
Nonilex · @Nonilex
780 followers · 3149 posts · Server masto.aiThe #senator asserts that this blanket & #unprecedented “hold,” which he has maintained for >6 months, is about opposition to #Defense Dept #policies that ensure #ServiceMembers & their #families have #access to #ReproductiveHealth no matter where they are #stationed.
After the Supreme Court’s decision in #Dobbs…, this policy is critical & necessary to meet our obligations to the force. It is also fully w/in the #law, as confirmed by the #Justice Dept’s Office of #Legal #Counsel.
#senator #unprecedented #defense #policies #servicemembers #families #access #reproductivehealth #stationed #dobbs #law #justice #legal #counsel

PrivacyDigest · @PrivacyDigest
563 followers · 2133 posts · Server mas.to
Senior #Technologist / Senior #PolicyAnalyst / Senior #Counsel, Elections & #Democracy - Center for Democracy & Technology
WE'RE HIRING:
* Senior Technologist / Senior Policy Analyst / Senior Counsel, Elections & Democracy
* Programme Director, #HumanRights, #Security & #Surveillance Program, @cdteu
* Programme Dir, Equity & Data, @cdteu
Interested? Know someone? RT PLS:
#jobs #thegoodfight
https://cdt.org/job/senior-technologist-senior-policy-analyst-senior-counsel-elections-democracy/
#thegoodfight #jobs #surveillance #security #humanrights #democracy #counsel #policyanalyst #technologist
Nonilex · @Nonilex
762 followers · 3005 posts · Server masto.aiJudge Chutkan said each of the proposed schedules falls outside D.C. federal courthouse norms — & timelines for federal trials in general. She also expressed skepticism about the claims of #Trump’s #lawyers that they need >2years to read & analyze all the #evidence at issue in the #trial.
“Counsel is not #entitled to unlimited preparation time; #counsel is entitled to reasonable preparation time,” #Chutkan said.
#Jan6 #ElectionInterference #Conspiracy #law #legal #justice
#trump #lawyers #evidence #trial #entitled #counsel #chutkan #jan6 #electioninterference #conspiracy #law #legal #justice
Nonilex · @Nonilex
699 followers · 2922 posts · Server masto.ai#Sadow, whose website describes him as a “special #counsel for white collar & high-profile defense,” is well known in #Atlanta #legal circles. His prominent clients include rap artists Rick Ross & T.I., singer Usher & former NFL player Ray Lewis.
Most recently, Sadow represented hip-hop star #Gunna in another sprawling #criminal #racketeering case involving the rapper #YoungThug. That case is also being prosecuted by Willis’s office & is expected to go to #trial in the coming months.
#sadow #counsel #atlanta #legal #gunna #criminal #racketeering #youngthug #trial
Nonilex · @Nonilex
699 followers · 2921 posts · Server masto.ai
Hours before his expected #surrender at the #FultonCounty #Jail, #Trump appears to be shaking up his #Georgia-based #legal team.
Steven #Sadow, a prominent #Atlanta #criminal defense #attorney, filed notice in #FultonCounty Superior Court that he is now representing Trump in the matter as his lead #counsel.
#surrender #fultoncounty #jail #trump #georgia #legal #sadow #atlanta #criminal #attorney #counsel
Nonilex · @Nonilex
687 followers · 2787 posts · Server masto.ai“#Chesebro soon began doing #legal work for #national #Republicans…, joining #Troupis as #counsel for Sens #MikeLee of UT & #TedCruz of TX & others on an amicus brief in the fall of 2018 that backed the UT #GOP in its efforts to assert greater #control over the selection of party nominees.
“He also became a GOP #donor, first that fall to candidates running for federal office in #Wisconsin & then, starting in 2020, to numerous national Republicans. He contributed $2,800 to #Trump’s reelection….
#chesebro #legal #national #republicans #troupis #counsel #mikelee #tedcruz #gop #control #donor #wisconsin #trump

DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
Nonilex · @Nonilex
655 followers · 2655 posts · Server masto.aiThe op describes the #DOJ’s “difficulties” in initially making contact w/ #Twitter — …only recently been taken over by #Musk — to serve the #SearchWarrant. Prosecutors 1st attempted contact…on Jan 17 via its #website for #legal requests but found the page #inoperative. On Jan 19, the co finally connected w/prosecutors but did not immediately #comply w/the warrant. On Jan 25, when prosecutors prodded Twitter again, the company’s #counsel claimed she “had not heard anything about the warrant.”
#doj #twitter #musk #searchwarrant #website #legal #inoperative #comply #counsel

Kailee ♾️ · @skykiss
1550 followers · 1764 posts · Server sfba.social
2. NEW: And now, on a Saturday, (appearing unwilling to waste much time) #Judge Chutkan has given Donald until 5pm ET Monday to respond to the #special #counsel's #motion for a #protective #order following Donald's ostensible threat post on social media:
#judge #special #counsel #motion #protective #order #threats #coup #plotter
Nonilex · @Nonilex
626 followers · 2459 posts · Server masto.aiWoodward is #counsel of record for #Nauta, & for some period of time also #Taveras — it’s unclear if he will continue. Many details in the #SupersedingIndictment leave the strong impression that Taveras is cooperating w/the #SpecialCounsel in some capacity — particularly the evidence surrounding his alleged convos w/ #DeOliveira about the server.
“This is not rocket science,” Gillers said. “You can’t represent a cooperator & someone fighting an #indictment [like Nauta] in the same transaction.”
#counsel #nauta #taveras #supersedingindictment #specialcounsel #deoliveira #indictment
Kailee ♾️ · @skykiss
1483 followers · 1579 posts · Server sfba.socialBREAKING: Two sources with direct knowledge of the situation tells #NBC News that Trump attorneys Todd Blanche and John Lauro are meeting with #prosecutors in the #Special #Counsel's office in Washington and have been told to expect an #indictment against criminal suspect donald Trump for his crimes against America.
#nbc #prosecutors #special #counsel #indictment #law #fedilaw
Kailee ♾️ · @skykiss
1478 followers · 1553 posts · Server sfba.social
NBC News: Former acting Deputy Attorney General Richard Donoghue, who witnessed the discussions by senior Trump admin officials over debunked conspiracy theories and other events tied to #January6th scheme to overturn the #election has been interviewed by the Special Counsel’s Office, he says. He says he has not appeared before the Grand Jury hearing testimony tied to that investigation.
Former Acting #Deputy #AG Donoghue has been interviewed by the #special #counsel. He and Acting AG #Rosen refused to sign Clark’s letter to #GA, and were part of the group that threatened to resign en masse if trump appointed Clark AG. He has not testified before the grand jury.
#January6th #election #deputy #ag #special #counsel #rosen #ga #conspiracy #defraud #crime #lawfedi #fedilaw
DavidV.TV ® · @DavidVTV
5 followers · 1706 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1698 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1697 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2981 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.net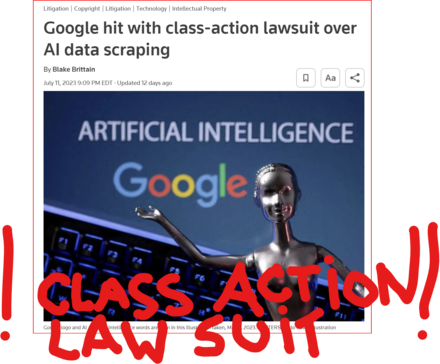
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
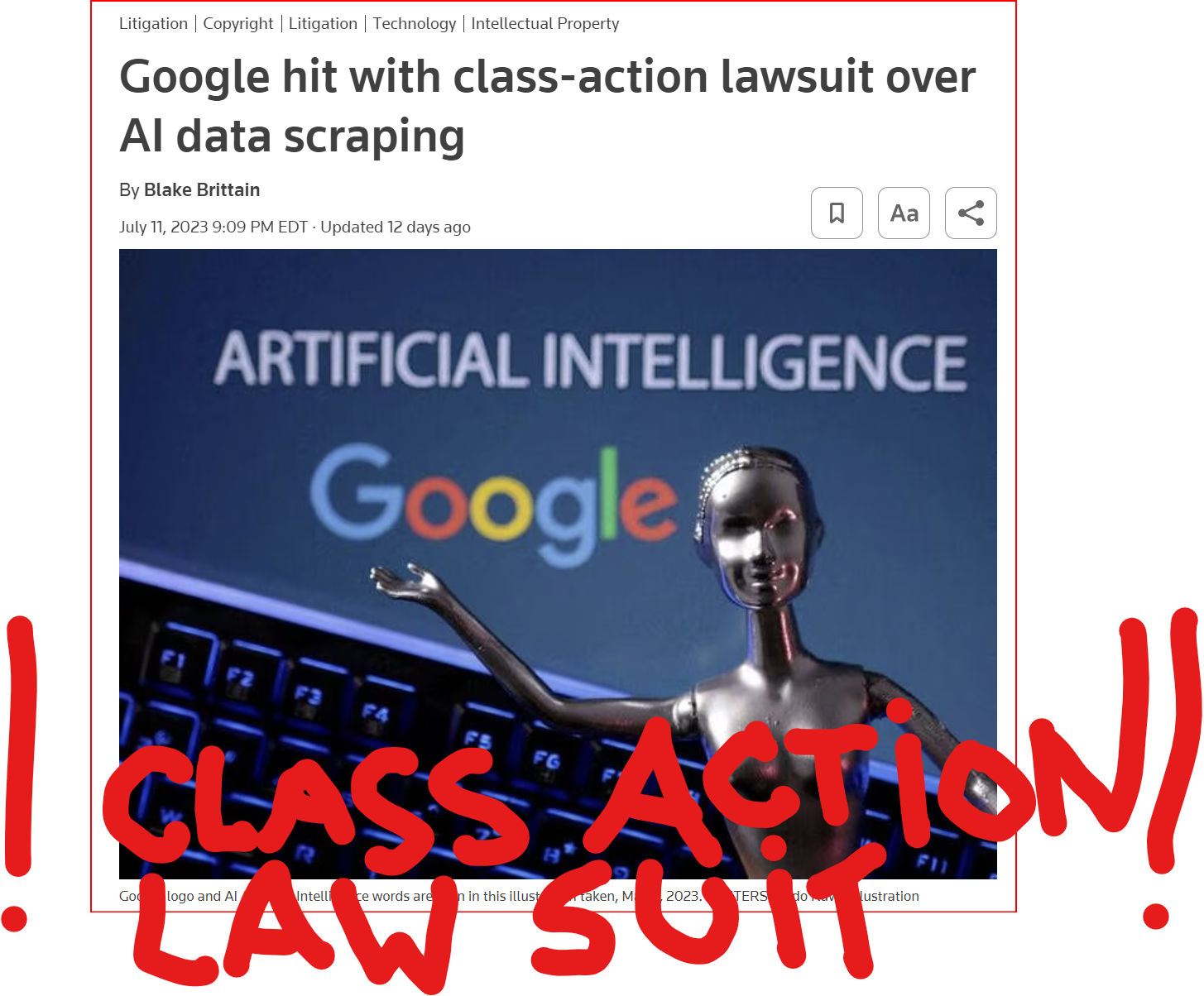
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS