
Leshem Choshen · @LChoshen
1059 followers · 326 posts · Server sigmoid.social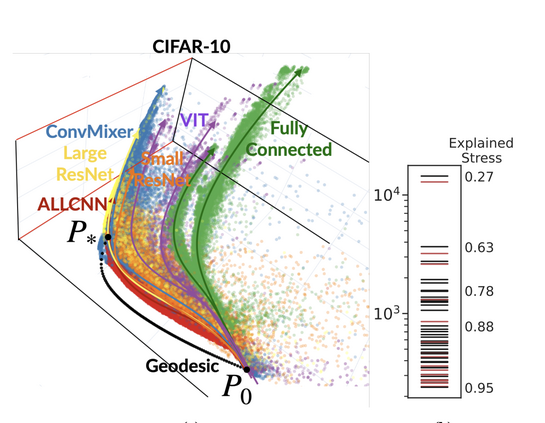
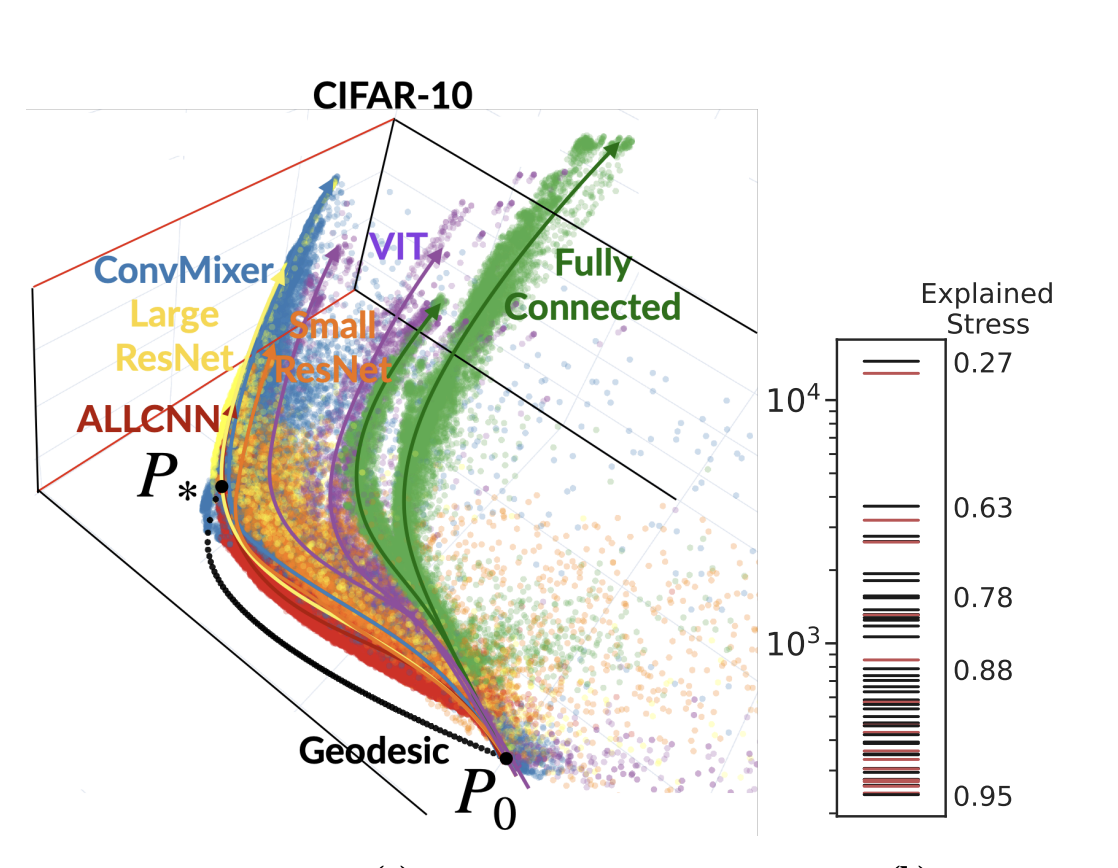
Predictions throughout training, hyperparams and architectures are yet again shown to be on
a small manifold
which means models learn their classifications outputs similarly
https://arxiv.org/abs/2305.01604
Mao ... @pratikac
#MachineLearning #enough2skim
Leshem Choshen · @LChoshen
965 followers · 224 posts · Server sigmoid.social
{kind=link}
{kind=link}
Few-shot learning almost reaches traditional machine translation
https://arxiv.org/abs/2302.01398
#enough2skim #NLProc #neuralEmpty
#enough2skim #nlproc #neuralempty
Leshem Choshen · @LChoshen
949 followers · 193 posts · Server sigmoid.social20 questions can now be played by computers
you probably all know @akinator_team@twitter.com that can guess what you thought about
https://arxiv.org/pdf/2301.08718.pdf
propose the other role
They pick a character and will answer yes or no
(basically, QA over wiki+ tweaks)