
Osunderdog · @Osunderdog
15 followers · 115 posts · Server allthingstech.socialWell, turns out I needed to upgrade #duckdb from v0.7.1 to v0.8.1. Also had to tell duckdb to install mysql extension.
Badda Bing 5.5m records streaming at me. Wonderful.
Osunderdog · @Osunderdog
15 followers · 113 posts · Server allthingstech.socialI like to follow through language training books. Currently reading a lot about #rust. Anyway, at some point I jump off the curated path and try something on my own.
I end up stuck in the mud reading a bunch of technical documents. Today it is "How to get #duckdb linked in to a rust example?"

Andrea Borruso · @aborruso
237 followers · 224 posts · Server mastodon.uno
Per avere in #duckdb sempre precaricata una o più estensioni, basta creare/modificare il fil ~/.duckdbrc

Thomas Sandmann · @thomas_sandmann
366 followers · 1147 posts · Server genomic.socialToday I learned how to use Pagès’s awesome {DelayedArray} @bioconductor package to handle gene expression data stored in parquet files. https://tomsing1.github.io/blog/posts/parquetArray/ This way, I can leverage familiar R tools and take
advantage of the language-agnostic parquet file format, querying very large gene expression datasets. Do you have experience with parquet files for biological data - please share the lessons you have learned! #til #parquet #rstats #duckdb #bioconductor
#til #parquet #RStats #duckdb #Bioconductor

Steve Purcell · @sanityinc
693 followers · 1059 posts · Server hachyderm.ioI figured out how to abuse #DuckDB to convert gzipped web server log files into compressed Parquet columnar storage files that can be queried efficiently later: https://gist.github.com/purcell/6e72406f77340e6d9bc451c72a316b8f
Steve Purcell · @sanityinc
693 followers · 1059 posts · Server hachyderm.io@xenodium Yeah, you can also use duckdb to directly query sqlite DBs, compressed (or plain) CSV files, JSON, and more, even over http. It's a pretty great set of powertools, and their extensions to regular SQL are very interesting. There are even spatial extensions for it now. Worth checking out the #duckdb hashtag.
Steve Purcell · @sanityinc
693 followers · 1059 posts · Server hachyderm.io
@xenodium And just in case you're curious how these get counted, I wrote up something after recently blowing some time tinkering with the machinery as an excuse to test-drive #duckdb. 😁 https://github.com/melpa/melpa/tree/master/docker/logprocessor
Thomas Sandmann · @thomas_sandmann
366 followers · 1147 posts · Server genomic.socialToday I learned how to store gene expression data in (multiple) parquet files, and query them as a single dataset from R with the {arrow}, {duckdb} or {sparklyr} packages. I am amazed by {duckdb}'s speed 🚀 - even on my laptop! Here's a blog post with what I learned: https://tomsing1.github.io/blog/posts/parquet/ #TIL #RStats #duckdb #parquet #spark #compbio #rnaseq
#til #RStats #duckdb #parquet #spark #compBio #rnaseq
Steve Purcell · @sanityinc
668 followers · 989 posts · Server hachyderm.io
I have that "using delightful free software" feeling again today -- #DuckDB is hilariously good. The stats on MELPA.org (#Emacs packages) are based on processed web logs, which we've kept forever. We used to whittle the relevant data into a normalised sqlite DB file, which has passed 7GB (330M downloads). I'm switching this over to DuckDB and it's super fast and space-efficient for this use case, while being a simple code change. I'll share numbers soon. https://duckdb.org/

maurizio napolitano · @napo
144 followers · 77 posts · Server mastodon.unodisponibile su GitHub la documentazione con cui ho generato i file #geopackage per ogni regione d'Italia per edifici e luoghi distribuiti da Overture Maps Foundations arricchiti dai codici ISTAT per l'estrazione per comune o provincia.
Link dpwnload aggiornati e codice SQL usato qui
https://github.com/napo/overturemaps_italy/
#duckdb #opendata #osm
#geopackage #duckdb #opendata #osm

Fábio Costa :Ryyca:🐇🕐🎩☕🇧🇷 · @fabiocosta0305
160 followers · 3472 posts · Server ursal.zoneOK... Two days after loading my data on a #DuckDB file (144m+ CSV lines), I started to operate on it. Jesus Christ on a bike! It's super performatic!!!
I'll work more on DuckDB in the future. Woot!

Taras Novak 🇺🇦 · @dataSamurai
178 followers · 320 posts · Server vis.socialWe can attest that #Quarto #VisualEditor is much more aesthetically pleasing to view and edit markdown docs interleaved with code blocks, and provides a unique document view experience.
Brief demo of our #DuckDB #ObservableJS 📓 converted to .qmd doc using it. ⬇
Quarto Visual Editing docs:
📰 https://quarto.org/docs/visual-editor/vscode/
Our Observable #DataTools 🛠️ and #JSNotebooks 📚 repository:
📥 https://github.com/RandomFractals/observable-data-tools
DuckDB #DataTables Quarto doc:
#QuartoPub #DuckDBTools 🧙♂️ ...
#QuartoPub #duckdbtools #datatables #JSNotebooks #datatools #ObservableJS #duckdb #visualeditor #quarto
Andrea Borruso · @aborruso
227 followers · 203 posts · Server mastodon.uno
Taras Novak 🇺🇦 · @dataSamurai
175 followers · 317 posts · Server vis.socialProbably the most complete #DuckDB #SQLTools extension created for devs & data scientists using #VSCode that includes all the DuckDB tree view objects, including main DB instance, system and temp database views with the corresponding main, information schema & pg_catalog schemas display, settings, extensions, data types, functions, and keywords display you will not find in #DBeaver or @motherduck or any other related DuckDB Tool/driver out there. 🤗
📰 https://github.com/RandomFractals/pro-data-tools/blob/main/duckdb-tools.md#duckdb-objects-tree-view
#ProDataTools 🧙♂️ ...
#prodatatools #dbeaver #vscode #sqltools #duckdb
Taras Novak 🇺🇦 · @dataSamurai
175 followers · 316 posts · Server vis.socialOne of the main reasons to try our #DuckDBPro 🛠️ in @code IDE are the 30+ custom #DuckDB view & metadata shortcut commands you can invoke from the standard VS Code Commands Palette while exploring those embedded DB files in your apps for your next EDA #dataProject ...
📰 https://github.com/RandomFractals/pro-data-tools/blob/main/duckdb-tools.md#duckdb-view-commands
#ProDataTools 🧙♂️ ...
#prodatatools #dataproject #duckdb #duckdbpro
Fábio Costa :Ryyca:🐇🕐🎩☕🇧🇷 · @fabiocosta0305
158 followers · 3387 posts · Server ursal.zoneSolving my own #duckdb doubt...
As it doesn't have an `affected_rows()` method, you can use `len()` either on a common array via `resultset.fetch_all()` or on a Pandas dataframe via `resultset.df()`
Fábio Costa :Ryyca:🐇🕐🎩☕🇧🇷 · @fabiocosta0305
158 followers · 3385 posts · Server ursal.zone
Ploomber · @ploomber
32 followers · 37 posts · Server fosstodon.org🔧 🚀 Performance Boost: Users converting DuckDB results to pandas DataFrames can now enjoy an optimized experience with our feature roll out fix.
JupySQL is now using native methods to convert to data frames from DuckDB when using native connections and SQLAlchemy to maximize performance
Your data manipulation tasks just got a whole lot faster!
Check it out now:
https://jupysql.ploomber.io/en/latest/integrations/duckdb.html
Fábio Costa :Ryyca:🐇🕐🎩☕🇧🇷 · @fabiocosta0305
155 followers · 3327 posts · Server ursal.zoneEnquanto isso...
38 milhões de linhas de dados de 133 milhões em CSV carregando no #duckdb. A única forma que encontrei de fazer isso sem travar a máquina foi criar um Python para dar uma restringida e ir carregando ela mais lentamente, sem tentar socar goela abaixo.
Taras Novak 🇺🇦 · @dataSamurai
176 followers · 309 posts · Server vis.social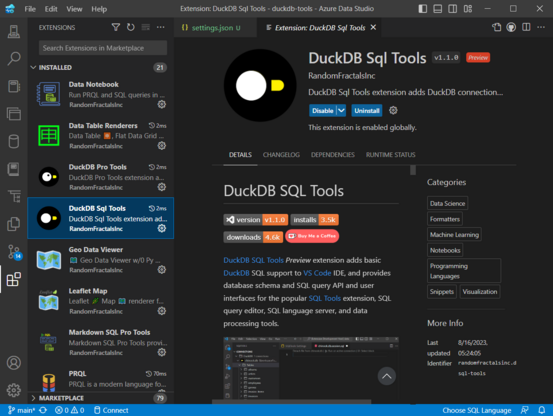
{kind=link}
{kind=link}
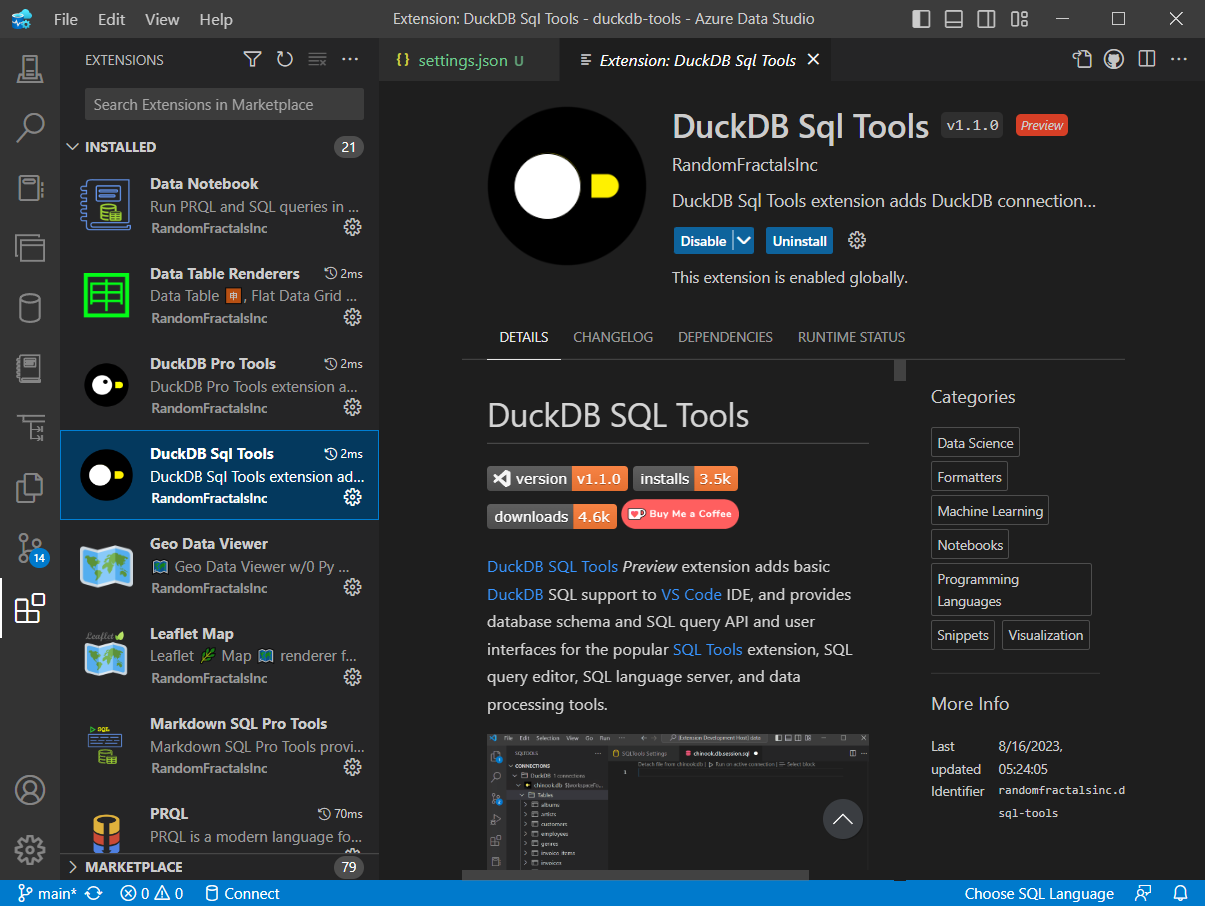{kind=link}
We took the latest #AzureDataStudio for a spin today and can confirm that all of our old custom #VSCode #dataViz extensions work in that IDE, including new #DuckDB #SQLTools, #PRQLCodeLens, new #MarkdownSQLTools, and soon to be released #DataNotebookProTools.
We'll post some walkthroughs on how to install and use some of our new #ProDataTools in Azure Data Studio IDE soon.
Let us know if any of these #DataTools would be of interest to your #DataTeams and your users.
#datateams #datatools #prodatatools #datanotebookprotools #markdownsqltools #prqlcodelens #sqltools #duckdb #dataviz #vscode #azuredatastudio