
C:\KKJ\>:idle: · @w84death
752 followers · 399 posts · Server fosstodon.org

Mario Alberto Chávez · @mario_chavez
51 followers · 45 posts · Server ruby.socialI just pushed changes to LLM Server, a Rack Ruby server that wraps llama.cpp binary to allow you to run LLM models via an API.
By default, it loads the model one in memory and executes it in interactive mode.
It works fine for Open Llama or Vicuna models but not for models like Orca. A non-interactive mode was introduced for them. It is fast for smaller models like Orcas's 3b.
I have been using quantized models from @thebloke
with success.
C:\KKJ\>:idle: · @w84death
718 followers · 338 posts · Server fosstodon.org
David Burela · @DavidBurela
154 followers · 24 posts · Server hachyderm.io
I've been working with #LLM to explore patterns that allows for running on #EdgeCompute or #Azure #OpenAI
I've found using a combination of #Langchain & #llamacpp allows me to do this.
I've created a small example repo, that shows how to quickly get up and running with GPU support.
#llm #edgecompute #azure #openai #langchain #llamacpp

Dr. Fortyseven ◣ ◥◣ ◥ 🥃 · @fortyseven
600 followers · 2108 posts · Server defcon.social
In case you're wondering how the "run ChatGPT" at home race is going, here's a locally run, CPU-powered "13b q5_1 Vicuna" model on #llamacpp versus #Bard, #BingChat, and #ChatGPT itself.
"What are my first steps for teaching a newborn baby how to breakdance?"
#llamacpp #bard #bingchat #chatgpt #ai #llms
onion · @onion
30 followers · 247 posts · Server mastodon.tal.org
ダニエル · @bietiekay
31 followers · 55 posts · Server mas.to
ja richtig. Ohne Grafikkarte. Man braucht eigentlich nur https://github.com/antimatter15/alpaca.cpp und die in der readme angegebenen Models. Das 13B ist seit ein paar Stunden verfügbar und läuft bei mir mit mittelalterlicher Hardware „fast enough“. Auf moderner Hardware ist das praktisch schon unheimlich was man damit machen kann.... zuhause. Einfach so. Living the future. #alpacacpp #largelanguagemodel #llamacpp
#llamacpp #largelanguagemodel #alpacacpp
ダニエル · @bietiekay
31 followers · 55 posts · Server mas.to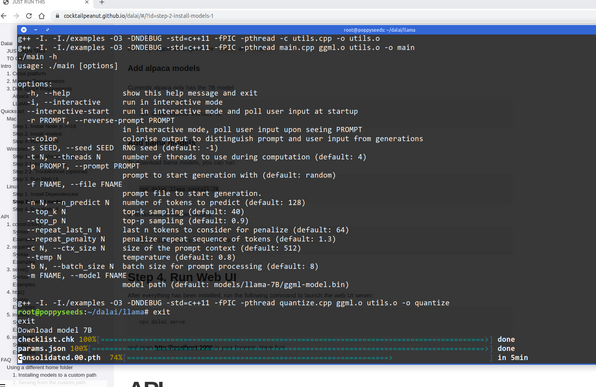
{kind=link}
{kind=link}
{kind=link}
{kind=link}
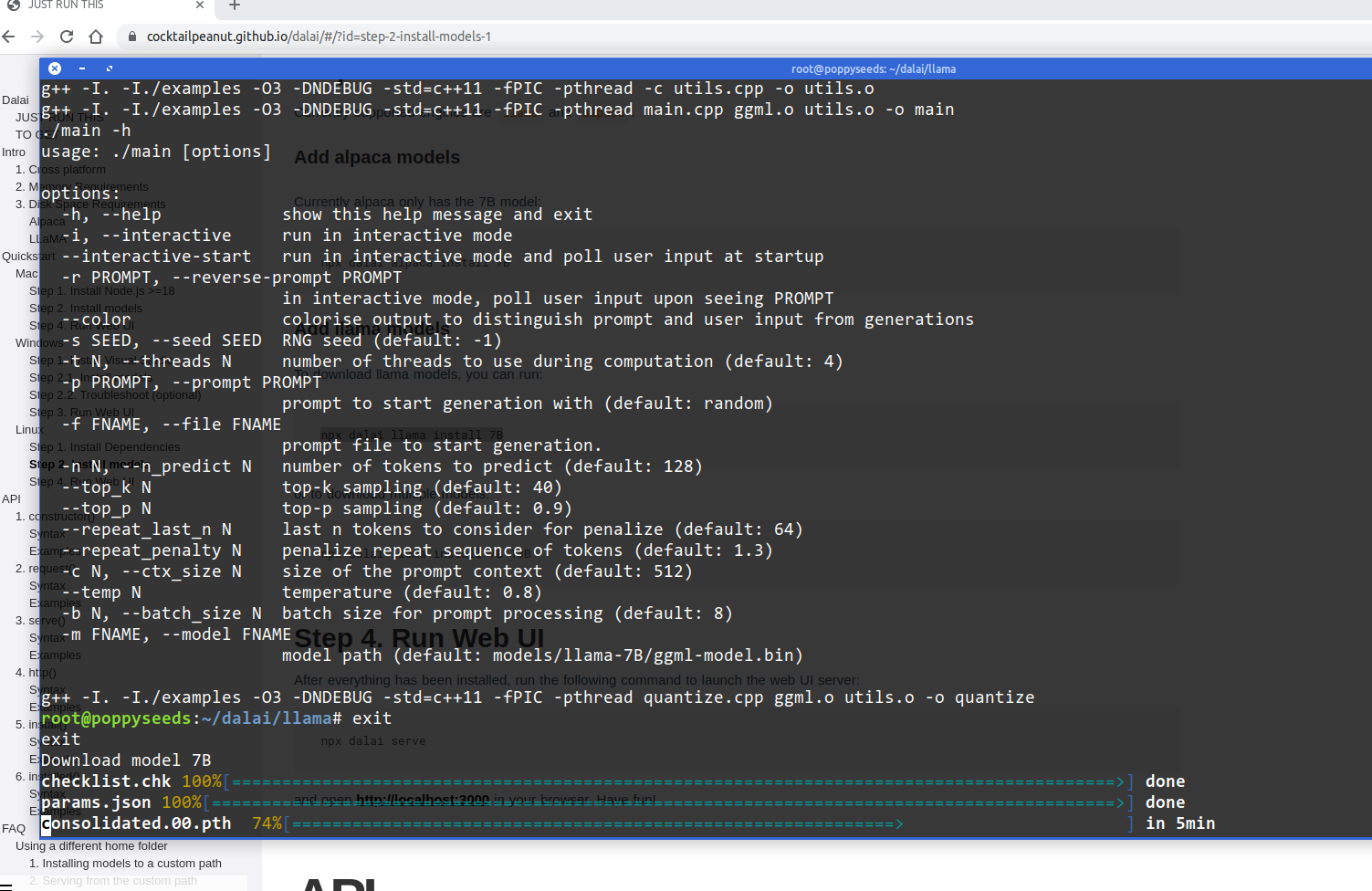
nagut, dann installier ich das halt mal.... diese Projektnamen, ich muss die ganze Zeit grinsen.... "npx dalai llama install 7B" #dalai #llama #llamacpp #alpacacpp #alpacacpp
#alpacacpp #llamacpp #llama #dalai