
Benjamin Han · @BenjaminHan
477 followers · 1330 posts · Server sigmoid.social
AI-generated sports news.
Gannett Stops Using AI To Write Articles For Now Because They Were Hilariously Terrible https://www.techdirt.com/2023/09/01/gannett-stops-using-ai-to-write-articles-for-now-because-they-were-hilariously-terrible/
#nlp #nlproc #generativeAI #sportsjournalism

IJCNLP-AACL 2023 · @aaclmeeting
94 followers · 7 posts · Server sigmoid.socialIJCNLP-AACL 2023 has accepted exciting tutorials!
Check out the list!
http://afnlp.org/conferences/ijcnlp2023/wp/sample-page/tutorial/accepted-tutorials/
#AACL2023 #NLProc
Benjamin Han · @BenjaminHan
477 followers · 1327 posts · Server sigmoid.social4/
[3] Dhananjay Ashok and Zachary C. Lipton. 2023. PromptNER: Prompting For Named Entity Recognition. http://arxiv.org/abs/2305.15444
[4] https://paperswithcode.com/sota/named-entity-recognition-ner-on-conll-2003
[5] https://paperswithcode.com/sota/named-entity-recognition-on-genia
#nlp #nlproc #knowledgegraph #paper
Benjamin Han · @BenjaminHan
477 followers · 1326 posts · Server sigmoid.social3/
REFERENCES
[1] Previous posts on ICL and why it works: https://www.linkedin.com/posts/benjaminhan_llms-iclr2023-mastodon-activity-7093281970792632320-XE87, https://www.linkedin.com/posts/benjaminhan_generativeai-gpt4-llm-activity-7045542002947457024-bGPt/, https://www.linkedin.com/posts/benjaminhan_llms-gpt3-nlp-activity-7073726814170337280-EED5/
#nlp #nlproc #knowledgegraph #paper
Benjamin Han · @BenjaminHan
477 followers · 1326 posts · Server sigmoid.social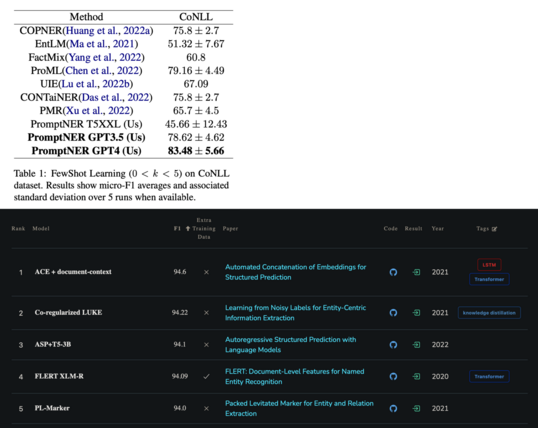
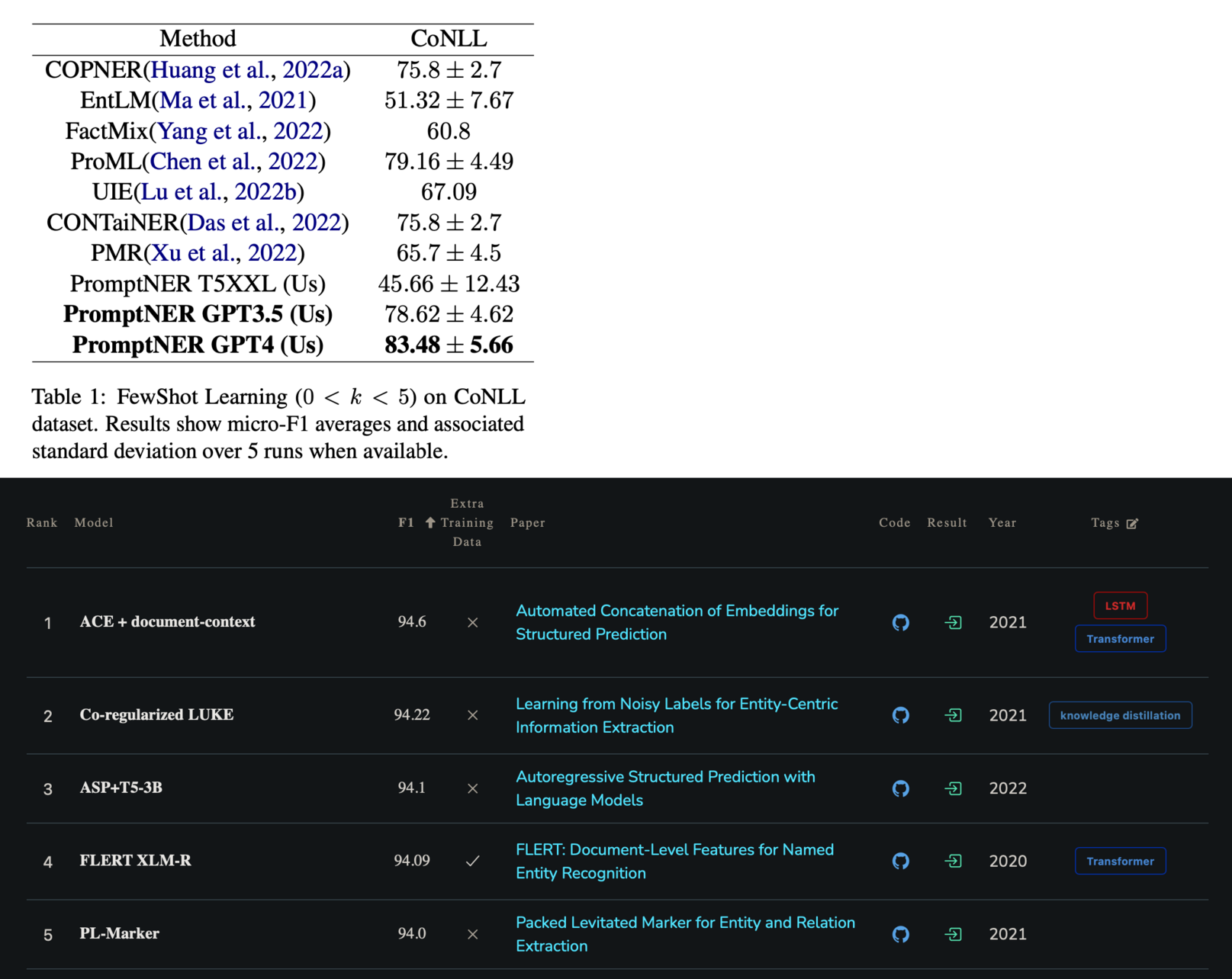
2/ One particular recent paper in the discussion proposed an ICL approach named PromptNER [3], and reported SOTA results among its ICL peers on well-known datasets such as CoNLL 2003 and GENIA. Compared its results with the SOTA *fine-tuning* (FT) solutions, FT outperforms on CoNLL by 10+ points (94.6 vs. 83.48; screenshot 1) [4], and outperforms on GENIA too by 20+ points (80.8 vs. 58.44; screenshot 2) [5].
#nlproc #knowledgegraph #paper

Michael Piotrowski · @mxp
743 followers · 1444 posts · Server mastodon.acm.orgPour compléter une équipe dans le cadre d’un projet de visualisation automatique d’environnements sémantiques appliqué au domaine de la recherche (CompaSciences), l’Institut des sciences sociales de l’Université de Lausanne #UNIL met au concours un poste de
Développeur·euse #NLProc et #visualisation de données
#unil #nlproc #visualisation #job #lausanne

Federico Pianzola · @fpianz
423 followers · 260 posts · Server mstdn.socialWe're hiring a Postdoc to work across NLP, Digital Humanities, and Semantic Web. https://www.rug.nl/about-ug/work-with-us/job-opportunities/?details=00347-02S000AC8P
Bring your creativity and skills to study the evolution of online fictional narratives https://golemlab.eu
@gronlp
#AcademicChatter
#DH #LinkedData #KnowledgeGraphs #nlproc @digitalhumanities @TedUnderwood @scott_bot @christof @fotis_jannidis @zoeleblanc @quinnanya @folgertk @melvinwevers @albertoacerbi @EvelynGius @DHd @dh_potsdam
#nlproc #KnowledgeGraphs #linkeddata #dh #academicchatter

Saad Mahamood · @Saad
21 followers · 123 posts · Server sigmoid.socialPutting together my presentation for tomorrow's HumEval 2023 session of NLP reproducibility (https://humeval.github.io). I will also be heading next week to Prague for INLG 2023 (https://inlg2023.github.io) with my master student. Hopefully get to see folks who I haven't seen in some time in person!
#nlproc #NaturalLanguageGeneration #humeval #inlg

UKP Lab · @UKPLab
57 followers · 58 posts · Server sigmoid.social
UKP Lab · @UKPLab
57 followers · 58 posts · Server sigmoid.social
SIGGEN · @siggen_acl
12 followers · 4 posts · Server fediscience.orgOne week left until events kick off for #SIGDIALxINLG2023! You can still register to join us on-site in Prague or, if you can't make it all the way to Czechia, join us virtually!
Virtual registration is free, to enable as many people to join the conference as possible, so please share far and wide: https://sigdialinlg2023.github.io/
#PleaseBoost #NaturalLanguageGeneration #Dialogue #Discourse #NLProc #ComputationalLinguistics
#computationallinguistics #nlproc #discourse #dialogue #NaturalLanguageGeneration #PleaseBoost #sigdialxinlg2023

Marco Zocca · @ocramz
180 followers · 216 posts · Server sigmoid.socialOf the 3 papers I co-reviewed for #emnlp2023 , 2 used chatgpt for generation or evaluation.
Does anyone see a problem with littering our research with proprietary, black-box baselines?
#emnlp2023 #nlproc #nlp #OpenScience
Benjamin Han · @BenjaminHan
475 followers · 1305 posts · Server sigmoid.social
“This statement is endorsed by the following members of the GPA’s International Enforcement Cooperation Working Group (“IEWG”).”
Joint statement on data scraping and the protection of privacy https://ico.org.uk/media/about-the-ico/documents/4026232/joint-statement-data-scraping-202308.pdf
#copyright #privacy #generativeAI #law #nlproc
Benjamin Han · @BenjaminHan
472 followers · 1301 posts · Server sigmoid.social
11/end
[3] Previously: “Model Editing: Performing Digital Brain Surgery”. https://www.linkedin.com/posts/benjaminhan_llms-causal-papers-activity-7101756262576525313-bIge
[4] Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. 2023. Unifying Large Language Models and Knowledge Graphs: A Roadmap. http://arxiv.org/abs/2306.08302
#KnowledgeGraphs #generativeAI #LLMs #nlp #nlproc #paper
Benjamin Han · @BenjaminHan
472 followers · 1295 posts · Server sigmoid.social8/ There are surely other benefits of using KGs to collect and organize knowledge. They do not require costly retraining to update, therefore can be updated more frequently to remove obsolete or incorrect facts. They allow more trackable reasoning and can offer better explanations. They make fact editing more straightforward and accountable (think of GDPR) compared to model editing [3].
#KnowledgeGraphs #generativeAI #LLMs #nlp #nlproc #paper
Benjamin Han · @BenjaminHan
472 followers · 1294 posts · Server sigmoid.social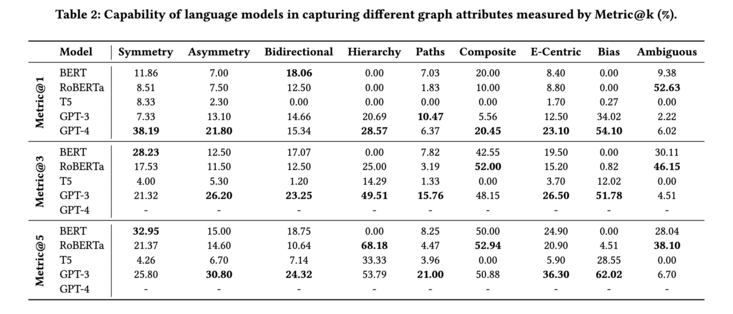
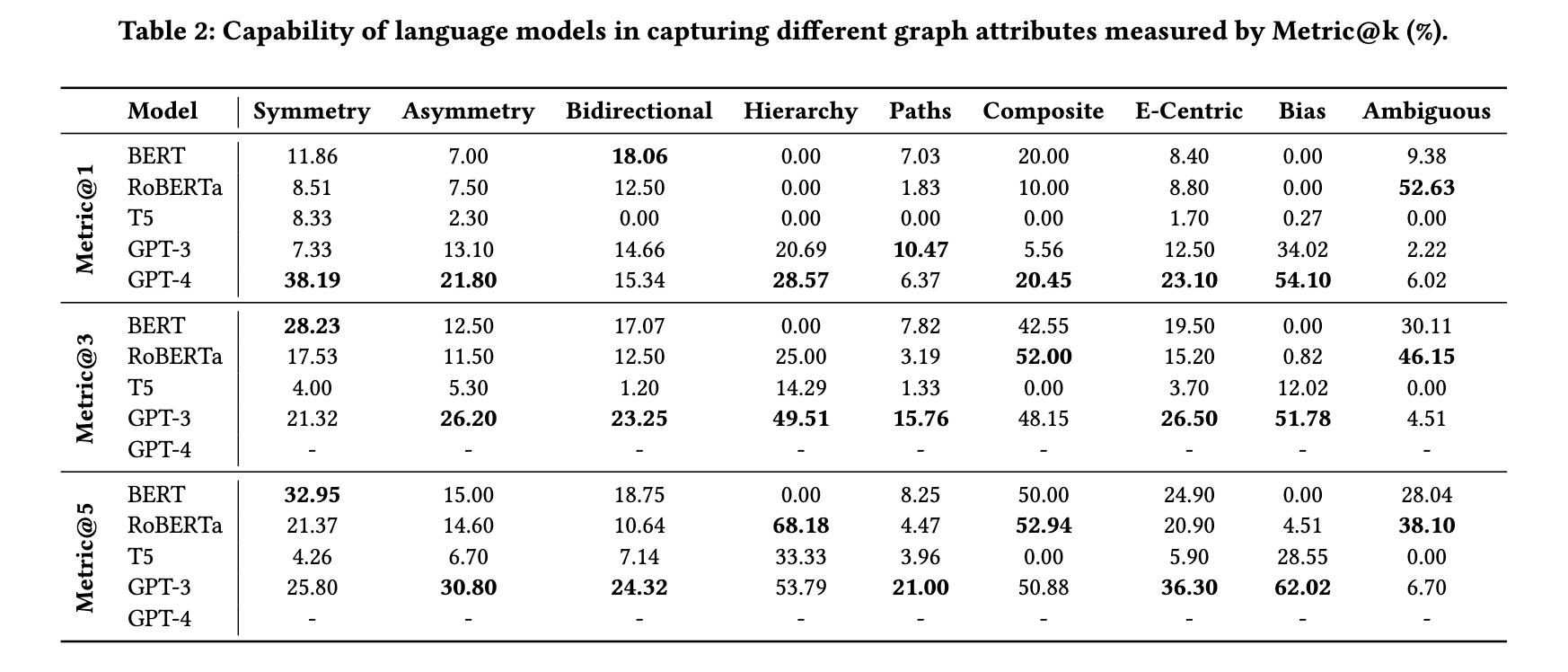
7/ Their result shows that even #GPT4 achieves only 23.7% hit@1 on average, even when it scores up to 50% precision@1 using the earlier proposed LAMA benchmark (screenshot). Interestingly, smaller models like BERT can outperform GPT4 on bidirectional, compositional, and ambiguity benchmarks, indicating bigger is not necessarily better.
#gpt4 #KnowledgeGraphs #generativeAI #LLMs #nlp #nlproc #paper
Benjamin Han · @BenjaminHan
472 followers · 1294 posts · Server sigmoid.social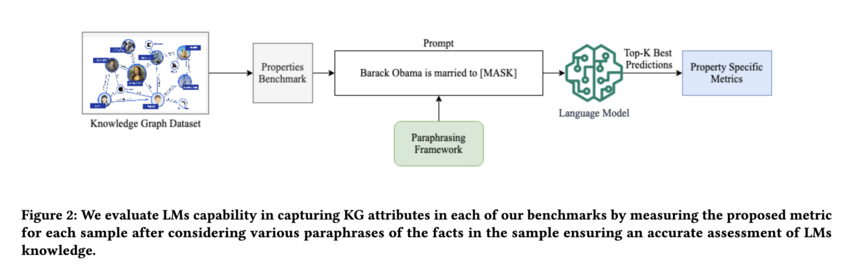
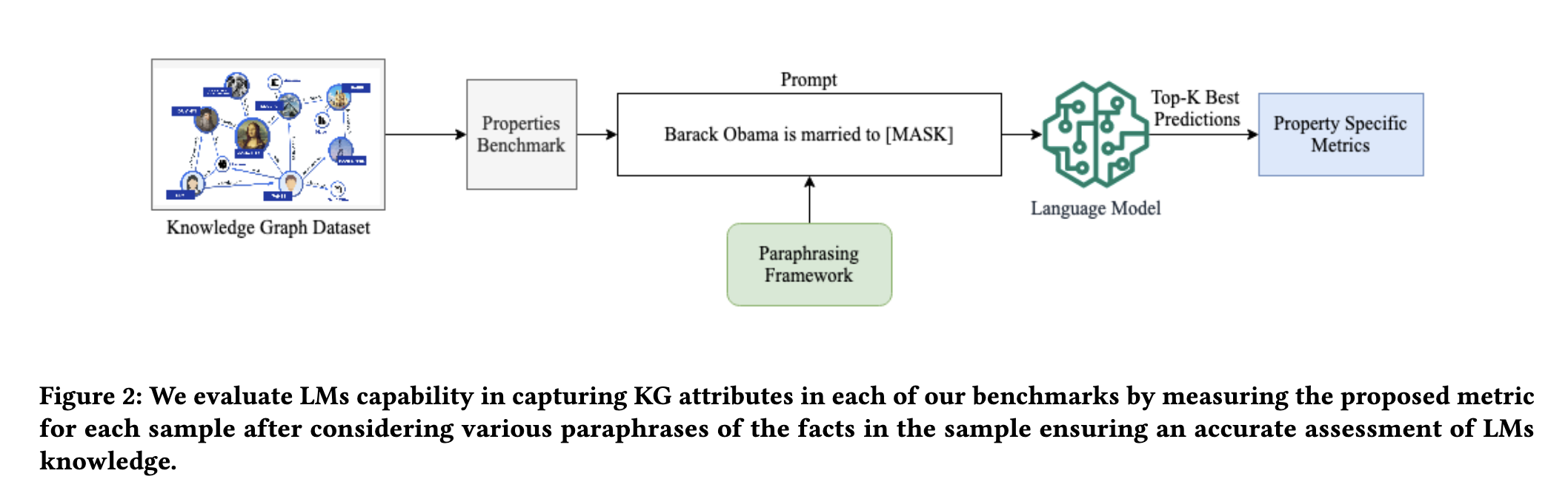
6/ In each benchmark, instead of asking LLMs to retrieve masked words from a cloze statement, it also asks the LLMs to retrieve all of the implied facts and compute scores accordingly (screenshot).
#KnowledgeGraphs #generativeAI #LLMs #nlp #nlproc #paper
Benjamin Han · @BenjaminHan
472 followers · 1294 posts · Server sigmoid.social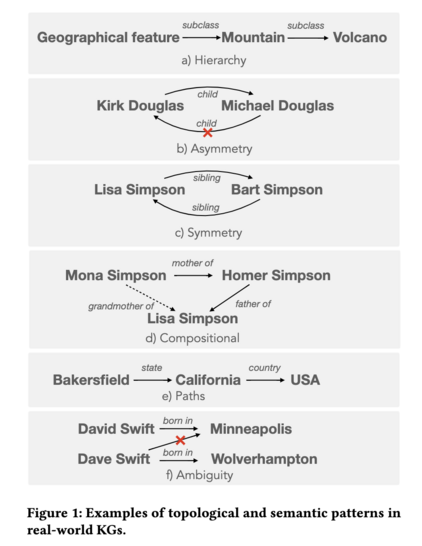
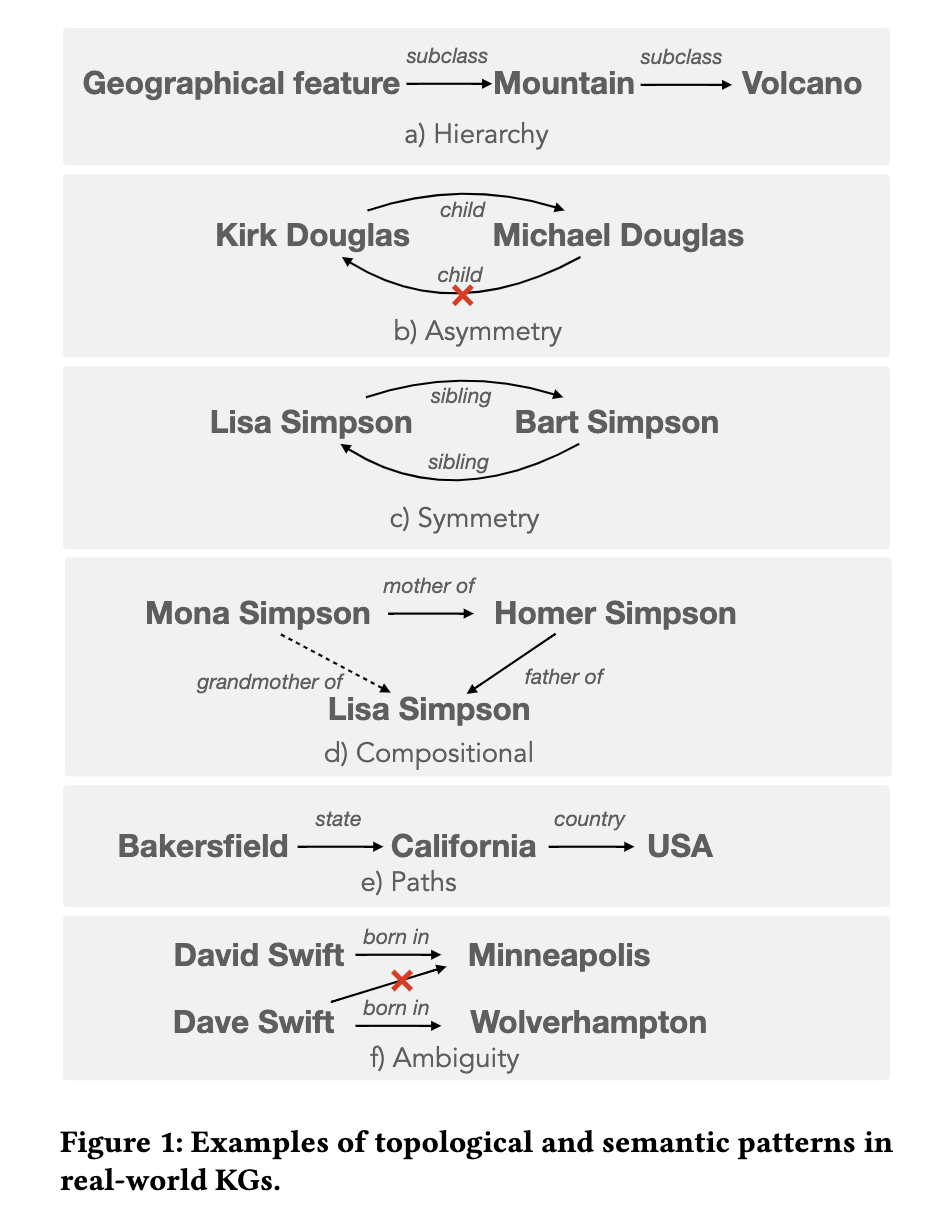
5/ Instead, they focus on more intricate topological and semantic attributes of facts, and propose 9 benchmarks testing modern LLMs’ capability in retrieving facts with the following attributes: symmetry, asymmetry, hierarchy, bidirectionality, compositionality, paths, entity-centricity, bias and ambiguity (screenshots).
#KnowledgeGraphs #generativeAI #LLMs #nlp #nlproc #paper
Benjamin Han · @BenjaminHan
472 followers · 1290 posts · Server sigmoid.social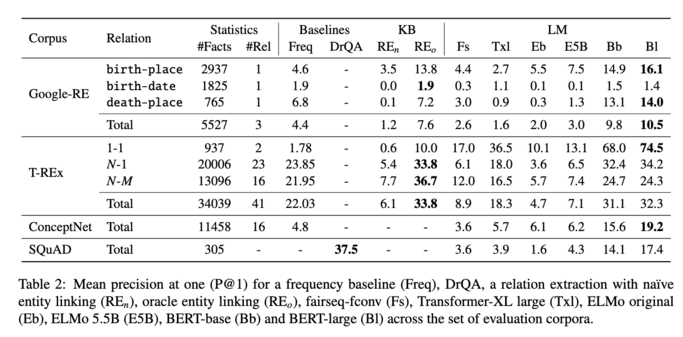
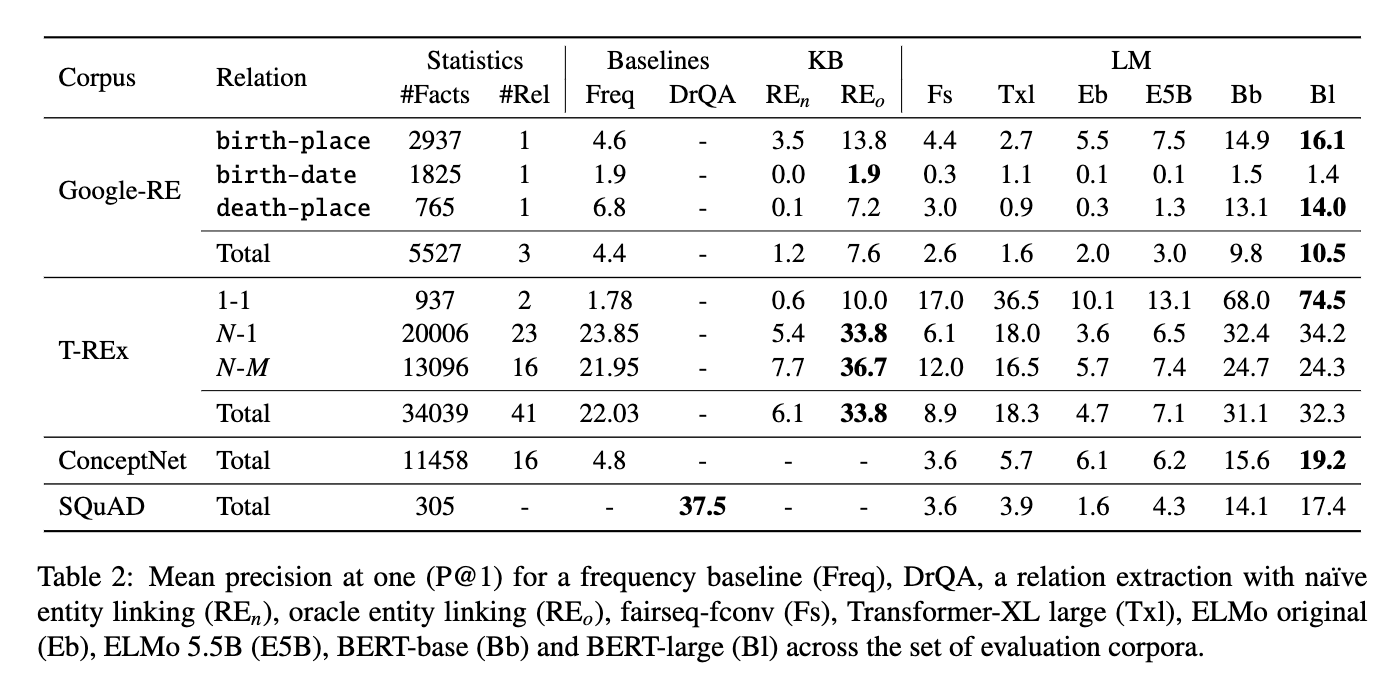
3/ The result shows that even without specialized training, language models such as BERT-large can already retrieve decent amount of facts from their weights (screenshot).
#KnowledgeGraphs #generativeAI #LLMs #nlp #nlproc #paper
Benjamin Han · @BenjaminHan
472 followers · 1290 posts · Server sigmoid.social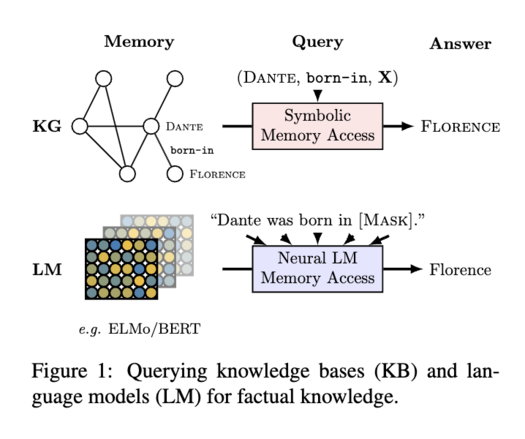
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
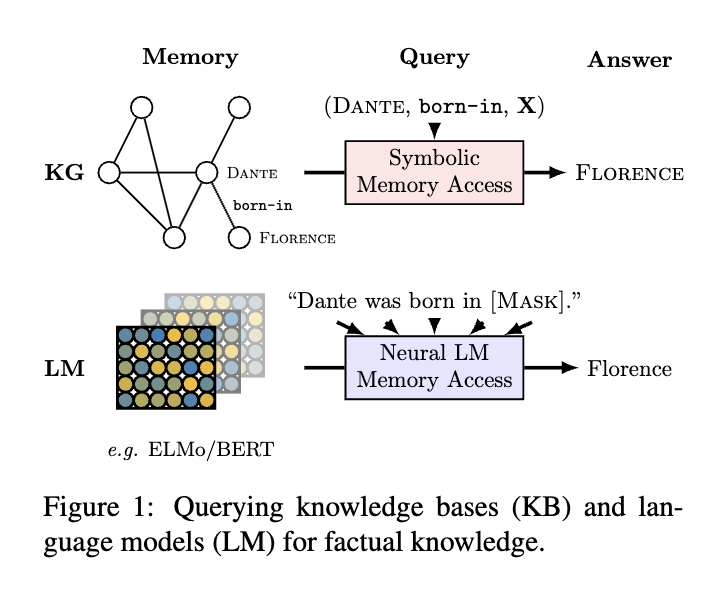
2/ An early paper in 2019 [1] posited that compared to #KnowledgeGraphs, it is easier for language models to adapt to new data without human supervision, and they allow users to query about an open class of relations without much restriction. To measure the knowledge encoding capability, the authors construct the LAMA (Language Model Analysis) probe where facts are turned into cloze statements and language models are asked to predict the masked words (screenshot).
#KnowledgeGraphs #nlp #nlproc #paper