
fistons :rust: :java: :godot: · @fistons
38 followers · 146 posts · Server fosstodon.org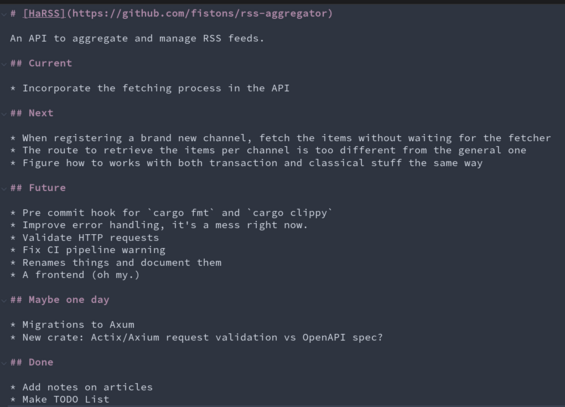
Some progress was made!
I will now merge the fetching process in the API.
For now I have a separate crate doing this, and it's cron scheduled. For a project this small, I think I can just create a scheduled task in the API.
I have implemented a kind of mutex to prevent fetching the same feed several times at the same time, so having several instance of the API won't be an issue.
Thanks @catsalad for the done item idea!
#rss #rust #rustlang #api #devdiary #harss
fistons :rust: :java: :godot: · @fistons
36 followers · 144 posts · Server fosstodon.org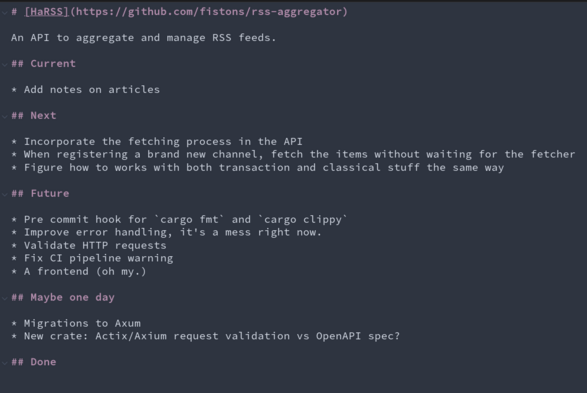
As predicted, I added a new item on my #todo list before finished one, BUT I have almost finished the current one so that's fine
With this, a user will be able to add notes (in #markdown of course) on an article he reads. A feature I found on #inoreader and even I never used it myself, it may prove useful and it's pretty cheap to implement.
#todo #markdown #inoreader #rss #rust #rustlang #api #devdiary #harss

papel · @papel
5 followers · 53 posts · Server baraag.netI'm making a game on #Godot again! This time it's a platformer, stage based, it has enough working "features" for me to think about some interesting level design.
[Here's a more in-depth detail on my idea](https://f95zone.to/threads/sharing-my-current-great-idea-just-because.171385/), 500 characters is too little for this.
#godot #eroge #porngame #hentaigame #devdiary

Crusader Kings III News · @ck3news
60 followers · 35 posts · Server techhub.social
📜#DevDiary #134: The Art of Wards & Wardens.
🔗 https://store.steampowered.com/news/app/1158310/view/6786414309893211830
#ParadoxInteractive #CK3 #CrusaderKings #CrusaderKings3 #VideoGames #Gaming #LinuxGaming
#devdiary #paradoxinteractive #ck3 #crusaderkings #crusaderkings3 #videogames #gaming #linuxgaming
Crusader Kings III News · @ck3news
58 followers · 34 posts · Server techhub.social
📜#DevDiary #133 - Wet Nurses.
🔗 https://store.steampowered.com/news/app/1158310/view/3665419040610337757
#ParadoxInteractive #CK3 #CrusaderKings #CrusaderKings3 #VideoGames #Gaming #LinuxGaming
#devdiary #paradoxinteractive #ck3 #crusaderkings #crusaderkings3 #videogames #gaming #linuxgaming
Crusader Kings III News · @ck3news
58 followers · 33 posts · Server techhub.social
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
📜#DevDiary #132: Eccentricity & Adoption.
🔗 https://store.steampowered.com/news/app/1158310/view/3665418406998793973
#ParadoxInteractive #CK3 #CrusaderKings #CrusaderKings3 #VideoGames #Gaming #LinuxGaming
#devdiary #paradoxinteractive #ck3 #crusaderkings #crusaderkings3 #videogames #gaming #linuxgaming

Anthea is lighting the way · @TheRealAnthea
35 followers · 188 posts · Server mstdn.partyIn today's #DevDiary for #TheLamplightersLeague, you get to meet one of my favorite scary people: Lady Zorana Nicastro. #ParadoxInteractive #HarebrainedSchemes #GameDev
https://forum.paradoxplaza.com/forum/developer-diary/dev-diary-6-banished-court-scions-monsters.1579751/
#devdiary #thelamplightersleague #paradoxinteractive #harebrainedschemes #gamedev

¡a!n · @iain
163 followers · 1306 posts · Server kolektiva.socialUpdated my #DevDiary finally, explaining how I've come to understand #ViewModels in the context of #SwiftUI and how it's made #Fieldwork much nicer to develop and preview
#devdiary #viewmodels #swiftui #fieldwork

PROJEKT CH+ · @projektchplus
24 followers · 21 posts · Server swiss.social⬇️ #devDiary The Book of Jokes ⬇️
You know that moment when you're using a random joke to decide what #civictech app feature to develop next?
... ...
Neither do we!
...
Because we do workshops with people from all parts of Switzerland to determine new app features. 😎😎😎😎😎😎😎😎
But book quotes are nice for good vibes in the office. Follow along to see what we develop next. 😉
#development #books #quotes #ostern #office #coworking #projektchplus
#devdiary #civictech #development #books #quotes #ostern #office #coworking #projektchplus

Tamás · @sashee
1 followers · 16 posts · Server infosec.exchangeI'm working on the VTL=>JS rewrite of my AppSync book. It's a monumental project on its own, I need to change something like 1/3 - 1/2 of the book, and also learn the nuts and bolts of a new approach for AppSync resolvers.
What happens a lot is that I have plenty of ready-to-deploy code examples. To update a chapter, I usually just need to update the code, deploy, fix anything broken, and then just copy-paste the changed codes. But this is only possible as I already made the investment of coming up with deployable codebases.
Tamás · @sashee
1 followers · 16 posts · Server infosec.exchangeI'm making some good progress on rewriting my book from AppSync VTL to Javascript. After a few chapters it's mostly mechanical.
Though I find it strange that so many things are missing from the AppSync JS support that is possible in VTL. For example, the RDS data source documentation and the util.rds util documentation is missing while both are implemented. Also, the omission of the early return (#return in VTL) makes it awkward to work around. For example, to skip a DDB getItem, the best I could come up with is to get an item that does not exist and then discard the result. It is functionally equivalent but also wasteful.
Tamás · @sashee
1 followers · 14 posts · Server infosec.exchangeAppSync recently added support for Javascript resolvers. This is a huge step forward: VTL, the previous way, was never suitable for this purpose and was a nightmare to use. Javascript is a good choice here, as sometimes there is a need for some complex-ish logic but not too much.
I waited a few months to give the AWS team time to iron out the details, but it seems like some features won't be implemented any time soon that are supported by VTL. For example, the early return and unit resolvers are painfully missing from the feature set.
But now I decided to stop waiting and started rewriting a huge chunk of my AppSync book to Javascript resolvers. My plan is to eliminate every reference to VTL and teach only JS; while VTL has some extra features, anybody who is learning AppSync should just concentrate on the JS part.
I'll need to work on this rewrite a lot, it affects ~40% of the book and many code examples. But I believe the end result will be something that is way easier (and up-to-date) for anyone learning AppSync. And who knows, maybe by the time I finish, the AWS team finishes the missing features.
Tamás · @sashee
1 followers · 14 posts · Server infosec.exchangeInfosec mastodon seems to have a bad day, it took me minutes to log in. Hope this message will go out just fine after I'm finished writing it.
I failed miserably on my quest to write a nice TUI. I tried really hard but it seems like the tooling is not there yet. My primary choice was ink, which is React-based and in my experience defining interfaces declaratively is way more expressive and maintainable after the "Hello world" than the imperative approach. So I started with that.
In my mind I wanted to do a nice table with the currently added coupons where I can select and delete them, and also to add new ones. Well, that requires a table. Fortunately, there is an ink table component that looks nice. Second, I wanted a way to select a row in that table. Well, that's not easy: while there is a customizer for cells, that does not get the row number. Ok, but a CLI table is not that complicated, I could write my own table.
But then came the hard part: what if the table has too many elements for one screen? Then I should be able to scroll it. And that turned out to be a hugely difficult task to implement on itself.
And this is the end of my attempt on a nice user interface. Instead, I pivoted to a series of questions with the prompts library and was done in an afternoon.
The funny thing is that back in the DOS era we used TUIs all the time. Turbo Pascal comes into my mind as the de-facto IDE of that time. It had the basic blocks: a top-row menu, scrolling containers, selections. Seems like the JS ecosystem is slowly catching up with a long way left to go. Maybe next year I'll give it another try.
Tamás · @sashee
1 followers · 11 posts · Server infosec.exchangeToday and probably the next few days I'm writing a TUI (terminal user interface). I've recently added coupon support for my book and that works by adding a row to a DynamoDB table. While that can be done manually, I decided to dive deeper into how to make a nice interface for that so I'm learning the nuts and bolts of terminal-based apps.
I researched a bit and found 3 libraries that I could use:
* https://www.npmjs.com/package/terminal-kit
* https://www.npmjs.com/package/ink
* https://github.com/kenan238/reblessed
I started with ink and it seems nice. I still need to figure out how to make it properly full-screen and how to draw a nice table, but the basics are working.
Interestingly I started with TypeScript but then gave it up. My initial setup was using ts-node and ts-node-dev but then there were some strange problems with modules. So I ditched types for now and use React + htm, so there is no compile step needed.
I'm really looking forward to a hassle-free TS experience, but every time I try it does not seem to be there. Compared to the plain js "just works", I seem to bump into issue after issue when adding types. Maybe next time then.
Tamás · @sashee
1 followers · 8 posts · Server infosec.exchangeThe main thing I did today is to implement an RSS feed for my book platform. Since I already has a structured changelog (https://graphql-on-aws-appsync-book.com/changelog/) it is just a matter of formatting it as XML and serve at rss.xml. While I'm there, I also implemented the Atom feed, which is pretty much the next version of RSS.
I like to at least skim the specifications when I'm working with a specific technology. Tutorials are good, but in my experience I have a ton of questions that are in the specs. For RSS, I was mainly interested in the required fields for the channel and the items so I searched and opened the spec. Not every day I see something like this (https://www.rssboard.org/rss-specification):
> The purpose of the <textInput> element is something of a mystery. You can use it to specify a search engine box. Or to allow a reader to provide feedback. Most aggregators ignore it.
Another thing is that the dates are required to be in RFC 822 format instead of the more commonly used ISO 8601.
On a separate track, I sent the advancedweb.hu newsletter early *again*. Usually, I write the email during the week and schedule it for Sunday night but this time it went out Friday night instead. I don't know what I'm misconfiguring but this is probably the 3rd or 4th time this happens.
¡a!n · @iain
138 followers · 832 posts · Server kolektiva.socialI think I'm done with scrolling, got a big performance boost by not switching pages two times for every tile
(It doesn't tear on screen, thanks giphy capture.)
#devdiary #SAMCoupe #retro #gamedev
Tamás · @sashee
1 followers · 7 posts · Server infosec.exchangePuppeteer can emulate media features, such as the prefers-reduced-motion. It's easy to set:
await page.emulateMediaFeatures([{name: "prefers-reduced-motion", value: "reduce"}])
TIL that the reduced-motion turns off smooth scrolling so that when the browser opens at a heading (with url#fragment) there is no movement at the page, the scroll is set from the first frame. Perfect for making screenshots.
Tamás · @sashee
1 followers · 7 posts · Server infosec.exchangeTIL that the HTML image element has a decode() function that returns a Promise. I noticed that some SVGs were shown as broken images and it turned out that they had missing xmlns attributes. Then Chrome showed them as undecodable.
I wanted to make a checker that detects these broken images. This is when I found the decode() as that rejects if the SVG is invalid.
This is all good, but it seems like it's strangely broken for srcset. When I run the decode() it fulfills successfully, but upon page load it rejects. Unfortunately, I couldn't find an event after which the decode() works reliably.
Tamás · @sashee
1 followers · 7 posts · Server infosec.exchangeWhen I work on my books, I don't just write new content but also make my book platform better. When I started out, all I wanted was to have a way for me to write Markdown and have something generate PDF to me. Then I included EPub generation at some point with a lot of workarounds for Kindle mostly. Now the platform also generates a website with the site.
Lately, I've been working off some technical debt about the platform. When I started, all code and books were in the same repository. This is clearly not a good long-term solution, but was a simple way for starting out. Now I'm making a move to separate the platform from the book. One repository is the platform code and there are individual repos for each book. The platform itself is more of a dependency (a git submodule) to the actual book.
Now I (hopefully) finished the deployment part of that. It includes a Terraform module for the platform that the individual books can import and use. In the process, I learned a bit about Terraform variable validations and that there is no short-circuiting with && and ||.
Tamás · @sashee
0 followers · 2 posts · Server infosec.exchangeSo, I'm starting a (mostly) write-only developer journal. I read about Carmack's plan files when he was working on Quake and it seems like a nice idea to build things on public. Also, it's easy to forget what I worked on even last week, so something that resembles a journal might be interesting to look back on.
Moreover, I wanted to share progress on the various books and other projects I'm working on. I'm writing a book about AppSync at the moment, and I'm full of ideas for future topics. This is usually what a blog is for, but mine is full of long-form content. So I was looking for a place to start something else, and here I am.
The things I'll post here will be short and not overly specific. Then I'll see where it goes and how it evolves.
Why infosec? I had to choose an instance and probably this has the most eyeballs for security. So, even for public posting, why not choose the most secure one?
I'll use the hashtag #devdiary for posting. Maybe I'll post different things and keeping things organized seems like a good idea.