
Pierre Monnin · @piermonn
29 followers · 23 posts · Server sigmoid.socialPyGraft will help you generate new and tailored benchmark KG #datasets useful in various fields including but not limited to #neurosymbolicAI, #linkPrediction, #nodeClassification, #nodeClustering, #ontology repairing, pattern mining, reasoning, scalability studies, etc.
Feel free to download, star, fork, share and tell us about any usage you foresee! We welcome all contributions or ideas to improve PyGraft! Looking forward to feedback from #semanticWeb #machineLearning and other communities!
#datasets #NeuroSymbolicAI #linkprediction #nodeclassification #nodeclustering #ontology #semanticweb #machinelearning

Jo Tiffe · @Jo_designart
7 followers · 80 posts · Server digitalcourage.social
Heute um 17:30h ist die Finissage von https://techturk.form-f.art. Kommt vorbei: Lausitzer Str. 10, Sonnenhof.
Es gibt neues zu sehen + zu hören.
#techturk #foto #ml #machinelearing #algorithms #datasets #datamining
#datamining #datasets #algorithms #machinelearing #ml #foto #techturk

New Submissions to TMLR · @tmlrsub
208 followers · 773 posts · Server sigmoid.social
Unlocking Unlabeled Data: Ensemble Learning with the Hui-Walter Paradigm for Performance Estimation in Online and Static Settings
Jo Tiffe · @Jo_designart
7 followers · 80 posts · Server digitalcourage.social
Es war eine total schöne Vernissage, falls noch jemand aus Berlin Lust hat vorbei zu kommen: am 7.Sept., 17:30 ist Finissage, mehr noch mehr Arbeiten.
#techturk #fairytaleof5seaurchins #maerchenvon5eeigeln #algorithms #datasets #dataminig #berlin #stablediffusion
Foto:© Volker Hoffmann
#stablediffusion #berlin #dataminig #datasets #algorithms #maerchenvon5eeigeln #fairytaleof5seaurchins #techturk

Miguel Afonso Caetano · @remixtures
727 followers · 2825 posts · Server tldr.nettime.org#AI #GenerativeAI #ML #Algorithms #DataSets: "Ultimately, when we think about what a more ethical development of this technology could look like, I think it looks a lot like machine learning before 2015, or before the last 10 years. It looks like building systems for specific purposes with specific scopes and with specific goals. Then you can start to ask questions like “What values do we want the system to reinforce?” “What data makes sense to use here?” It’s the opposite of the “move fast and break things” philosophy. It’s really hard to advocate for that kind of work because it’s not flashy. It’s frustrating because I think none of this was inevitable. We’ve been talking about it in the field for ages, these issues with general or universal AI systems. I think one of the biggest arguments that we make at DAIR is that we don’t need to be building systems this way, we do not need to be making general purpose AI, we don’t need to be making these kinds of generative AI systems. It’s really hard to go down this line of work without independent funding, because that’s not where the money is right now."
#ai #generativeAI #ml #algorithms #datasets

Published papers at TMLR · @tmlrpub
564 followers · 596 posts · Server sigmoid.social
WOODS: Benchmarks for Out-of-Distribution Generalization in Time Series
Jean-Christophe Gagnon-Audet, Kartik Ahuja, Mohammad Javad Darvishi Bayazi et al.
Action editor: Antoni Chan.
#generalization #generalize #datasets

SICB journals(ICB & IOB) · @SICBJOURNALS
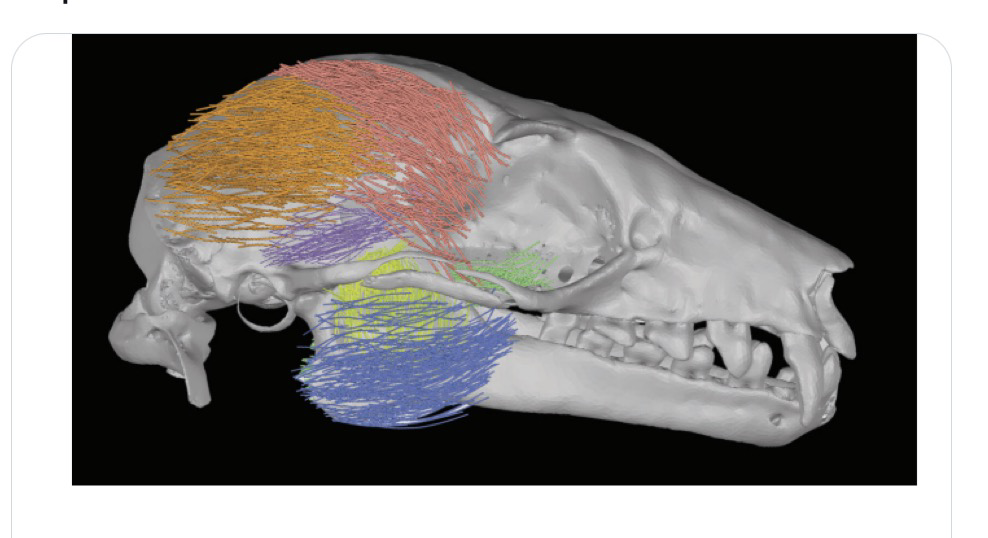
50 followers · 111 posts · Server earthstream.social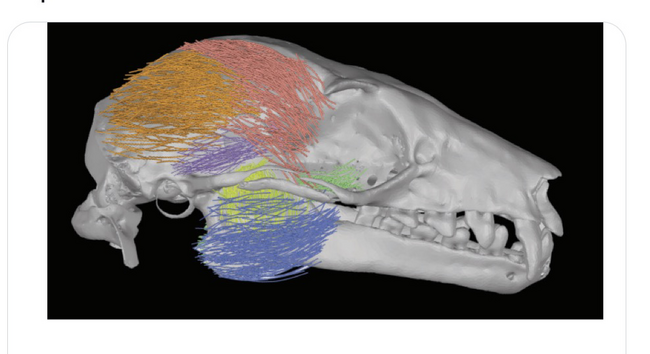
IOB Friday fresh ink
GoodFibes: An R Package for The Detection of #Muscle Fibers from #diceCT Scans
J H Arbour
https://doi.org/10.1093/iob/obad030
"We hope that this will increase the number of comparative and #evolutionary studies incorporating these rich and functionally important #datasets.
#muscle #dicect #evolutionary #datasets

Tarun Gupta · @tarungupta
5 followers · 125 posts · Server me.dm
🧠💡 Level up your data skills! Dive into the Curse of Dimensionality and learn how high dimensionality affects data analysis. 📈📊 Don't let the complexity stop you from becoming a great #DataScientist or #ML Engineer! 🚀💪 #DataSets #CurseOfDimensionality
#datascientist #ml #datasets #curseofdimensionality

NFDI4Microbiota · @NFDI4Microbiota
42 followers · 19 posts · Server nfdi.social
❓Confused about #FAIR, #ontologies, and #metadata and how they can help you and your #datasets?
❗️Begin with our hands-on workshop about the description of biological data.
🗓️16-17 October in Aachen. Register by 20 September: https://tinyurl.com/biome01
#microbiology #NFDIrocks
#fair #ontologies #metadata #datasets #microbiology #nfdirocks
New Submissions to TMLR · @tmlrsub
203 followers · 731 posts · Server sigmoid.social
Learning domain-specific causal discovery from time series

SPAAM-community · @spaam_community
16 followers · 11 posts · Server genomic.social💻 AMDirT facilitates automated metadata curation and data validation, as well as rapid data filtering and downloading. Together, both standardised metadata and tooling will help towards easier incorporation and reuse of public #ancient #metagenomic #datasets into future analyses. 📊
#ancient #metagenomic #datasets
Miguel Afonso Caetano · @remixtures
670 followers · 2632 posts · Server tldr.nettime.org#AI #Datasets #FacialRecognition #ML #CC #CreativeCommons #Flickr #Nvidi: "Flickr Faces High-Quality (FFHQ) is a dataset of Flickr face photos originally created for face generation research by NVIDIA in 2019. It includes 70,000 total face images from 67,646 unique Flickr photos. Since its release the dataset has become of the most widely used face datasets for a wide variety of research and commercial applications ranging from face recognition to oral region gender recognition. The images in FFHQ were taken from Flickr users without explicit consent and were selected because they contained high quality face images with a permission Creative Commons license. Many of the images contain infants and children and over 10% of the dataset no longer exists on the original source yet NVIDIA, a $1T company, continues to use and benefit from the 70,000 face images taken on Flickr.com to develop commercial AI technologies.
(...)
Even though the main dataset and its derivatives mention the Creative Commons licenses associated with the media, of which many require attribution, no human readable attribution was provided for any photo in any dataset. Attribution is only provided in a 256MB JSON file that could not be opened on a standard laptop computer using Sublime text editor, let alone parsed to understand author attribution. This may amount to a large-scale breach of the Creative Commons attribution requirement. For further reading on the exploitation of Creative Commons licensing scheme, read "Creative Commons and The Face Recognition Problem". To further complicate the issue, it may not be possible at all to use non-consensual face images for AI/ML when attribution is required because including the subject or author name can force the face photo to become PII (personally identifiable information), a protected class of data."
#ai #datasets #facialrecognition #ml #cc #creativecommons #flickr #nvidi

Paul R. Pival (he/him) · @ppival
145 followers · 290 posts · Server glammr.usData from U.S. 2020 Presidential Election Facebook and Instagram Study Now Available at ICPSR https://www.icpsr.umich.edu/web/about/cms/5024
#SocialMedia #Meta #Facebook #Instagram #datasets #Election2020
#socialmedia #meta #facebook #instagram #datasets #election2020

Picanúmeros · @Picanumeros
1772 followers · 776 posts · Server mathstodon.xyz
Miguel Afonso Caetano · @remixtures
671 followers · 2621 posts · Server tldr.nettime.org#AI #DataSets #AIEthics: The Google memo points to the dawning realization that improvements in AI will require putting a lot more care and thought into how data is collected and curated. Even OpenAI, which relies on gargantuan datasets to make its products, is now pointing to this issue. A close engagement with datasets has been deeply undervalued in the AI field, and this neglect has had serious consequences downstream, from technical failures to human rights violations.
This is why investigating datasets is so important. Not because companies want an edge in the current AI wars, but to understand the ideologies, viewpoints, and harms that are being ingested, concentrated, and reproduced by AI systems. The new internet-scale datasets require new investigative methods, new research questions. What political and cultural inflections are baked into training sets? Who and what is represented? What is rendered invisible and unintelligible? Who profits from all this data, and at whose expense? What legal issues does the mass extraction of data raise for copyright, privacy, moral rights, and the right to publicity? What about the people whose creative work and livelihoods are impacted? How could these practices change? And as the accelerating machines of scrape-generate-publish-repeat begin to ingest their own material, what logics, perspectives, and aesthetics will be reinforced in this recursive loop?"
https://knowingmachines.org/9-ways-to-see/9-ways-to-see-a-dataset

George Macgregor · @g3om4c
429 followers · 356 posts · Server code4lib.socialA useful study as it provides direction for corrective action; but in the meantime its findings reinforce a reality (rather than perception) that responsible #OpenResearch can have few academic incentives.
"the vast majority of #datasets have no recorded citations, & most cited datasets only have a single citation... #data sharing will rarely lead to replication or new knowledge production that can be identified through a formal #citation"
https://arxiv.org/abs/2308.04379 #FAIRdata #OpenData
#openresearch #datasets #data #citation #fairdata #opendata
New Submissions to TMLR · @tmlrsub
200 followers · 717 posts · Server sigmoid.social
On the Efficacy of Differentially Private Few-shot Image Classification

LaPingvino 🟙 :ir: · @lapingvino
302 followers · 2085 posts · Server neurodifferent.meThrough a look into the things people were saying about the upcoming Go 1.21 release I discovered #doltdb and #dolthub today. I have been looking for ages for something like that:
A #mysql compatible database system that works like #git for data, and a #github like environment for #datasets, free for public datasets.
For people here struggling with #healthcare in the #USA: one of the projects they are working out there is a dataset of pricing per hospital and data-based work to push for more and better policy reform around this. I think we can do MUCH better if we have good #data, and now we have a platform to share and work together about data, so let's use it!
#doltdb #dolthub #mysql #git #GitHub #datasets #healthcare #USA #data

Leonardo Grando · @lgrando123
119 followers · 437 posts · Server sciencemastodon.com
Published papers at TMLR · @tmlrpub
551 followers · 541 posts · Server sigmoid.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mitigating Real-World Distribution Shifts in the Fourier Domain
Kiran Krishnamachari, See-Kiong Ng, Chuan-Sheng Foo
Action editor: Hanie Sedghi.
#fourier #adaptation #datasets