
Martin Prell · @mprell
173 followers · 77 posts · Server fedihum.orgWow, with the Super Model "Titan I", #Transkribus seems to have taken a next very impressive step. In particular, our corpora with very heterogeneous hands are recognised significantly better in our tests so far than models trained specifically on the hands. If this is confirmed, even the time-consuming creation of training data and the model training could become obsolete 🤯
#HTR #ATR #PROPYLÄEN
https://readcoop.eu/introducing-transkribus-super-models-get-access-to-the-text-titan-i/
#Transkribus #htr #atr #propylaen

Annika Rockenberger (she/they) · @arockenberger
274 followers · 350 posts · Server fedihum.orgAfter successfully training and improving my #Transkribus #HTR model for the #EthicaComplementoria prints, I used it on the youngest Ethica from 1728. Typographically, it is still very similar to the editions from the 17th century, so that should not be a big problem. I'll quality-check the first eight pages today and see, whether it is worthwhile improving the model for this particular print.
#Transkribus #htr #ethicacomplementoria

· @dehypotheses
1355 followers · 437 posts · Server fedihum.org
À ne pas rater, la keynote de notre atelier ATR par Dominique Stutzmann (IRHT/Humboldt-univ.):
"La reconnaissance automatique des textes (ATR). Nouveaux horizons pour les historiennes et les historiens"
07/09/2023
18h00
Sur place & en ligne
Infos 👉https://ow.ly/1QVC50PHl7t
#ATR #OCR #HTR #HumanitésNumériques #HistoireNumérique #DigitalHumanities
#atr #ocr #htr #humanitesnumeriques #histoirenumerique #DigitalHumanities

DHI Paris · @dhiparis
429 followers · 41 posts · Server wisskomm.social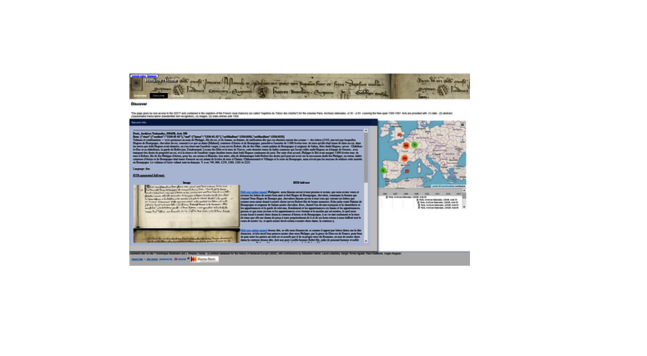
Nicht verpassen, die Keynote zu unserem ATR-Workshop von Dominique Stutzmann (IRHT/Humboldt-Univ.):
"Automatische Texterkennung (ATR). Neue Möglichkeiten für Historikerinnen und Historiker"
07.09.2023
18 Uhr
Online & vor Ort
Infos 👉 https://ow.ly/9eAt50PHkY3
#atr #ocr #htr #digitalhumanities #dh #digitalhistory
Annika Rockenberger (she/they) · @arockenberger
272 followers · 341 posts · Server fedihum.orgAnd that's it! Sent off the new training set and hopefully improve the issues I have encountered!
I will also use this model for the 1728 print. It's a different printing press, but overall, the two prints are very much alike, and so is the #Fraktur type they use. #Transkribus #EthicaComplementoria #HTR #EarlyModern #PrintHistory
#fraktur #Transkribus #ethicacomplementoria #htr #earlymodern #printhistory
DHI Paris · @dhiparis
429 followers · 41 posts · Server wisskomm.social
Workshop: "Von der historischen Quelle zum Volltext. Anwendung automatisierter Schrifterkennung (ATR)"
Mehr Infos ➡️ https://ow.ly/WqzQ50PGM5H
Nächste Woche am DHIP!
07.09.2023–08.09.2023
#atr #ocr #htr #digitalhumanities #dh #digitalhistory
Annika Rockenberger (she/they) · @arockenberger
272 followers · 340 posts · Server fedihum.org
Moving back to the #HTR issues, we have phenomena like these (shown in the image): The layout detection model draws 'short' lines when the text is warped in the book fold. This leads to especially slim letters and punctuation not getting recognized. When I do the corrections, I will also extend the lines to include these characters. Hopefully, it will improve the recognition! #Transkribus #EthicaComplementoria
#htr #Transkribus #ethicacomplementoria
Annika Rockenberger (she/they) · @arockenberger
271 followers · 339 posts · Server fedihum.orgThis phenomenon is highlighted because the #HTR model I've been training to recognize the text had too few characters in cursive in the training set. So they get misread, and I have to correct them, thus becoming hyperaware of these differences in the typesetting.
When I'm done, I will reconstruct the sheets and printing order to look at the distribution of spelling and other errors and typographical conventions. Exciting! #BookHistory #PrintHistory #AnalyticBibliography
#htr #bookhistory #printhistory #analyticbibliography

Phillip Ströbel · @phillipstroebel
156 followers · 37 posts · Server techhub.socialFinally, our fine-tuned #TrOCR model for #16thcentury #correspondence data (i. e., the #Bullinger #letters) is on @huggingface: https://huggingface.co/pstroe/bullinger-general-model
Have fun!
For more information: https://doi.org/10.5167/uzh-234886 & bullinger-digital.ch
#HTR #OCR #digitalhumanities #digitalhistory
#trocr #16thcentury #correspondence #bullinger #letters #htr #ocr #digitalhumanities #digitalhistory
Phillip Ströbel · @phillipstroebel
141 followers · 36 posts · Server techhub.socialMy thesis has been published & is now available: https://doi.org/10.5167/uzh-234886
I recommend Chapter 4 if you are interested in #HTR & what #Transformers can do for #historical #documents. #digitalhumanities #OCR
Thanks again to my supervisors Martin Volk & @thist, & everyone at the Department of Computational Linguistics from the University of Zurich!
#htr #transformers #historical #documents #digitalhumanities #ocr
Annika Rockenberger (she/they) · @arockenberger
265 followers · 332 posts · Server fedihum.orgExciting! Overnight, the text recognition job was completed and now I get to see how good the transcription is! #EthicaComplementoria #Transkribus #HTR
#ethicacomplementoria #Transkribus #htr
Annika Rockenberger (she/they) · @arockenberger
263 followers · 329 posts · Server fedihum.orgA long time ago, I wanted to do a #PhD project on text reuse & text production strategies of #EarlyModern #Author #GeorgGreflinger. I estimated ca. 30,000 pages of printed text. It was 2009/10, and large-scale digitisation of older books had just started. #OCR was a mess, & #HTR hadn't been a thing yet. Eventually, I abandoned the project, since manually transcribing 30,000 pp. & then doing computational analysis for text similarity & re-use was unfeasible.
Imagine I wanted to do that now!
#phd #earlymodern #author #georggreflinger #ocr #htr

Adi Keinan-Schoonbaert · @adi
211 followers · 96 posts · Server glammr.us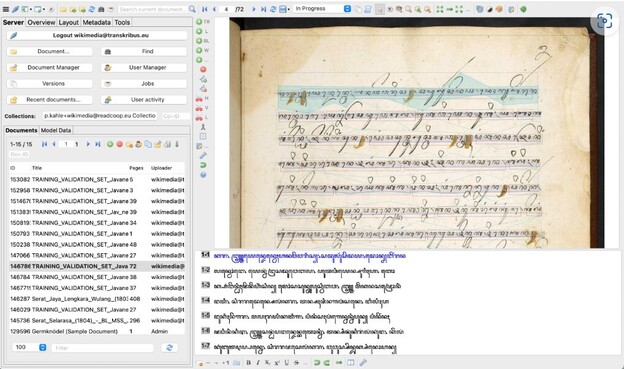
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
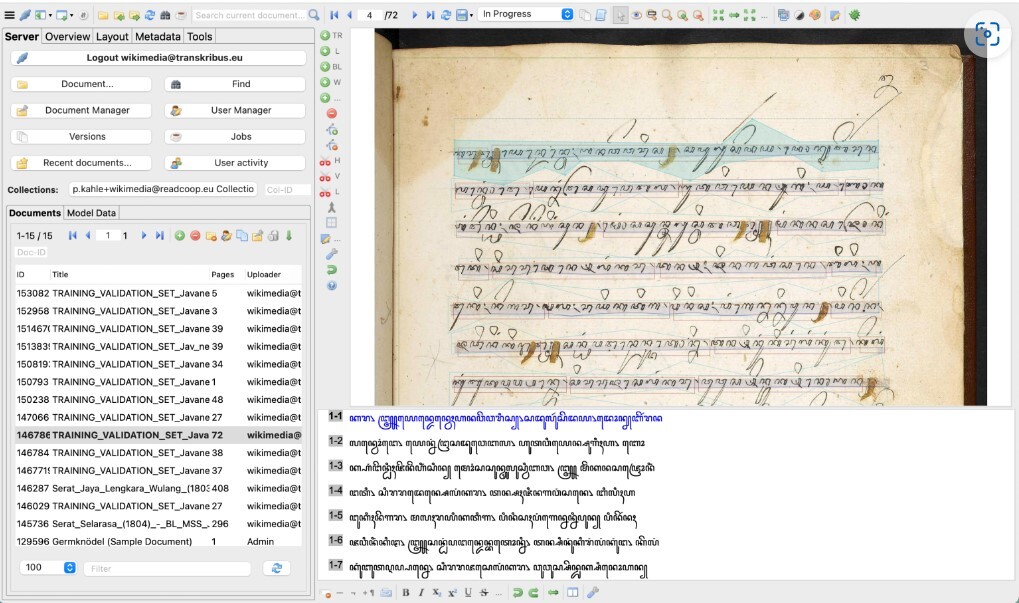
We are collaborating with #Wikimedia Foundation on the Wikisource Loves Manuscripts project, with a special twist! :apartyblobcat: The transcribed Indonesian manuscripts will be used to train a #Transkribus #HTR model! @BL_DigiSchol Read more here: https://blogs.bl.uk/digital-scholarship/2023/08/the-british-library-loves-manuscripts-on-wikisource.html

Jez 📚 · @petrichor
433 followers · 1275 posts · Server digipres.clubHere's a few more details about my progress training a handwriting model with #Transkribus
https://erambler.co.uk/blog/training-a-handwriting-model-update-1/
Annika Rockenberger (she/they) · @arockenberger
261 followers · 320 posts · Server fedihum.orgA blog post continuing my series of posts about the #EthicaComplementoria #DigitalScholarlyEdition project on the #GeorgGreflinger weblog: https://greflinger.hypotheses.org/716
Today about #HTR #Transkribus and re-using models.
#ethicacomplementoria #DigitalScholarlyEdition #georggreflinger #htr #Transkribus
Jez 📚 · @petrichor
427 followers · 1183 posts · Server digipres.clubSince #PyLaia is open source, it should be possible now to recreate this training on my own desktop with the same parameters, and apply the model to recognise new pages, and from there figure out a workflow to simplify getting handwritten notes into plain text for reference or publication.
Has done any of these stages? Any pointers?
Phillip Ströbel · @phillipstroebel
66 followers · 27 posts · Server techhub.socialAnna Scius-Bertrand is presenting the #Bullinger writer adaptation challenge @ ICDAR2023. The #dataset is available here: https://tc11.cvc.uab.es/datasets/BullingerDB_1
The paper here: https://link.springer.com/chapter/10.1007/978-3-031-41676-7_23
#HTR #OCR #digitalhumanities
#bullinger #dataset #htr #ocr #digitalhumanities
Phillip Ströbel · @phillipstroebel
63 followers · 25 posts · Server techhub.socialNext week, I will present our (authors being @thist, @boente Martin Volk & me) paper about the #adaptability of #Transformer-based OCR models for #historical documents at the ADAPDA workshop @icdar2023. Preprint available here: https://www.researchgate.net/publication/373124507_The_Adaptability_of_a_Transformer-Based_OCR_Model_for_Historical_Documents. Disclaimer: This preprint has not undergone any post-submission improvements or corrections. The Version of Record of this contribution is published in Document Analysis and Recognition – ICDAR 2023 Workshops, and is available online at https://doi.org/10.1007/978-3-031-41498-5_3. #digitalhumanites #OCR #HTR #letters
#adaptability #transformer #historical #digitalhumanites #ocr #htr #letters

Alix Chagué · @Alix_Tz
40 followers · 10 posts · Server hcommons.social
Alix Chagué · @Alix_Tz
21 followers · 6 posts · Server hcommons.social[📢 #phd] I had a little bit of fun this afternoon training #HTR models on the Lucien Peraire's archives. I even go to try out @wouter_haverals's CERberus to test my models' predictions. Inevitably, I wrote a new blog post about it!
Since Peraire's archives have two ensembles of very different documents in French (same handwriting but different writing tools), I tested how good a model can be when trained only on one of the ensembles and vice-versa. I got really excited by the results because one of my models just completely lost it on the unseen writing tool 😋