
FiXato · @FiXato
410 followers · 10871 posts · Server toot.cat@textfiles the "categorized as: uncategorized" at the end made me chuckle. 😅
#Discord already allows you to export your own data: https://support.discord.com/hc/en-us/articles/360004027692-Requesting-a-Copy-of-your-Data
But it looks like it will only contain your own messages: https://support.discord.com/hc/en-us/articles/360004957991-Your-Discord-Data-Package
(Though I have yet to request my own archive...)
I guess it's because there's no kind of licensing option where users first have to agree that anything they post can be archived and republished at a later time by the Discord guild's founder. I guess an interim solution could be to have a bot automatically repost content tagged with a specific react emote, or anything pinned, to a private archive channel which would then be included in a periodic data export of the bot owner's account. Of course this still involves unnecessary gatekeeping, as the bot would need to be run by the guild's founder.
I remember being frustrated about this with the demise of #GooglePlus too; while it's nice to have an export of my own posts and comments, it also is incomplete; what made some of those posts actually valuable was the input from others, the discussions, the agreements and counterpoints.
I suspect this part of #DataLiberation is something that needs work across all platforms, including here on #Mastodon and in the extended #Fediverse. Allowing users to attach a license (likely a #CreativeCommons one) to their posts, so #DataExport options can also automatically include replies, or other relevant content contributed by community members on a third party platform, without potentially violating #DataPrivacy regulations such as the #GDPR.
(Which makes me wonder what the current state is of #TimBernersLee's #SOLID (https://solidproject.org/) project...)
#discord #googleplus #dataliberation #mastodon #fediverse #creativecommons #dataexport #dataprivacy #gdpr #timbernerslee #solid

coldclimate · @coldclimate
235 followers · 594 posts · Server hachyderm.ioI'm interested in getting at the data on my #kindle
Not the DRMd books, but when and how much I read. I'm 99% sure my old paperwhite is recording this stuff and squirting it home when it come out of airline mode (where it lives).
Google isn't finding much, anybody here doing any #dataLiberation?

Martin Raue (he/him) 🕹⌨️🌌 · @_rmrtn
41 followers · 46 posts · Server mastodon.gamedev.place
FiXato · @FiXato
393 followers · 9413 posts · Server toot.cat
{kind=link}
{kind=link}
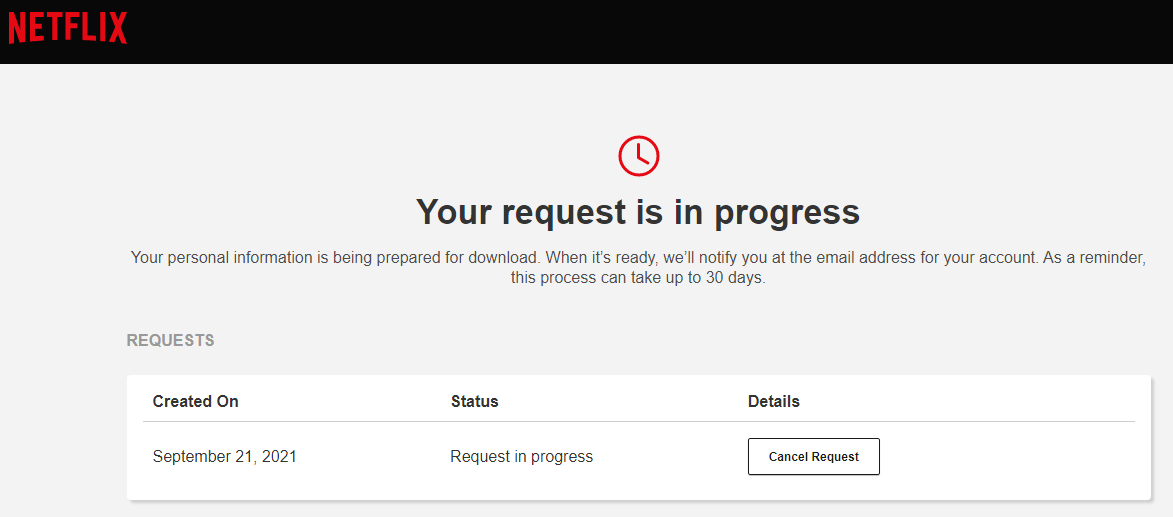
Pff... that #Netflix #DataTakeout request is taking even more time than my #GooglePlus #DataLiberation request took during the worst of its time...
No progress indication either.
Also, it can take up to 30 days? What are they doing? Sending a bunch of rats through a hex maze, looking for the cheese? Manually polishing every byte?
#netflix #datatakeout #googleplus #dataliberation
FiXato · @FiXato
393 followers · 9413 posts · Server toot.catHere's your periodic reminder to #backup your #SocialMedia profiles by using their relevant #DataLiberation options. :)
For #Mastodon that is usually at https://your.instance.example/settings/export
#Twitter has an export option at https://twitter.com/settings/download_your_data
#Google's services are just about all consolidated at their #GoogleDataTakeout at https://takeout.google.com/
#Instagram's available at https://www.instagram.com/download/request/
#backup #socialmedia #dataliberation #mastodon #twitter #google #googledatatakeout #instagram
FiXato · @FiXato
393 followers · 9413 posts · Server toot.catOkay, so I got a rudimentary first version of #TootPortal working, which is yet another #ScratchYourOwnItches #PetProject.
It allows me to create a directory structure with simple #markdown files in it, which will be converted into #HTML, where each list item that refers to a toot URL (for now only Mastodon style URLs with numeric IDs are supported), gets expanded to the bare minimum content of that status, along with (optionally) any replies to it.
#TootPortal #ScratchYourOwnItches #PetProject #markdown #html #coding #dataMassaging #dataliberation