
Leshem Choshen · @LChoshen
1091 followers · 383 posts · Server sigmoid.social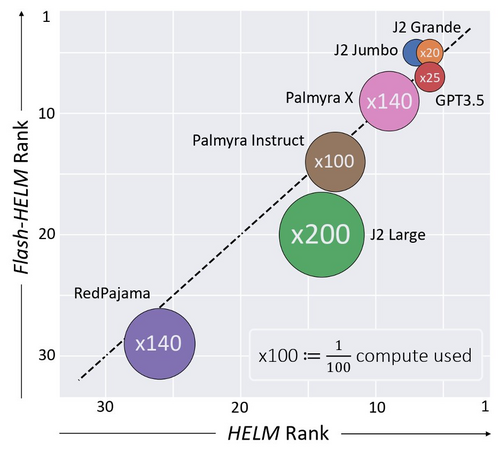
Did you know:
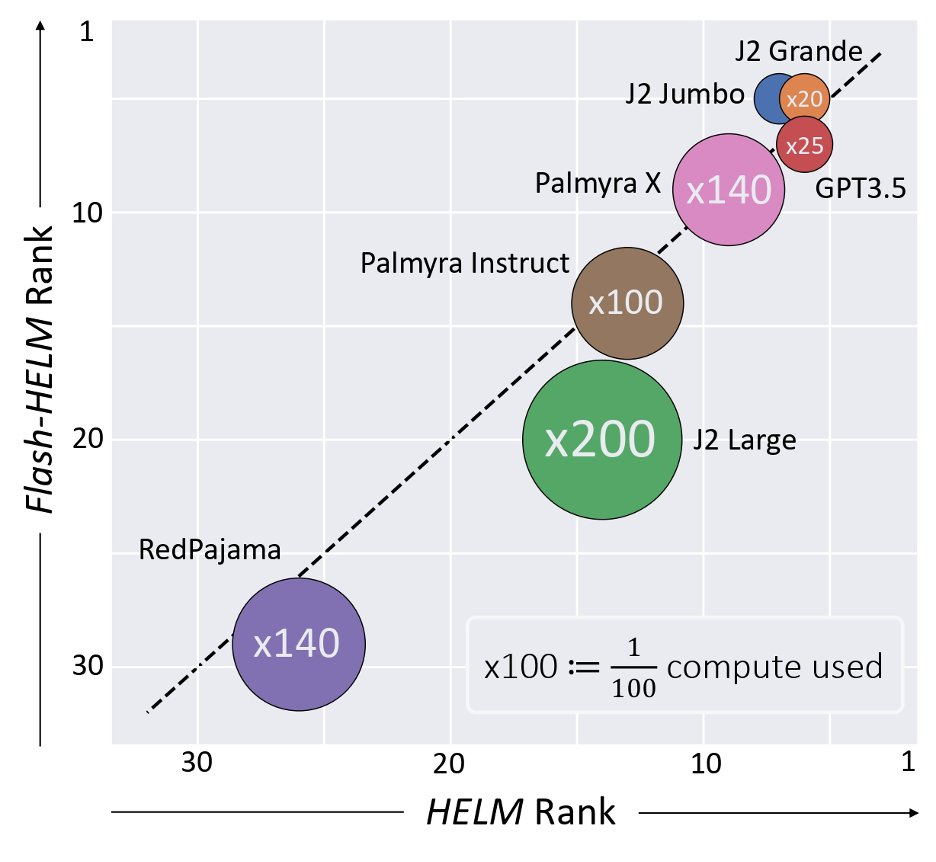
Evaluating a single model on HELM took
⏱️4K GPU hours or 💸+10K$ in API calls?!
Flash-HELM⚡️can reduce costs by X200!
https://arxiv.org/abs/2308.11696
#deepRead #machinelearning #evaluation #eval #nlproc #NLP #LLM
#deepread #machinelearning #evaluation #eval #nlproc #nlp #llm
Leshem Choshen · @LChoshen
1086 followers · 353 posts · Server sigmoid.social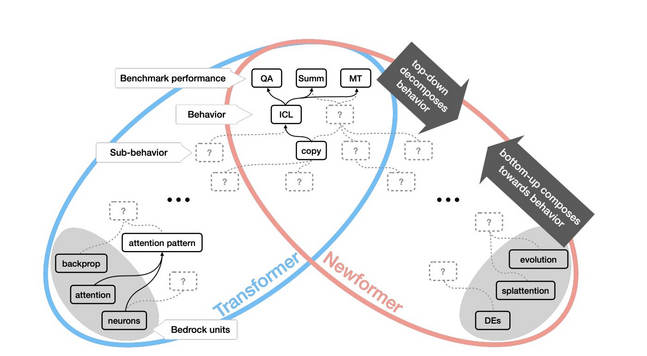
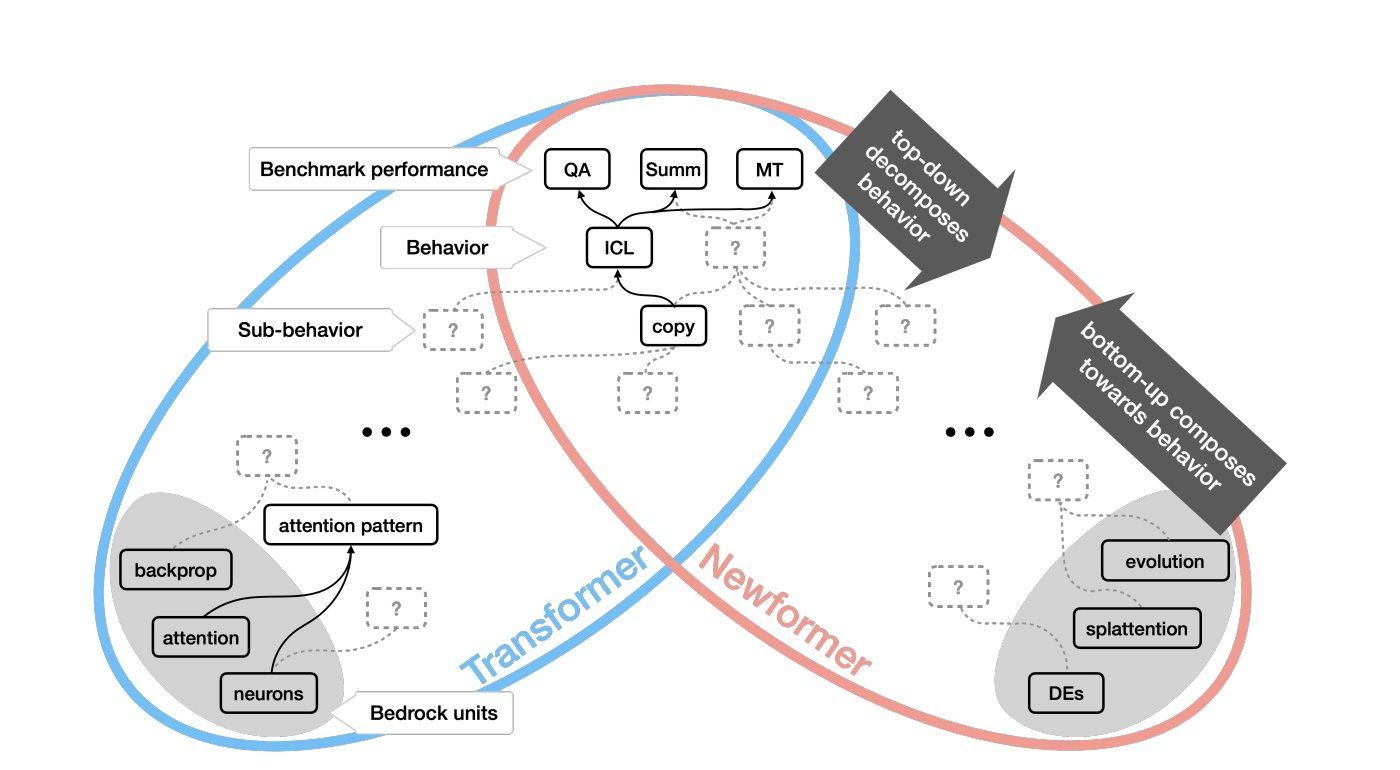
The newFormer is introduced,
but what do we really know about it?
@ari and others
imagine a new large-scale architecture &
ask how would you interptret its abilities and behaviours 🧵
https://arxiv.org/abs/2308.00189
#deepRead #NLProc #MachineLearning
#deepread #nlproc #machinelearning
Leshem Choshen · @LChoshen
1007 followers · 277 posts · Server sigmoid.social@mega Linear transformations can skip over layers, even till the end
We can see 👀 what the network 🧠 thought!
We can stop🛑 generating at early layers!
Leshem Choshen · @LChoshen
1007 followers · 271 posts · Server sigmoid.social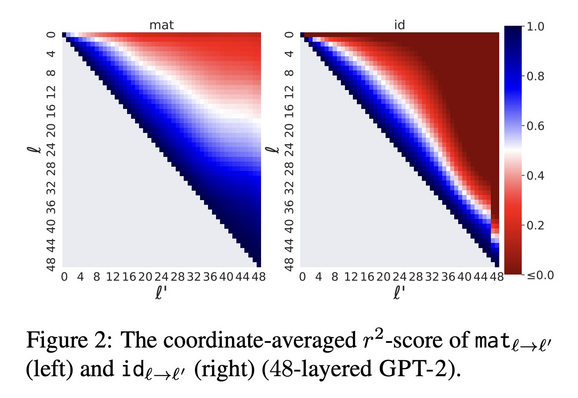
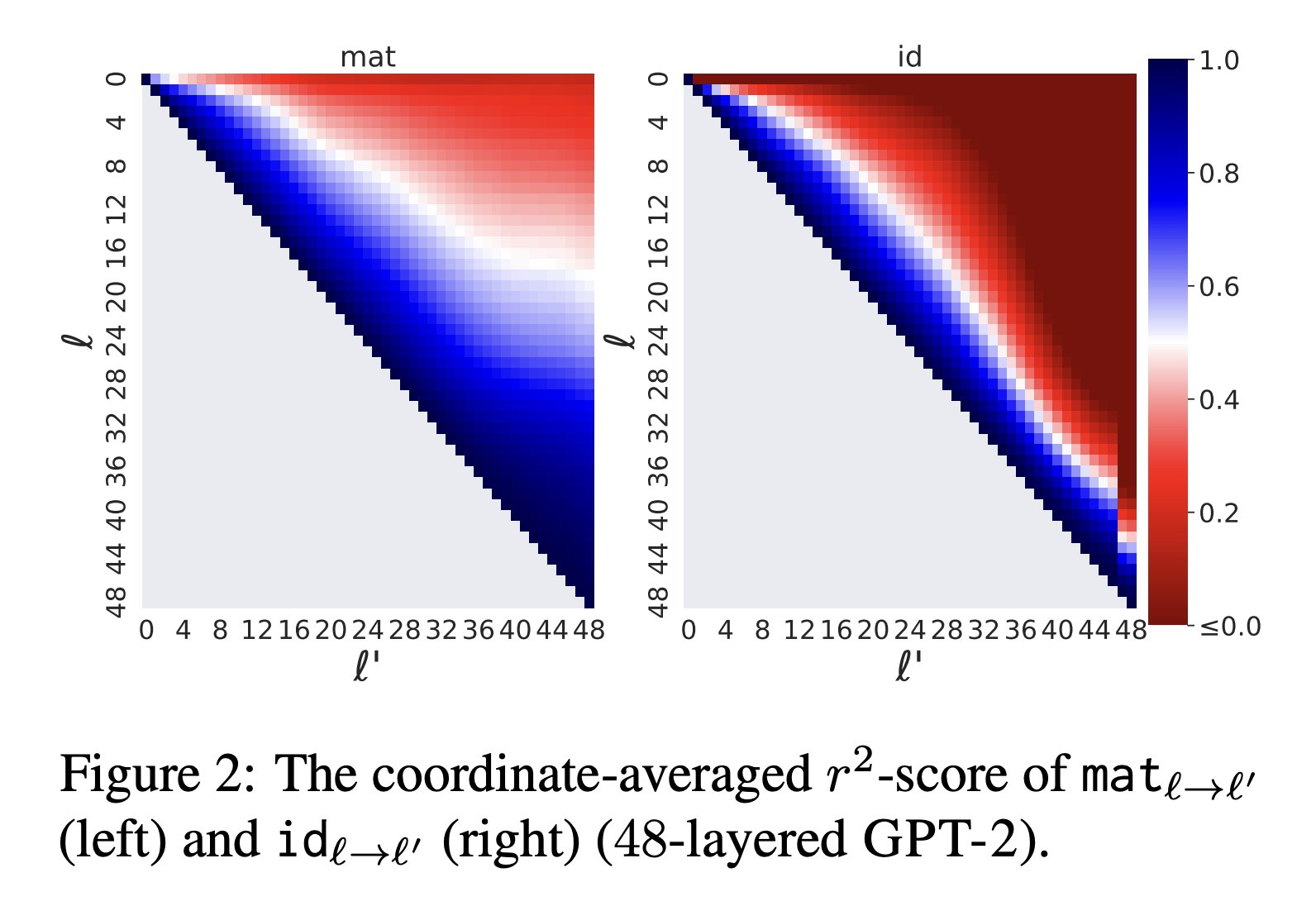
🔎What's in a layer?🌹🕵🏻♀️
Representations are vectors
If only they were words...
Finding:
Any layer can be mapped well to another linearly
Simple, efficient & interpretable
& improves early exit
https://arxiv.org/abs/2303.09435v1
Story and 🧵
#nlproc #deepRead #MachinLearning
#nlproc #deepread #machinlearning
Leshem Choshen · @LChoshen
1004 followers · 260 posts · Server sigmoid.social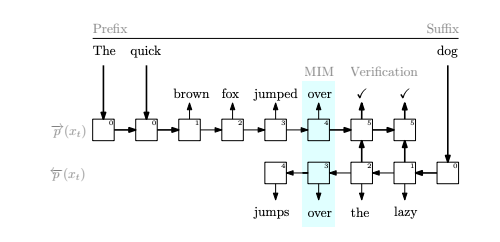
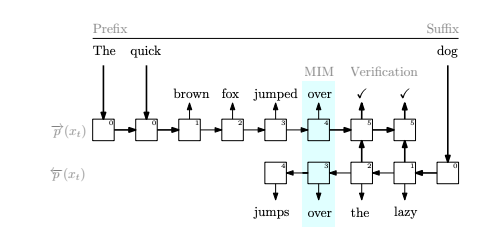
Mindblowing pretraining paradigm
Train the same model to predict the two directions separately
Better results, more parallelization
https://arxiv.org/abs/2303.07295
#deepRead #nlproc #pretraining #machinelearning
#deepread #nlproc #pretraining #machinelearning
Leshem Choshen · @LChoshen
948 followers · 184 posts · Server sigmoid.social
3 reasons for hallucinations started
only 2 prevailed
Finding how networks behave while hallucinating, they
filter hallucinations (with great success)
https://arxiv.org/abs/2301.07779
#NLProc #neuralEmpty #NLP #deepRead
#nlproc #neuralempty #nlp #deepread
Leshem Choshen · @LChoshen
756 followers · 114 posts · Server sigmoid.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
What neurons determine agreement in multilingual LLMs?
#deepRead but some answers:
Across languages-2 distinct ways to encode syntax
Share neurons not info
Autoregressive have dedicated synt. neurons (MLM just spread across)
@amuuueller@twitter.com yu xia @tallinzen@twitter.com #conllLivetweet2022