it has been a good idea to include linguistic texts in the BNC sampling :)
#EnglishLinguistics #corpora #metaLinguistics
#metalinguistics #corpora #englishlinguistics #BNC

Linguistics - Eurac Research · @EuracLing
17 followers · 114 posts · Server mstdn.social
RT @SketchEngine
30+ French #corpora for you. Large corpora: try the multi-billion-word frTenTen or Timestamped corpus. Specialized language: choose these corpora – literature, rap songs, theatre scripts. Parallel: United Nations, OpenSubtitles, …
http://ske.li/french_corpora
#corpuslinguistics
Joshua McNeill · @joshisanonymous
101 followers · 204 posts · Server h4.io@stefanowitsch @linguistics #Python for dealing with #corpora, #R for #stats, #LaTeX with #knitr for transparency. I use #PowerShell a good amount too when I need to batch process files (e.g., convert a bunch of stereo audio files to mono). Sometimes I like using PowerShell over Python for text normalization over many files just because I've always found the file management syntax in Python clunky (e.g., removing diacritics). Also, let's not forget about #Praat scripting for #phonetics stuff
#python #corpora #r #stats #latex #knitr #powershell #Praat #phonetics

Savithry Namboodiripad · @savithry
113 followers · 18 posts · Server mastodon.social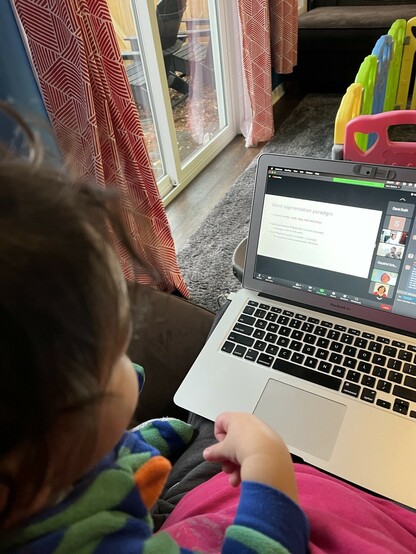
#SAFAL2022 continues with a keynote from Megha Sundara on how phonetic cues support morphological learning in young infants (see pic for baby raptly attending to this highly relevant work). At first, infants exploit homophony to induce suffixes, noting token frequency, and later, bottom up processing interacts with top-down info. And now theyre extending this work to Kannada, but we need a lot more #corpora esp. of spoken varieties! #acquisition #linguistics
#safal2022 #corpora #acquisition #linguistics

Raffaella Bottini · @RaffaellaBottini
67 followers · 37 posts · Server sciences.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
RT @sspina@twitter.com
Non perdete il bellissimo volume appena pubblicato da Irene Fioravanti (@UniStraPg@twitter.com) sulle collocazioni lessicali nelle L2. Tre studi empirici mostrano come sia possibile integrare strumenti della linguistica dei #corpora e della psicolinguistica.

Johannes Hentschel · @johentsch
9 followers · 3 posts · Server hostux.socialHi Fediverse, #introduction
Currently I'm spending a lot of my time on the computer researching into #music #corpora in order to finish my #phd @ #epfl by the end of 2023. My main subject is #musicTheory and I'm trying to measure stylistic differences between tonal languages of the last four centuries through #statistics on #harmony (#stylometry).
I'm here to connect with people who are interested in #dh #DataScience #machinelearning #opendata #dataset #foss #privacy #musicianship #funk #techno
#introduction #music #corpora #phd #epfl #musictheory #statistics #harmony #stylometry #dh #DataScience #machinelearning #opendata #dataset #foss #privacy #musicianship #funk #techno

Ártemis López · @queerterpreter
130 followers · 34 posts · Server lingo.lol#Corpus people: an engineer/programmer friend has a project coming up for a class, and they asked if there’s anything they could help with for my diss since they have no good project ideas. They could program something to help with my corpus stuff, turn that in, maybe get an article with me out of it.
Any… any good ideas on what could be generally useful for (ES) #corpora? I can try and come up with something just for me, but it’d be cool if it’s useful for the field at large too.

_dmh · @_dmh
173 followers · 552 posts · Server mastodon.socialSimilarly, you may want a so-called #MeaningRepresentation, some structured representation of the information conveyed by a text or a linguistically motivated semantic representation of the text. These annotations are essential for my work in #NaturalLanguageGeneration / #NLG, and a big struggle for the community is coming up with ways to build #corpora for different tasks, domains, genres, or languages which also have the kinds of MRs our systems use.
#meaningrepresentation #naturallanguagegeneration #nlg #corpora
_dmh · @_dmh
173 followers · 550 posts · Server mastodon.socialFor folks interested in understanding language usage, the lack of information about the #corpora underlying the #LLM/s means that you can't really say what it tells you about a given language. If a construction is highly (im)probable according to the model, does that statistic hold for the #dialect or #genre that you are interested in? Who knows.
_dmh · @_dmh
173 followers · 545 posts · Server mastodon.socialBuilding #corpora (plural of #corpus) requires you to think about what the corpus is supposed to represent. Sometimes that seems straightforward (for example, all the collected works of a given author, group, newspaper, etc) and sometimes it seems almost impossible.
Suppose we want to have a dataset which is representative of the English language. What do we mean by "the" English language? Do we want to capture actual varied language use? Or create a static representation of a given standard?

Ivan Erill · @ivanerill
1 followers · 1 posts · Server mstdn.scienceTootagging away:
#bacteria #genomics #evolution #microbiology #microbes #antibiotics #microbialgenomics #transcription #regulation #promoter #TFbinding #motif #MGE #SOSresponse #stress #PSSM #collecTF #ontology #corpora #evolutionarybiology
#bacteria #genomics #evolution #microbiology #microbes #antibiotics #MicrobialGenomics #transcription #regulation #promoter #TFbinding #motif #MGE #SOSresponse #stress #PSSM #collecTF #ontology #corpora #EvolutionaryBiology