
𝗠𝗔𝘀𝘁𝗼𝗠𝗘𝗺𝗲𝗠𝗔𝗸𝗲𝗿𝘀 · @mastomememakers
1325 followers · 1724 posts · Server det.social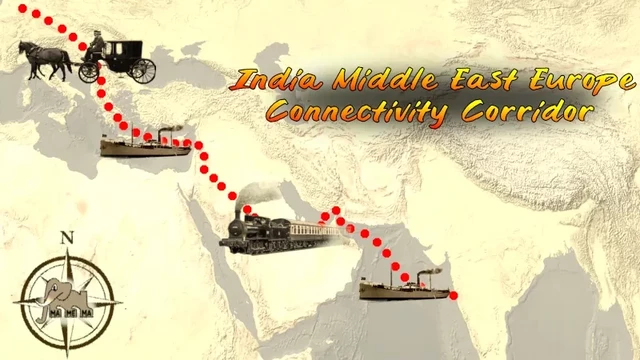
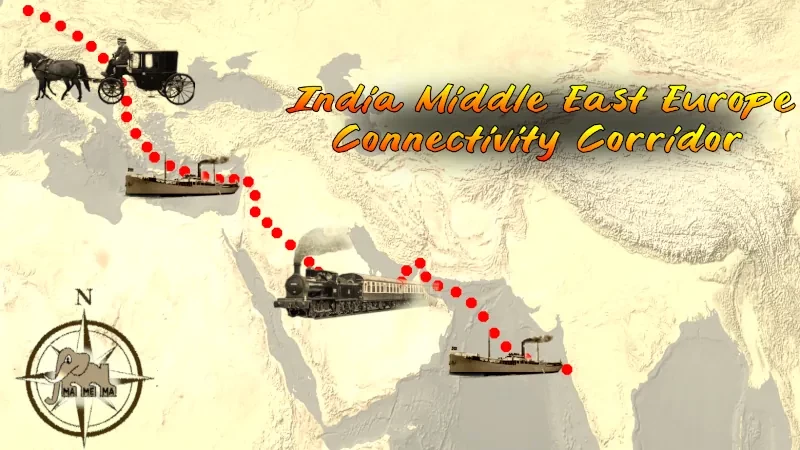
so they plan a trading route that, checks his notes, includes ...#trucks
#imec #g20 #newdelhi #india #bharat #uae #ksa #jordania #israel #greece #balkan (no route details, i d guess changes to port of venice, but if realllly #truck #gr #mk #rs #hu) #meme #mamema #memes #geopolitics
leads to wikipedia: https://rb.gy/rkwad
for further arduous elaborations, see comment
#Trucks #IMEC #g20 #newdelhi #india #Bharat #UAE #ksa #jordania #israel #greece #Balkan #truck #gr #mk #rs #Hu #meme #mamema #memes #geopolitics

arXiv Graphics🖼️ · @arxiv_gr
65 followers · 1392 posts · Server creative.ai
📝 SimpleNeRF: Regularizing Sparse Input Neural Radiance Fields with Simpler Solutions 🔭🖼️
"Designs augmented models that encourage simpler solutions by exploring the role of positional encoding and view-dependent radiance in training the NeRF with only few images, and estimate the depth from them." [gal30b+] 🤖 #CV #GR
arXiv Graphics🖼️ · @arxiv_gr
65 followers · 1390 posts · Server creative.ai
📝 Residency Octree: A Hybrid Approach for Scalable Web-Based Multi-Volume Rendering 🖼️
"Presents a hybrid multi-volume rendering approach based on a novel Residency Octree that combines the advantages of out-of-core volume rendering using page tables with those of standard octrees." [gal30b+] 🤖 #GR
arXiv Graphics🖼️ · @arxiv_gr
65 followers · 1390 posts · Server creative.ai
📝 ArtHDR-Net: Perceptually Realistic and Accurate HDR Content Creation 🔭🖼️🧠
"Based on a Convolutional Neural Network that uses multi-exposed LDR features as input for the reconstruction of HDR images with a high aesthetic quality score in terms of human visual perception." [gal30b+] 🤖 #CV #GR #LG #MM
arXiv Graphics🖼️ · @arxiv_gr
64 followers · 1384 posts · Server creative.ai
📝 SyncDreamer: Generating Multiview-Consistent Images From a Single-View Image 🔭👾🖼️
"SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views." [gal30b+] 🤖 #CV #AI #GR
⚙️ https://github.com/OPHoperHPO/image-background-remove-tool
🔗 https://arxiv.org/abs/2309.03453v1 #arxiv
arXiv Graphics🖼️ · @arxiv_gr
64 followers · 1381 posts · Server creative.ai
📝 Adaptive Sampling of 3D Spatial Correlations for Focus+Context Visualization 🖼️
"The embedding into a chord diagram enables the display of correlations between multiple spatial regions in one static view by arranging them along the circular layout via a space-filling curve." [gal30b+] 🤖 #GR
⚙️ https://github.com/chrismile/
🔗 https://arxiv.org/abs/2309.03308v1 #arxiv
arXiv Graphics🖼️ · @arxiv_gr
64 followers · 1374 posts · Server creative.ai
📝 Meshing Deforming Spacetime for Visualization and Analysis 🖼️
"Builds a 3D simplicial complex -- a tetrahedral mesh -- from 2D triangular meshes that are consecutive timesteps, while satisfying given constraints on how nodes connect between the two timesteps (such as a given magnetic field line)." [gal30b+] 🤖 #GR

lbr59🇨🇵 · @lbr59
30 followers · 437 posts · Server mastodon.roflcopter.fr

Gopi Adusumilli :verified: · @gopi
1810 followers · 1177 posts · Server truthsocial.co.inBreather for Maha govt as Maratha leader extends GR ultimatum by 4 days #Breather #Maha #Maratha #GR #socialnewsxyz
#socialnewsxyz #gr #Maratha #Maha #breather
Gopi Adusumilli :verified: · @gopi
1810 followers · 1178 posts · Server truthsocial.co.inPro-quotas stir: Maratha protesters don’t budge, insist on GR #Pro #Maratha #GR #socialnewsxyz
https://www.socialnews.xyz/2023/09/05/pro-quotas-stir-maratha-protesters-dont-budge-insist-on-gr/
#socialnewsxyz #gr #Maratha #pro
arXiv Graphics🖼️ · @arxiv_gr
64 followers · 1371 posts · Server creative.ai
📝 Improving NeRF Quality by Progressive Camera Placement for Unrestricted Navigation in Complex Environments 🔭🖼️
"Proposes an algorithm that, given a set of camera placements, proposes new cameras to sample in regions of the 3D space where quality is low (e." [gal30b+] 🤖 #CV #GR
⚙️ https://github.com/anonymized
🔗 https://arxiv.org/abs/2309.00014v1 #arxiv
arXiv Graphics🖼️ · @arxiv_gr
64 followers · 1371 posts · Server creative.ai
📝 Technical Companion to Example-Based Procedural Modeling Using Graph Grammars 🖼️
"Works by using a graph grammar to generate a large space of possible models; then a genetic algorithm evolves a population of these models to match a set of examples." [gal30b+] 🤖 #GR
arXiv Graphics🖼️ · @arxiv_gr
64 followers · 1365 posts · Server creative.ai
📝 Visual-Guided Mesh Repair 🖼️
"Introduces three visual measures for visibility, orientation, and openness, based on raytracing to evaluate the visual quality of a repaired mesh, and then present a novel mesh repair framework that incorporates visual measures with several critical steps, i." [gal30b+] 🤖 #GR
⚙️ https://github.com/VisualGuidedMeshRepair/dataset
🔗 https://arxiv.org/abs/2309.00134v1 #arxiv
arXiv Graphics🖼️ · @arxiv_gr
63 followers · 1364 posts · Server creative.ai
📝 InterDiff: Generating 3D Human-Object Interactions with Physics-Informed Diffusion 🔭👾🖼️
"Proposes InterDiff, a framework comprising two key steps: Interaction Diffusion and Interaction Correction, to tackle the problem of future human-object interaction anticipation in 3D." [gal30b+] 🤖 #CV #AI #GR
arXiv Graphics🖼️ · @arxiv_gr
63 followers · 1346 posts · Server creative.ai

arXiv Human-CPU Interaction👋 · @arxiv_hc
61 followers · 809 posts · Server creative.ai
📝 Dance with You: The Diversity Controllable Dancer Generation via Diffusion Models 👋👾🖼️
"Proposes a three-stage framework called Dance-with-You (DanY), in which a wide range of basic dance pose sequences are collected and pre-generated." [gal30b+] 🤖 #HC #AI #GR
⚙️ https://github.com/JJessicaYao/AIST-M-Dataset
🔗 https://arxiv.org/abs/2308.13551v1 #arxiv
arXiv Human-CPU Interaction👋 · @arxiv_hc
61 followers · 807 posts · Server creative.ai
📝 RL-LABEL: A Deep Reinforcement Learning Approach Intended for AR Label Placement in Dynamic Scenarios 👋🖼️
"RL-LABEL uses deep reinforcement learning (DRL) to predict future states of objects and labels in order to generate label placements that minimize occlusions, line intersections, and label movements over long time periods." [gal30b+] 🤖 #HC #GR

Jim Donegan ✅ · @jimdonegan
1563 followers · 4708 posts · Server mastodon.scot
#JuanMaldacena - Does #Information Create the #Cosmos?
https://www.youtube.com/watch?v=dprKOGA57_I&ab_channel=CloserToTruth
#Philosophy #PhilosophyOfScience #Science #PhilosophyOfCosmology #Cosmology #QM #QuantumMechanics #Physics #QuantumPhysics #Superposition #WaveFunction #Entanglement #Universe #Gravity #QuantumGravity #Relativity #GR #GeneralRelativity #Holography #HolographicPrinciple #CloserToTruth #RobertKuhn
#RobertKuhn #CloserToTruth #HolographicPrinciple #holography #generalrelativity #gr #relativity #quantumgravity #gravity #universe #entanglement #wavefunction #superposition #quantumphysics #physics #quantummechanics #qm #cosmology #PhilosophyOfCosmology #science #philosophyofscience #philosophy #cosmos #information #juanmaldacena
arXiv Graphics🖼️ · @arxiv_gr
62 followers · 1323 posts · Server creative.ai
📝 Dense Text-to-Image Generation with Attention Modulation 🔭🖼️🧠
"Proposes a training-free approach that adapts a pre-trained text-to-image model to handle images with dense captions while providing control over scene layout without fine-tuning or extra data." [gal30b+] 🤖 #CV #GR #LG


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}