
Benjamin Han · @BenjaminHan
477 followers · 1327 posts · Server sigmoid.social4/
[3] Dhananjay Ashok and Zachary C. Lipton. 2023. PromptNER: Prompting For Named Entity Recognition. http://arxiv.org/abs/2305.15444
[4] https://paperswithcode.com/sota/named-entity-recognition-ner-on-conll-2003
[5] https://paperswithcode.com/sota/named-entity-recognition-on-genia
#nlp #nlproc #knowledgegraph #paper
Benjamin Han · @BenjaminHan
477 followers · 1326 posts · Server sigmoid.social3/
REFERENCES
[1] Previous posts on ICL and why it works: https://www.linkedin.com/posts/benjaminhan_llms-iclr2023-mastodon-activity-7093281970792632320-XE87, https://www.linkedin.com/posts/benjaminhan_generativeai-gpt4-llm-activity-7045542002947457024-bGPt/, https://www.linkedin.com/posts/benjaminhan_llms-gpt3-nlp-activity-7073726814170337280-EED5/
#nlp #nlproc #knowledgegraph #paper
Benjamin Han · @BenjaminHan
477 followers · 1326 posts · Server sigmoid.social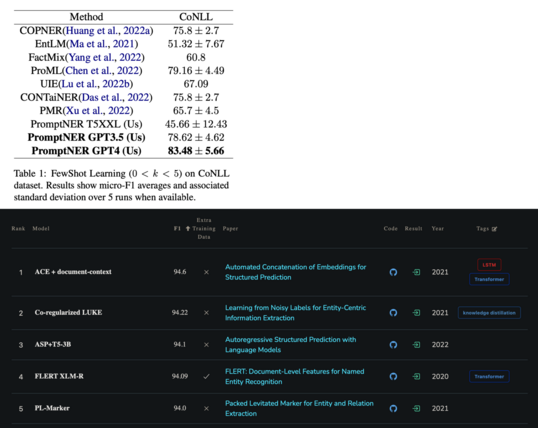
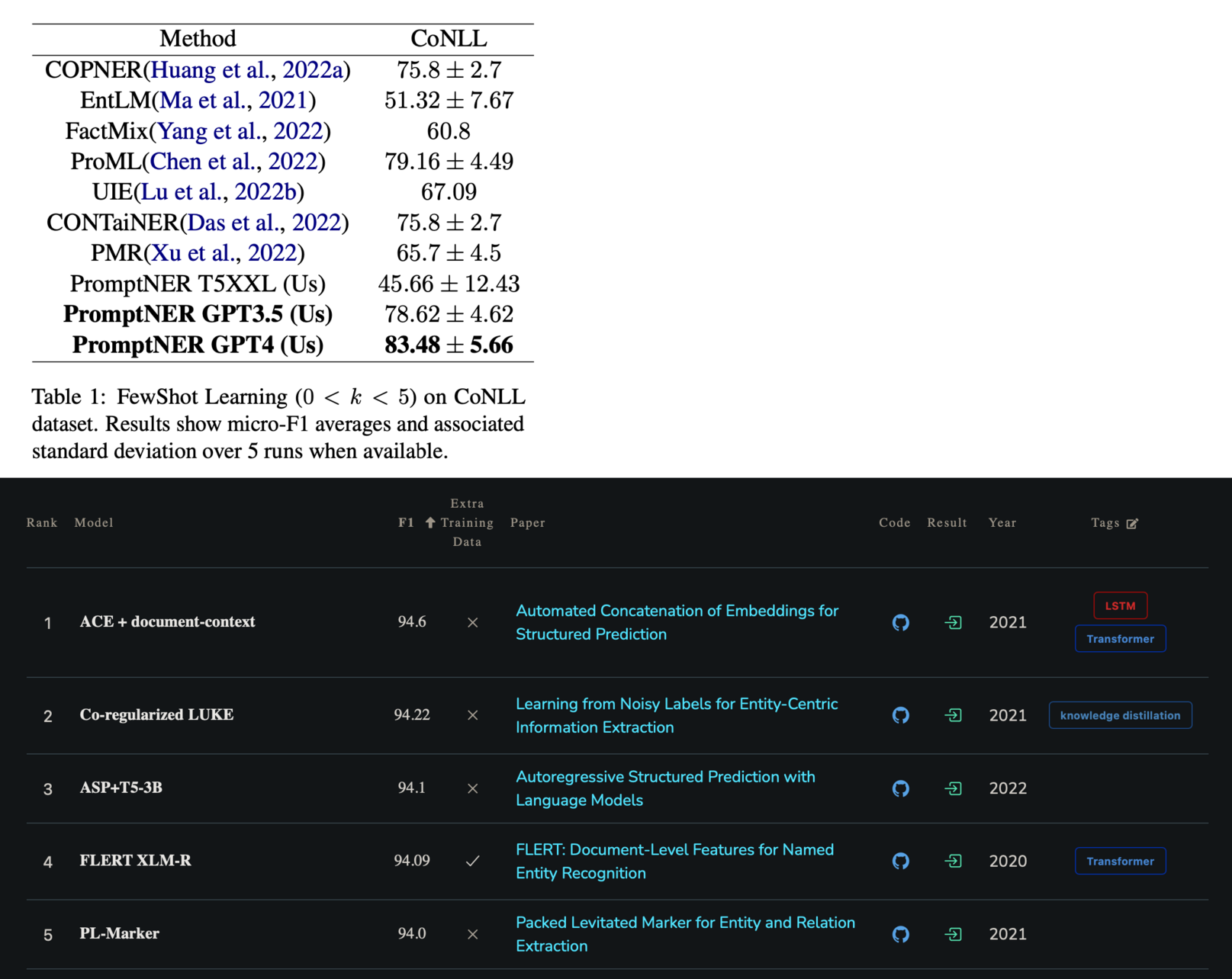
2/ One particular recent paper in the discussion proposed an ICL approach named PromptNER [3], and reported SOTA results among its ICL peers on well-known datasets such as CoNLL 2003 and GENIA. Compared its results with the SOTA *fine-tuning* (FT) solutions, FT outperforms on CoNLL by 10+ points (94.6 vs. 83.48; screenshot 1) [4], and outperforms on GENIA too by 20+ points (80.8 vs. 58.44; screenshot 2) [5].
#nlproc #knowledgegraph #paper

Harald Sack · @lysander07
748 followers · 461 posts · Server sigmoid.social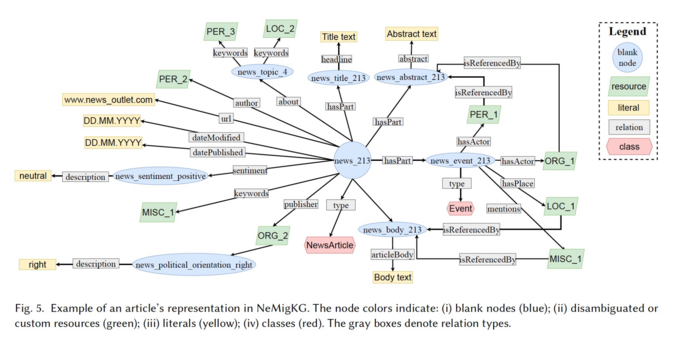
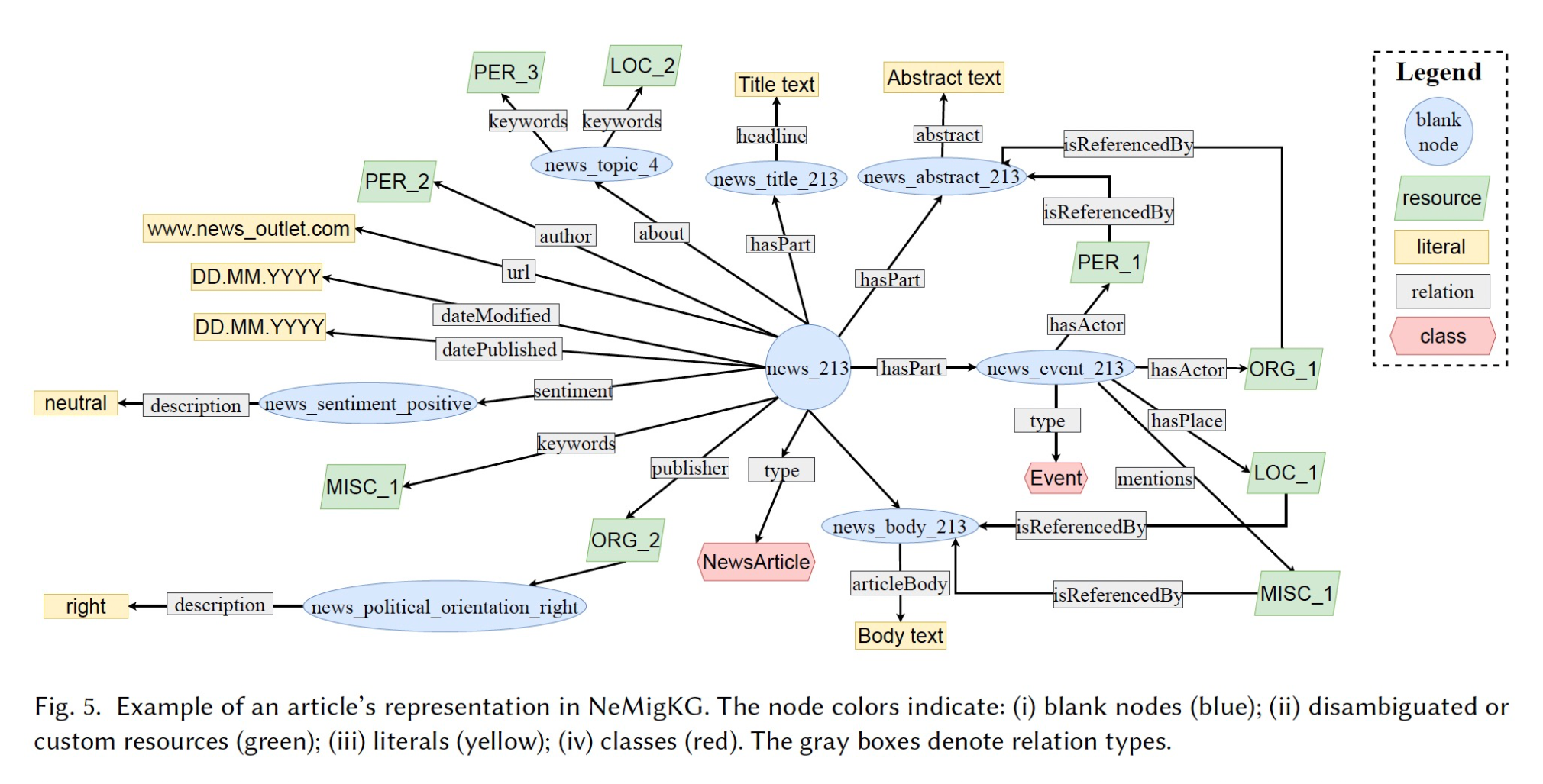
NeMiG is a bilingual (en/de) news #dataset on the topic of #migration, which can be used, among others, to conduct controlled experiments on #polarization by news #recommendersystems. https://arxiv.org/abs/2309.00550 Joint work in the #ReNewRS project w/
@dwsunima @fizise
@kitkarlsruhe
via HeikoPaulheim@twitter
#knowledgegraph #recsys
#dataset #migration #polarization #recommendersystems #renewrs #knowledgegraph #recsys
Harald Sack · @lysander07
748 followers · 461 posts · Server sigmoid.social
Of course I know RDF2vec ;-)
However, Heiko Paulheim's RDF2vec website has grown nicely and has become a rather valuable resource for this #knowledgegraph embedding method, including implementations, models and services, variations and extensions, as well as more than 150 references in scientific papers!
RDF2vec website: http://www.rdf2vec.org/
original paper: https://madoc.bib.uni-mannheim.de/41307/1/Ristoski_RDF2Vec.pdf
Petar Ristoski's PhD thesis (with RDF2vec): https://ub-madoc.bib.uni-mannheim.de/43730/1/Ristoski_PhDThesis_final.pdf
#kge #deeplearning #embeddings
#knowledgegraph #kge #deeplearning #embeddings
Harald Sack · @lysander07
741 followers · 454 posts · Server sigmoid.social
Nice visualizations in the SemOpenAlex Explorer enabling the exploration of 249M works, 135M authors, 109K institutions, and 65K topics from SemOpenAlex
Explorer website: https://semopenalex.org/
SemOpenAlex ontology: https://semopenalex.org/resource/?uri=https%3A%2F%2Fsemopenalex.org%2Fvocab%23
paper: https://arxiv.org/pdf/2308.03671.pdf
RDF dump of 26B triples: https://semopenalex.s3.amazonaws.com/browse.html
#knowledgegraph #semanticweb #exploratorysearch #semanticsearch #RDF
#knowledgegraph #semanticweb #exploratorysearch #SemanticSearch #rdf
Harald Sack · @lysander07
741 followers · 454 posts · Server sigmoid.social
Hang in there, my fellow #knowledgegraph researchers and practitioners, soon (in a few years) we will reach the "Slope of Enlightenment" ;-)
The new Gartner hype cycle for AI positions knowledge graphs right in the middle of the "Through of Disillusionment" ... while placing #GenerativeAI and #FoundationModels #LLMs at the peak of the hype
https://www.gartner.com/en/articles/what-s-new-in-artificial-intelligence-from-the-2023-gartner-hype-cycle#:~:text=The%202023%20Gartner%20Hype%20Cycle%E2%84%A2%20for%20Artificial%20Intelligence%20(AI,most%20credible%20cases%20for%20investment.
#semanticweb #ai #hypecycle #artificialintelligence
#knowledgegraph #generativeAI #foundationmodels #LLMs #semanticweb #ai #hypecycle #artificialintelligence
Benjamin Han · @BenjaminHan
460 followers · 1259 posts · Server sigmoid.social7/ REFERENCES
[1] Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. 2021. Fast Model Editing at Scale. http://arxiv.org/abs/2110.11309
[2] Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2021. Knowledge Neurons in Pretrained Transformers. http://arxiv.org/abs/2307.14988
#papers #nlp #nlproc #knowledge #knowledgegraph
Benjamin Han · @BenjaminHan
460 followers · 1259 posts · Server sigmoid.social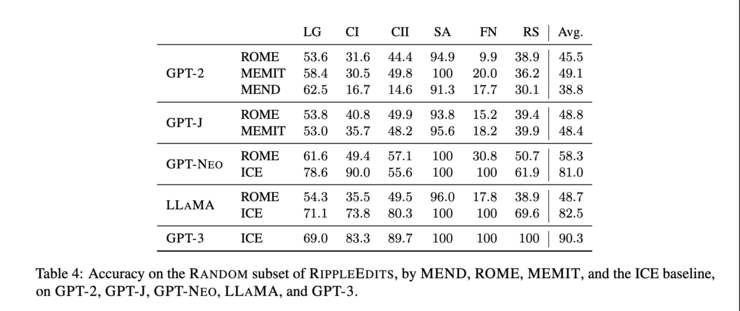
6/ It’d be interesting to see how “complete” various model editing methods can achieve (screenshot), and how to achieve a better tradeoff between completeness and efficiency.
#papers #nlp #nlproc #knowledge #knowledgegraph
Benjamin Han · @BenjaminHan
460 followers · 1259 posts · Server sigmoid.social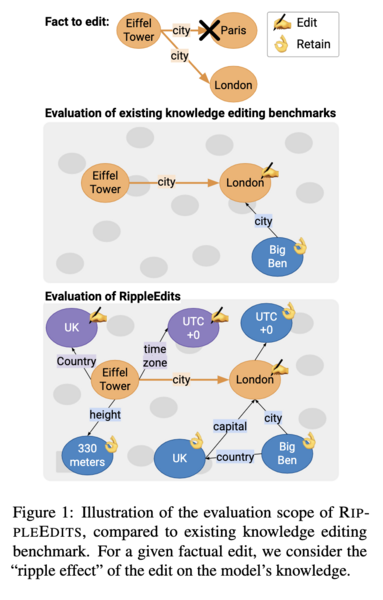
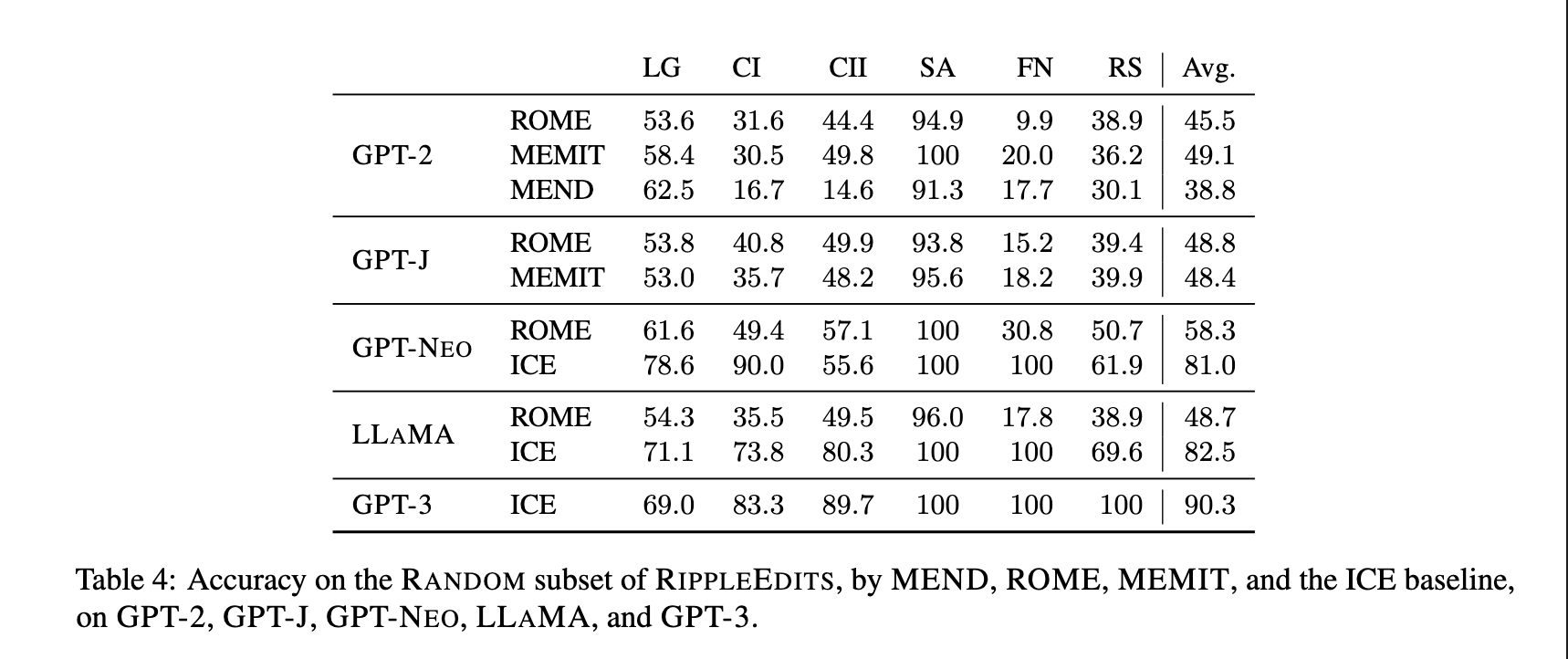
5/ Another related recent work is on how to properly evaluate model editing [5]. Instead of just assessing whether an individual fact has been successfully injected or if similar predictions for other subjects have not changed, the *consequences* of these updates, aka “ripple effects”, should also be evaluated (screenshot).
#papers #nlp #nlproc #knowledge #knowledgegraph
Benjamin Han · @BenjaminHan
460 followers · 1256 posts · Server sigmoid.social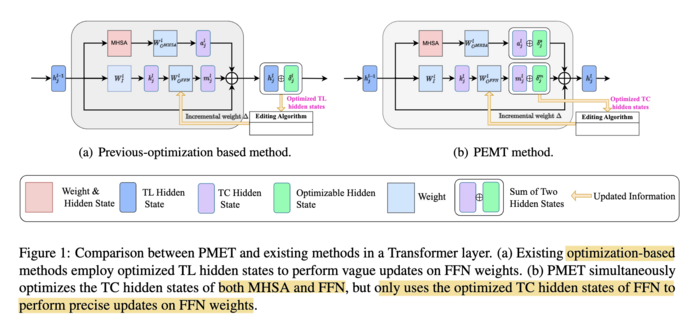
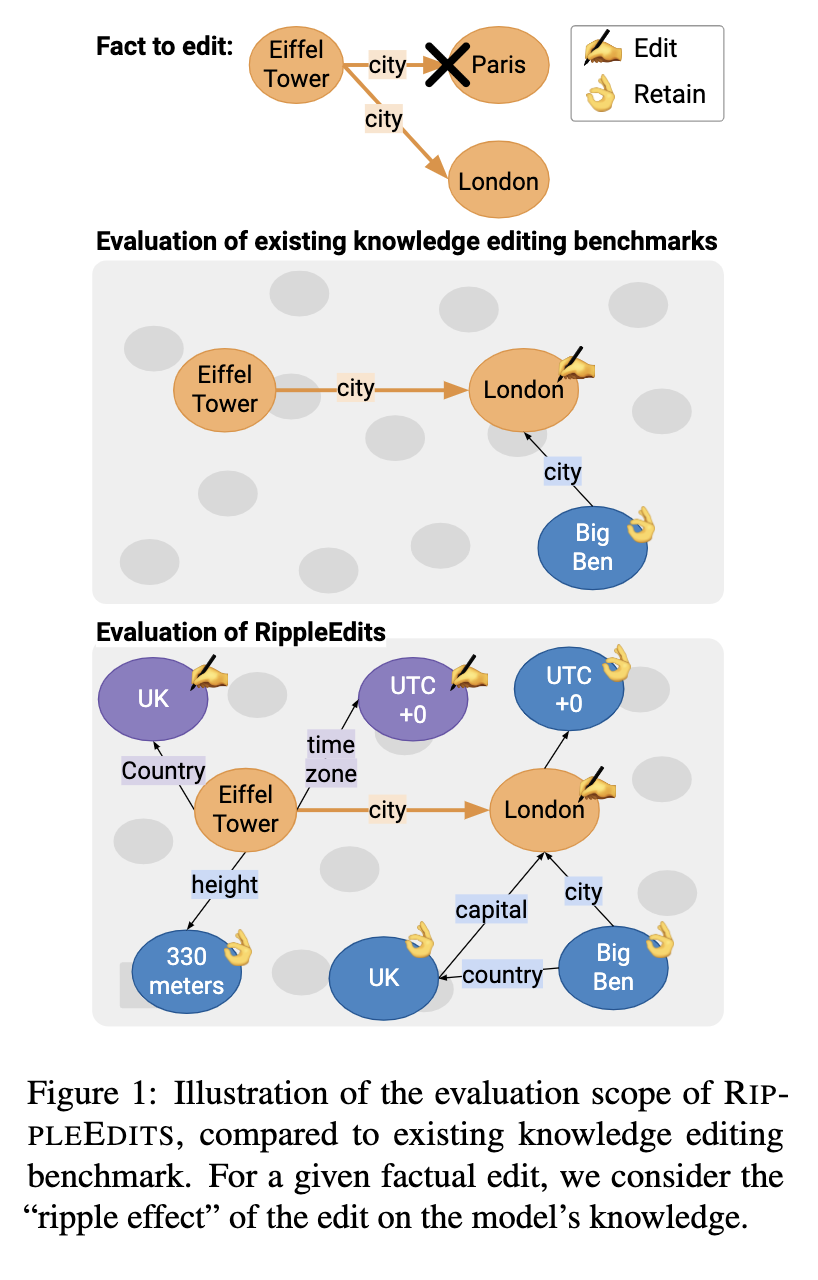
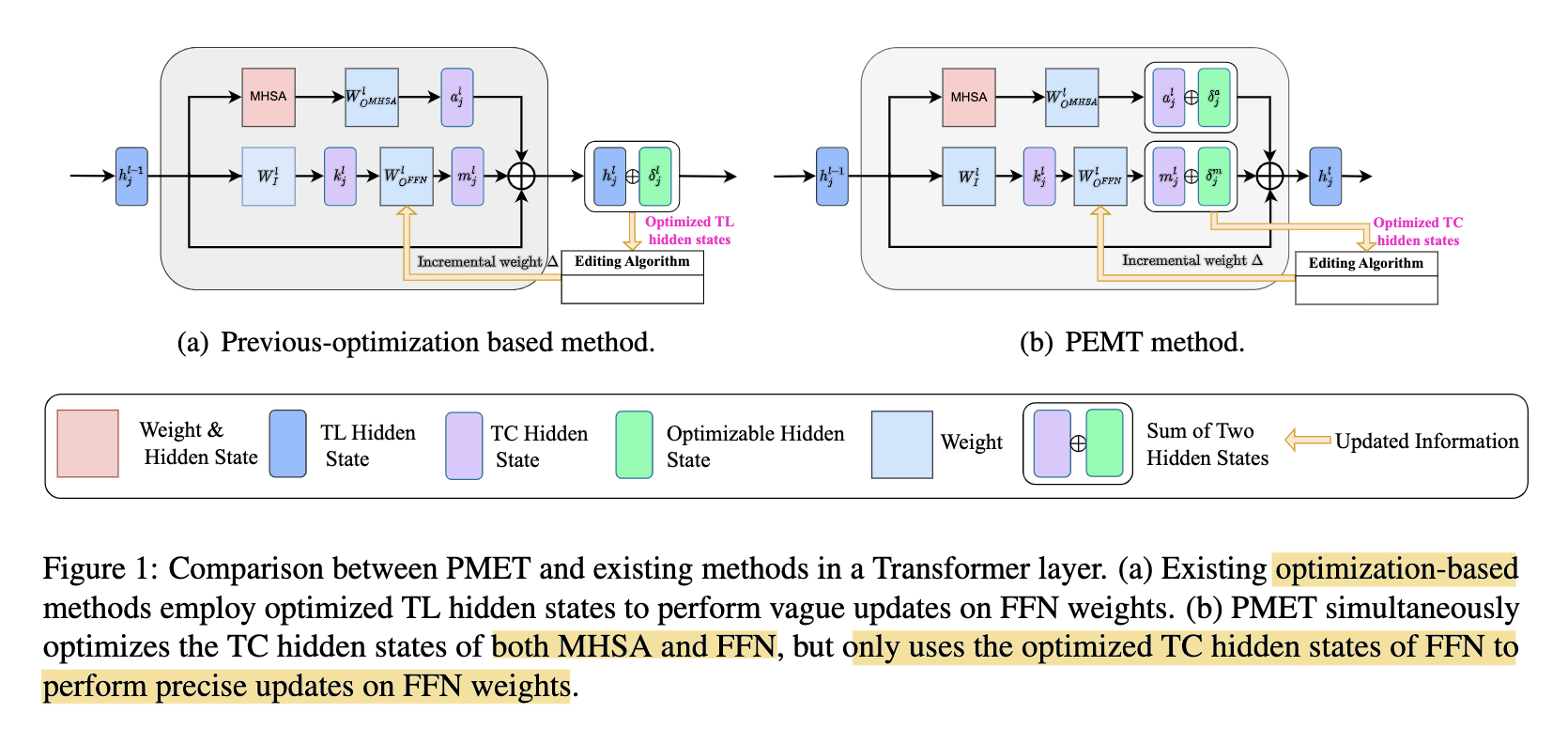
4/ They then propose PMET (Precise Model Editing in a Transformer), which effectively moves weight optimization upstream. And while trying to optimize both MHSA and FFN, it only updates on FFN weights to preserve specificity (screenshot 1). The result is much more stable performance as number of edits increases (screenshot 2), and better overall results (screenshot 3).
#papers #nlp #nlproc #knowledge #knowledgegraph
Benjamin Han · @BenjaminHan
460 followers · 1256 posts · Server sigmoid.social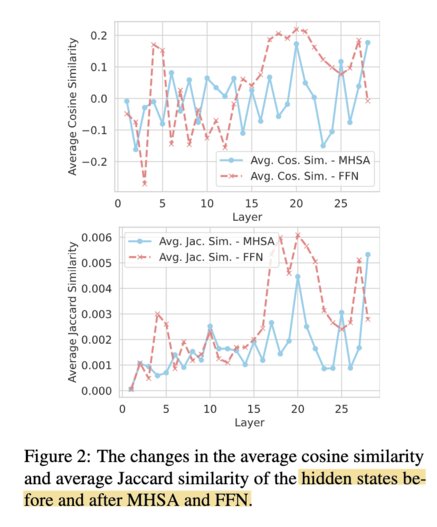
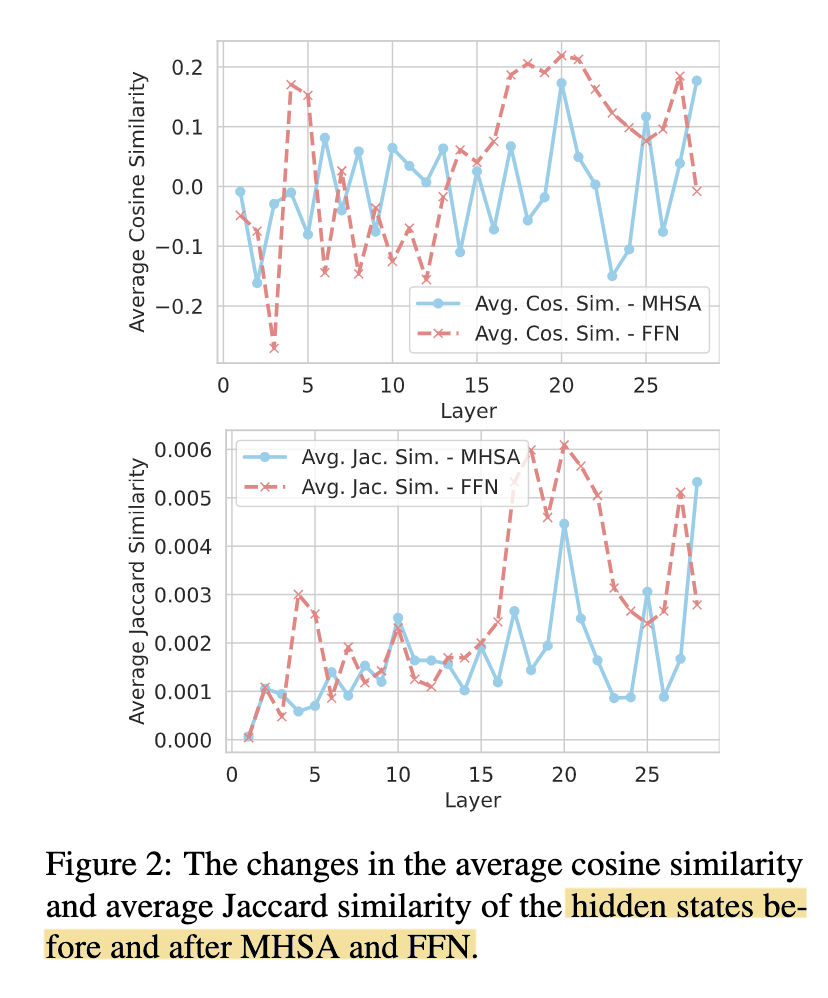
3/ By computing the similarities of the hidden states of MHSA and FFN before and after each layer, they observe FFN stabilizes much earlier than MHSA, thus concluding that MHSA encodes more general knowledge extraction patterns while FFN captures more factual aspect of knowledge (screenshot).
#papers #nlp #nlproc #knowledge #knowledgegraph
Benjamin Han · @BenjaminHan
460 followers · 1256 posts · Server sigmoid.social2/ Building on ROME/MEMIT, the authors of a more recent work [4] hypothesize that optimizing transformer layer hidden states to update knowledge may be too much, as these parameters contain simultaneously the effect from Multi-head Self-Attention (MHSA), feed-forward network (FFN), and residual connections.
#papers #nlp #nlproc #knowledge #knowledgegraph
Benjamin Han · @BenjaminHan
460 followers · 1256 posts · Server sigmoid.social1/ Can we "edit" #LLMs to update incorrect/outdated facts without costly retraining? Recent works such as training auxiliary models to predict weight changes in the main model (MEND) [1], locating "knowledge neurons" [2], using causal intervention to identify feed-forward network (FFN) weights to edit in ROME [3], and scaling up editing operations to thousands of associations in MEMIT [4] have proven it's doable, even practical.
#LLMs #papers #nlp #nlproc #knowledge #knowledgegraph

OpenBiblioJobs · @obj
639 followers · 13860 posts · Server openbiblio.socialSoftwareentwickler*in, TVL E 13, Vollzeit, 5 Jahre + ggf. Entfristung Verbundzentrale des GBV (VZG) | Bewerbungsfrist: 10.09.2023 https://www.gbv.de/news/stellen/pdf/stellenausschreibung_nr_4_ds2_2023.pdf | https://jobs.openbiblio.eu/stellenangebote/92780/ #openbibliojobs #MobilesArbeiten #KnowledgeGraph #Entwickler*in #Infrastruktur #Telearbeit #Discovery #Metadaten #Geodaten #Software #NFDI
#openbibliojobs #mobilesArbeiten #knowledgegraph #entwickler #infrastruktur #telearbeit #discovery #metadaten #geodaten #software #NFDI
Benjamin Han · @BenjaminHan
449 followers · 1210 posts · Server sigmoid.social
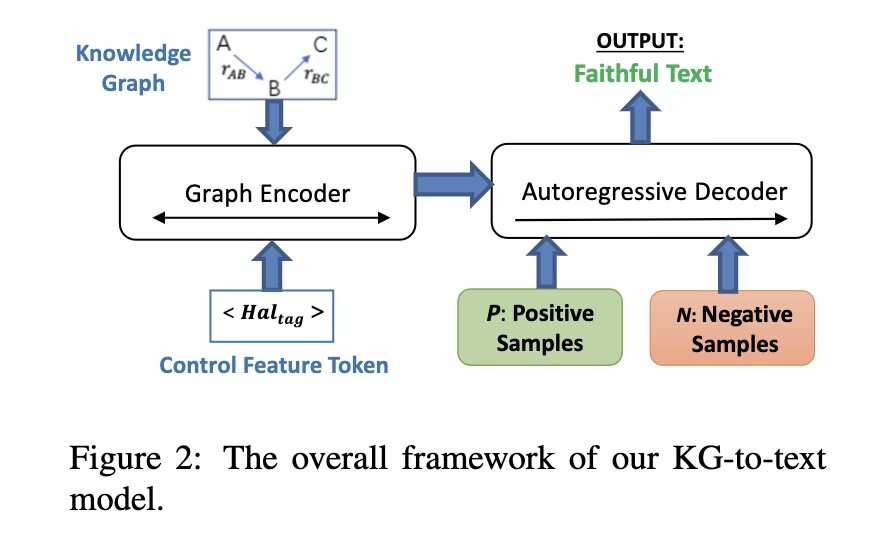
Using contrastive loss and binned BARTScore as input improves faithfulness of knowledge-to-text generation.
Tahsina Hashem, Weiqing Wang, Derry Tanti Wijaya, Mohammed Eunus Ali, and Yuan-Fang Li. 2023. Generating Faithful Text From a #KnowledgeGraph with Noisy Reference Text. http://arxiv.org/abs/2308.06488
#knowledgegraph #paper #nlp #nlproc #generativeAI
Benjamin Han · @BenjaminHan
449 followers · 1210 posts · Server sigmoid.social
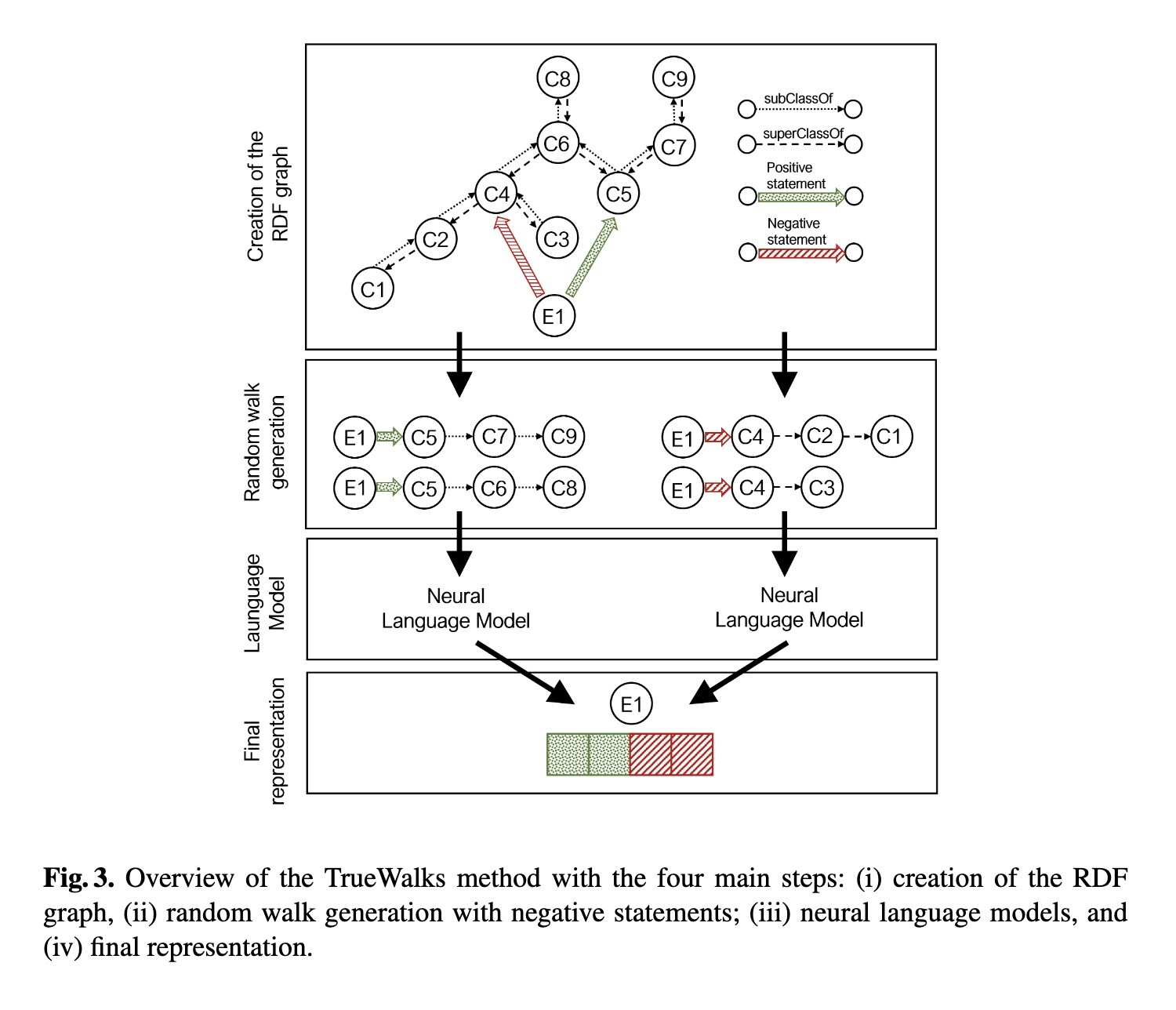
Generating positive AND negative walks through #ontological relations subclassOf and superClassOf improves protein-protein interaction and gene-disease association classification tasks.
Rita T. Sousa, Sara Silva, Heiko Paulheim, and Catia Pesquita. 2023. Biomedical Knowledge Graph Embeddings with Negative Statements. arXiv [cs.AI]. http://arxiv.org/abs/2308.03447
#ontological #paper #knowledgegraph #nlp #nlproc #biomedical
Harald Sack · @lysander07
715 followers · 429 posts · Server sigmoid.social
Awesome keynote presentation by @vrandecic on "The Future of Knowledge Graphs in a World of Large Language Models"
video: https://www.youtube.com/watch?v=WqYBx2gB6vA
#knowledgegraph #llm #largelanguagemodel #foundationmodel #ai #artificialintelligence #semanticweb #Wikidata
#knowledgegraph #llm #largelanguagemodel #foundationmodel #ai #artificialintelligence #semanticweb #wikidata
Harald Sack · @lysander07
679 followers · 417 posts · Server sigmoid.social
"InteractOA: Showcasing the representation of knowledge from scientific literature in Wikidata" by Muhammad Elhossary and Konrad Förstner.
InteractOA is a frontend interface displaying visualizations of prokaryotic regulatory small RNA interaction networks, with #PubMed Central article citations for evidence based on #Wikidata.
paper: https://www.semantic-web-journal.net/system/files/swj3369.pdf
InteractOA demo: https://interactoa.toolforge.org/
GitHub: https://github.com/foerstner-lab/InteractOA
#knowledgegraph #SemanticWeb #demo @ZBMED
#pubmed #wikidata #knowledgegraph #semanticweb #demo

Tane Piper · @tanepiper
1153 followers · 4143 posts · Server tane.codes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
We're #hiring at #IKEA - first up on our #knowledgeGraph team
Digital Product Leader - https://en-jobs.about.ikea.com/job/malmo/digital-product-leader-ikea-knowledge-graph/24107/52654183264
Knowledge Engineer - https://en-jobs.about.ikea.com/job/malmo/knowledge-engineer-ikea-knowledge-graph/24107/52405078096