
Nayla Salibi · @Salibi
202 followers · 587 posts · Server social.tchncs.deتمنع مواقع #ويب وصول #GPTBot، الذي طورته، #OpenAi لجمع البيانات، بحجة تحسين "دقة نماذج #الذكاء_الاصطناعي" التي تطورها. لماذا قلق هذه المواقع من حصد بياناتها؟ وكيف يمكن حظر #الروبوت من حصد بيانات مواقع الويب؟مع تحيات #نايلةالصليبي
#AI
#web_crawler
#ويب #gptbot #openai #الذكاء_الاصطناعي #الروبوت #نايلةالصليبي #ai #web_crawler

Redhotcyber · @redhotcyber
588 followers · 1789 posts · Server mastodon.bida.imOpenAI rilascia il web crowler GPTBot. Migliorerà la capacità del modello e non violerà il diritto d’autore
#OpenAI ha lanciato il #webcrawler #GPTBot per migliorare i suoi modelli di #intelligenza #artificiale (#AI).
#redhotcyber #online #it #web #ai #hacking #privacy #cybersecurity #cybercrime #intelligence #intelligenzaartificiale #informationsecurity #ethicalhacking #dataprotection #cybersecurityawareness #cybersecuritytraining #cybersecuritynews #infosecurity
#openai #webcrawler #gptbot #intelligenza #artificiale #ai #redhotcyber #online #it #web #hacking #privacy #cybersecurity #cybercrime #intelligence #intelligenzaartificiale #informationsecurity #ethicalhacking #dataprotection #CyberSecurityAwareness #cybersecuritytraining #CyberSecurityNews #infosecurity

Ian Brown :fedi: · @1br0wn
2175 followers · 2094 posts · Server eupolicy.socialNew York Times, CNN and Australia’s ABC block #OpenAI’s #GPTBot web crawler from accessing content https://www.theguardian.com/technology/2023/aug/25/new-york-times-cnn-and-abc-block-openais-gptbot-web-crawler-from-scraping-content?CMP=Share_iOSApp_Other

beSpacific · @bespacific
1106 followers · 2068 posts · Server newsie.social
The #NewYorkTimes has blocked #OpenAI’s #webcrawler, meaning that OpenAI can’t use content from the publication to train its AI models. If you check the NYT’s robots.txt page, you can see that the NYT disallows #GPTBot, the crawler that OpenAI introduced earlier this month. Based on the #InternetArchive’s #WaybackMachine, it appears NYT blocked the crawler as early as August 17th. https://www.theverge.com/2023/8/21/23840705/new-york-times-openai-web-crawler-ai-gpt #copyright #legalresearch
#newyorktimes #openai #WebCrawler #gptbot #internetarchive #waybackmachine #copyright #legalresearch

· @shaun
223 followers · 1189 posts · Server mastodon.xyz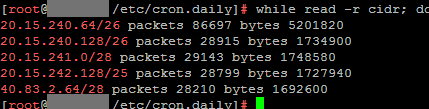

PrivacyDigest · @PrivacyDigest
541 followers · 2002 posts · Server mas.to
Paul Chambers · @paul
1828 followers · 9169 posts · Server oldfriends.live#OpenAI IP block ranges if you want to block them from your instance and scraping your content. I saw Mastodon devs added something to block #GPTBot via robots.txt a few days ago. Here are the IP ranges:
20.15.240.64/28
20.15.240.80/28
20.15.240.96/28
20.15.240.176/28
20.15.241.0/28
20.15.242.128/28
20.15.242.144/28
20.15.242.192/28
40.83.2.64/28
https://openai.com/gptbot-ranges.txt
https://www.theverge.com/2023/8/7/23823046/openai-data-scrape-block-ai
#openai #gptbot #mastoadmin #fediblock

bananabob · @bananabob
75 followers · 1781 posts · Server mastodon.nz
Sites scramble to block ChatGPT web crawler after instructions emerge
#arstechnica #chatgpt #gptbot #robotstxt

IT News · @itnewsbot
3605 followers · 270022 posts · Server schleuss.onlineSites scramble to block ChatGPT web crawler after instructions emerge - Enlarge (credit: Getty Images)
Without announcement, OpenAI re... - https://arstechnica.com/?p=1960108 #machinelearning #webscraming #webcrawling #aiethics #chatgpt #chatgtp #biz #gptbot #openai #tech #ai
#ai #tech #openai #gptbot #biz #chatgtp #chatgpt #aiethics #webcrawling #webscraming #machinelearning

Tech news from Canada · @TechNews
929 followers · 24992 posts · Server mastodon.roitsystems.ca
Ars Technica: Sites scramble to block ChatGPT web crawler after instructions emerge https://arstechnica.com/?p=1960108 #Tech #arstechnica #IT #Technology #machinelearning #webscraming #webcrawling #AIethics #ChatGPT #chatgtp #Biz&IT #GPTBot #openai #Tech #AI
#Tech #arstechnica #it #technology #machinelearning #webscraming #webcrawling #aiethics #chatgpt #chatgtp #biz #gptbot #openai #ai

@gmgall NFLizado das ideias 🏈 · @gmgall
233 followers · 2453 posts · Server ursal.zoneAdministradores de sistemas e redes da minha timeline, as faixas de IP do #GPTBot são as seguintes.
20.15.240.64/28
20.15.240.80/28
20.15.240.96/28
20.15.240.176/28
20.15.241.0/28
20.15.242.128/28
20.15.242.144/28
20.15.242.192/28
40.83.2.64/28
Happy Blocking!
É citado na última frase daqui https://platform.openai.com/docs/gptbot, pode passar despercebido.
#gptbot #openai #chatgpt #ia #ai

Nathaniel Daught · @nfd
184 followers · 1203 posts · Server masto.aiCan I even customize my robots.txt on Squarespace to stop GPTBot from crawling my site? (Probably not) It's an easy and convenient hosting/builder solution until it's not…

Stu · @tehstu
224 followers · 1637 posts · Server hachyderm.io
Simon D. ⏚ · @Siltaer
1086 followers · 11270 posts · Server mamot.frOpenAI lance son web crawler, #RSF appelle les médias à le bloquer
https://www.nextinpact.com/article/72216/openai-lance-son-web-crawler-rsf-appelle-medias-a-bloquer
Avec #GPTBot, #OpenAI lance un web crawler dédié à récupérer des données « depuis tout Internet », quand bien même les plaintes pour infraction à la vie privée et au droit d'auteur se multiplient contre les différents #LLM déployés sur le marché. #chatgpt
#rsf #gptbot #openai #llm #chatgpt

LWFlouisa · @lwflouisa
5 followers · 266 posts · Server comics.town
Chez Juju (secours) · @Juste_Juju
1 followers · 11 posts · Server ludosphere.frDans un communiqué, #RSF invite les médias à configurer leurs sites d'information pour empêcher #OpenAI / #ChatGPT de récolter leurs contenus.
« Les #médias doivent être rétribués pour leur travail d'intérêt général dont les mastodontes de la #tech voudraient tirer profits à bons comptes. »
Espérons que cela sera suivi !
https://nitter.lacontrevoie.fr/RSF_Tech/status/1688937301592682496
#rsf #openai #chatgpt #medias #tech #gptbot

Gianmarco :archlinux: :kde: · @gianmarcogg03
295 followers · 3072 posts · Server mastodon.unoIt may be a good idea to block the #GPTBot crawler from your websites with something like this (if you use #Nginx):
if ($http_user_agent ~ (GPTBot) ) {
return 403;
}
rather than using the robots.txt file since who knows if they really respect it.
#AI #OpenAI #ChatGPT #GPT4 #GPT5 #Copyright #CreativeCommons
#gptbot #nginx #ai #openai #chatgpt #GPT4 #gpt5 #copyright #creativecommons

ChatGPTroll 🥔 · @Troll
3454 followers · 69425 posts · Server maly.io
Si vous voulez empêcher le robot d'indexation d'OpenAI de scanner votre site web et d'entraîner leur modèle avec votre contenu:

Benjamin Carr, Ph.D. 👨🏻💻🧬 · @BenjaminHCCarr
977 followers · 2499 posts · Server hachyderm.io
{kind=link}
{kind=link}
{kind=link}
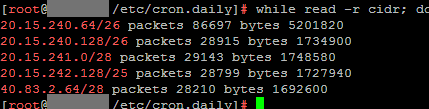
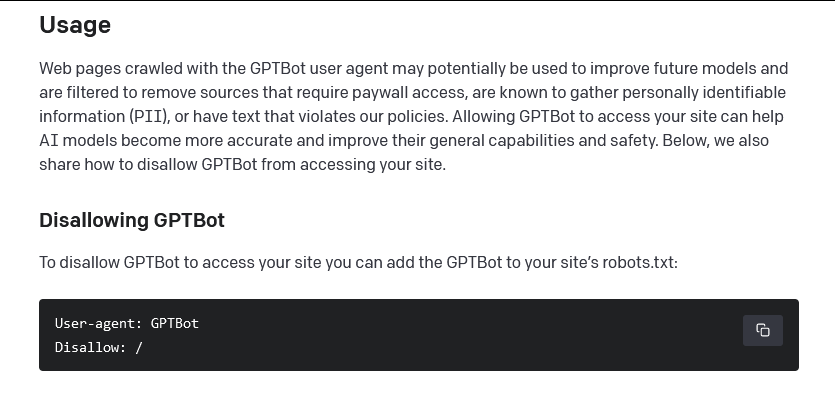
Now you can block #OpenAI’s #webcrawler
OpenAI now lets you block its web crawler from scraping your site to help train #GPT models. OpenAI said website operators can specifically disallow its #GPTBot crawler on their site's #Robots.txt file or block its IP address.
https://www.theverge.com/2023/8/7/23823046/openai-data-scrape-block-ai #privacy #security #RobotsTxT
#openai #webcrawler #gpt #gptbot #robots #privacy #security #robotstxt

· @mistersixt
67 followers · 1337 posts · Server kanoa.de