
Herbert Hertramph · @_DigitalWriter_
921 followers · 2416 posts · Server bildung.social
"Aber der Staub? ruft die Hausfrau. "Staub der liegt, schadet nicht" pflegte ein bekannter Mediziner zu erwidern. 😃
Diesmal nur Foto eingestellt - die interne Texterkennung von #paperlessngx hat sich recht wacker geschlagen.
#paperlessngx #geschichte #font #fraktur #scan #bucher #ocr

· @dehypotheses
1355 followers · 437 posts · Server fedihum.org
À ne pas rater, la keynote de notre atelier ATR par Dominique Stutzmann (IRHT/Humboldt-univ.):
"La reconnaissance automatique des textes (ATR). Nouveaux horizons pour les historiennes et les historiens"
07/09/2023
18h00
Sur place & en ligne
Infos 👉https://ow.ly/1QVC50PHl7t
#ATR #OCR #HTR #HumanitésNumériques #HistoireNumérique #DigitalHumanities
#atr #ocr #htr #humanitesnumeriques #histoirenumerique #DigitalHumanities

DHI Paris · @dhiparis
429 followers · 41 posts · Server wisskomm.social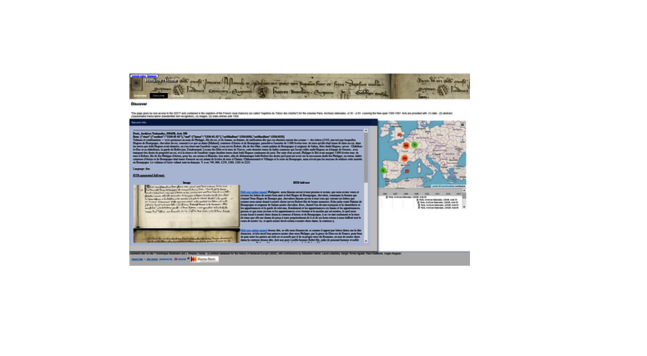
Nicht verpassen, die Keynote zu unserem ATR-Workshop von Dominique Stutzmann (IRHT/Humboldt-Univ.):
"Automatische Texterkennung (ATR). Neue Möglichkeiten für Historikerinnen und Historiker"
07.09.2023
18 Uhr
Online & vor Ort
Infos 👉 https://ow.ly/9eAt50PHkY3
#atr #ocr #htr #digitalhumanities #dh #digitalhistory

Greg Lopez · @nerdyblinddude
11 followers · 142 posts · Server dragonscave.spaceForgot to mention this the day it happened, but just remembered it: Successfully used #Lookout for #Android to pull text from a screenshot I took on my computer so I could obtain the password for my #ProtonMail bridge setup so I could have automatic #encryption for my email in #Thunderbird I had tried that #OCR add-on for #NVDA but it didn't read the text correctly but Lookout did. Lookout still can be iffy, and I could have used #BixbyVision to try and get it, but once I got it, that's all I needed.
#lookout #android #protonmail #encryption #thunderbird #ocr #nvda #bixbyvision

olson · @olson
28 followers · 68 posts · Server mountains.social

Jürgen Hubert · @juergen_hubert
2419 followers · 6406 posts · Server thefolklore.cafeCan anyone recommend free #OCR Software?
The ability to scan Fraktur typeset would be a bonus, but I'll take standard Antiqua font for starters.
DHI Paris · @dhiparis
429 followers · 41 posts · Server wisskomm.social
Workshop: "Von der historischen Quelle zum Volltext. Anwendung automatisierter Schrifterkennung (ATR)"
Mehr Infos ➡️ https://ow.ly/WqzQ50PGM5H
Nächste Woche am DHIP!
07.09.2023–08.09.2023
#atr #ocr #htr #digitalhumanities #dh #digitalhistory

Phillip Ströbel · @phillipstroebel
156 followers · 37 posts · Server techhub.socialFinally, our fine-tuned #TrOCR model for #16thcentury #correspondence data (i. e., the #Bullinger #letters) is on @huggingface: https://huggingface.co/pstroe/bullinger-general-model
Have fun!
For more information: https://doi.org/10.5167/uzh-234886 & bullinger-digital.ch
#HTR #OCR #digitalhumanities #digitalhistory
#trocr #16thcentury #correspondence #bullinger #letters #htr #ocr #digitalhumanities #digitalhistory

Stefan Weil · @sw
41 followers · 19 posts · Server openbiblio.social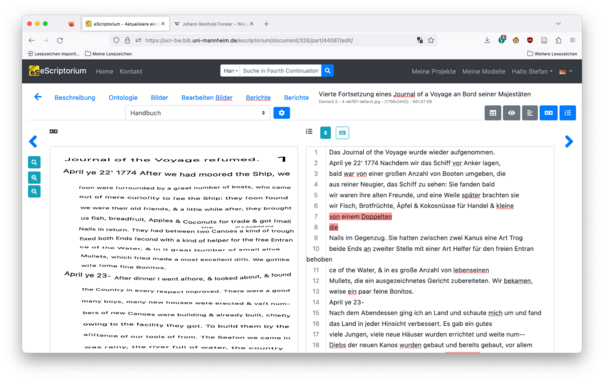
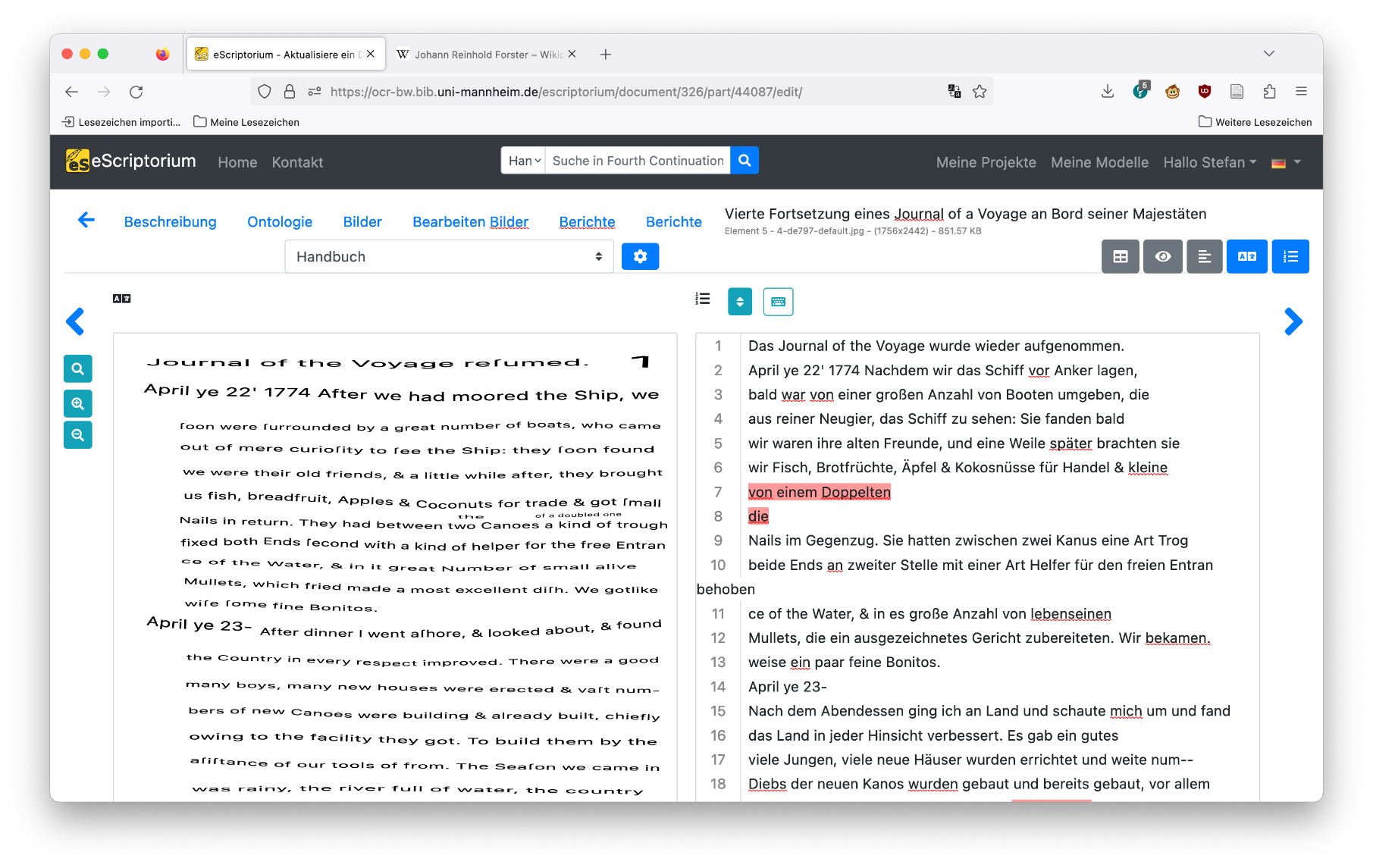
Erkennung von #Handschrift mit #eScriptorium und #kraken #OCR kombiniert mit #Firefox Translations bietet interessante neue Möglichkeiten wie diese Übersetzung der Reisetagebücher von Johann Reinhold Forster.
#Handschrift #escriptorium #kraken #ocr #firefox
Phillip Ströbel · @phillipstroebel
141 followers · 36 posts · Server techhub.socialMy thesis has been published & is now available: https://doi.org/10.5167/uzh-234886
I recommend Chapter 4 if you are interested in #HTR & what #Transformers can do for #historical #documents. #digitalhumanities #OCR
Thanks again to my supervisors Martin Volk & @thist, & everyone at the Department of Computational Linguistics from the University of Zurich!
#htr #transformers #historical #documents #digitalhumanities #ocr

Alan McConchie · @alan
1168 followers · 683 posts · Server subdued.social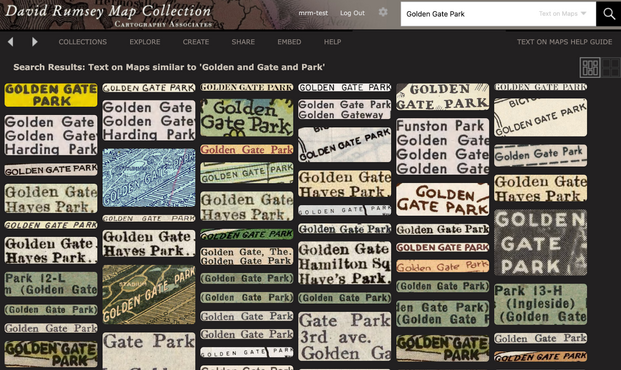
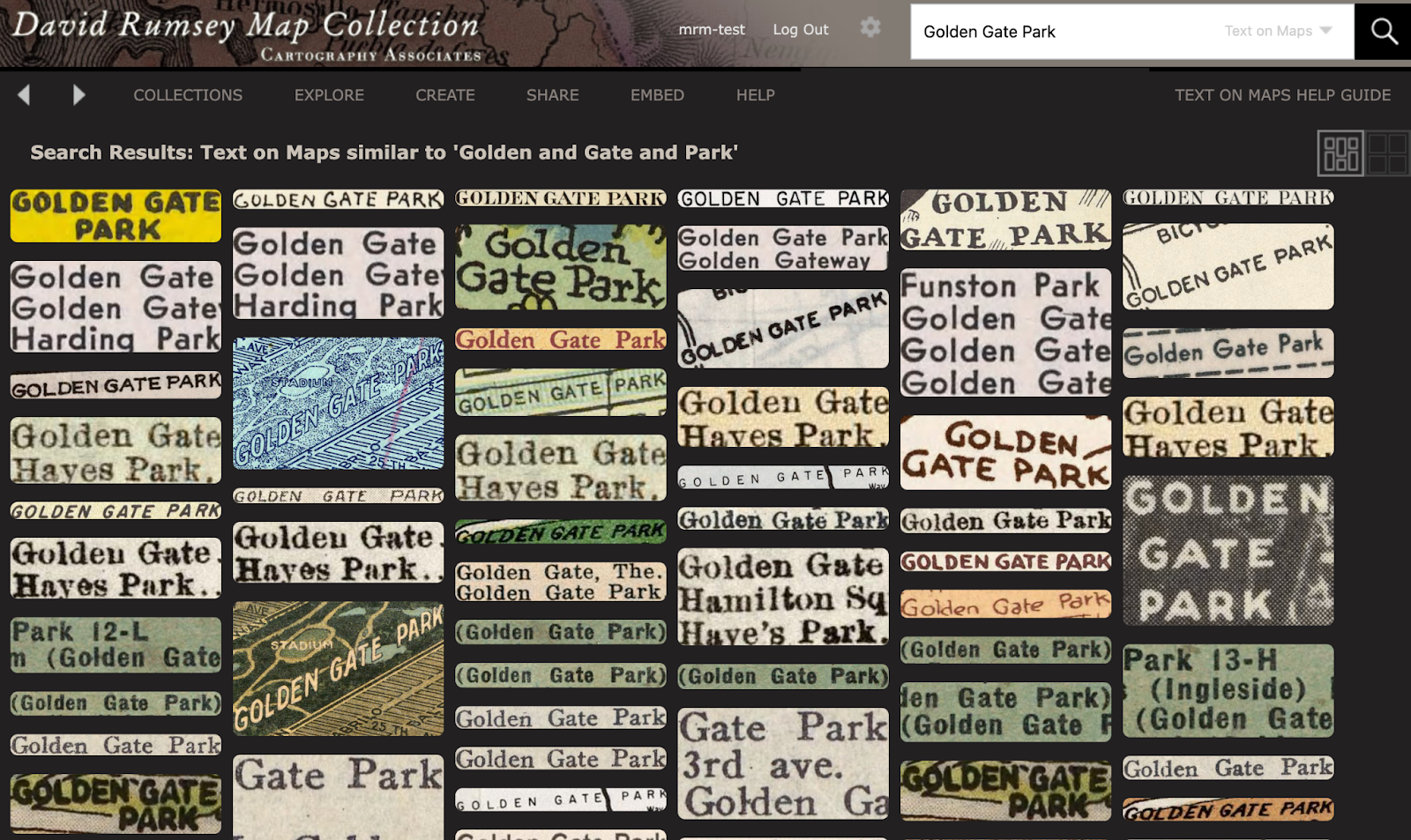
New text-on-maps search tool from the David Rumsey Map Library at Stanford: https://machines-reading-maps.github.io/rumsey/
#DavidRumsey #maps #cartography #historical #search #ocr
#davidrumsey #maps #cartography #historical #search #ocr

Annika Rockenberger (she/they) · @arockenberger
263 followers · 329 posts · Server fedihum.orgA long time ago, I wanted to do a #PhD project on text reuse & text production strategies of #EarlyModern #Author #GeorgGreflinger. I estimated ca. 30,000 pages of printed text. It was 2009/10, and large-scale digitisation of older books had just started. #OCR was a mess, & #HTR hadn't been a thing yet. Eventually, I abandoned the project, since manually transcribing 30,000 pp. & then doing computational analysis for text similarity & re-use was unfeasible.
Imagine I wanted to do that now!
#phd #earlymodern #author #georggreflinger #ocr #htr
Herbert Hertramph · @_DigitalWriter_
913 followers · 2352 posts · Server bildung.social
So, nun ein #OCR - Test mit #paperlessngx : PDF ohne Text mit 32 Grafiken.
1. Ja, schafft der #raspberrypi - benötigt aber 3 - 4 Minuten, Ergebnis ist ganz gut.
2. Gleiche PDF mit Quickscan, OCR ist nach ein paar Sekunden erledigt, dann Upload auf Raspberry Pi, nach ca. 1 Minute erledigt. OCR-Resultat auch gut.
Gut, muss ich nur selten machen, aber wollte ich mal testen.
#ocr #paperlessngx #raspberrypi

DrPetz · @DrPetz
84 followers · 971 posts · Server troet.cafeMission accomplished💪 #ToughMudder #OCR
Endlich den 10. Tough Mudder geschafft. Darauf hab ich 3 Jahre gewartet.
DrPetz · @DrPetz
84 followers · 972 posts · Server troet.cafeMorgen.
8 Uhr.
Tough Mudder Nr 10.
Erste Welle, beste Welle!
Wer nicht hüpft, der ist kein Mudder!
#ToughMudder #OCR

Tech news from Canada · @TechNews
973 followers · 26157 posts · Server mastodon.roitsystems.caMake Use Of: The 8 Best Apps to Identify Anything Using Your Phone's Camera https://www.makeuseof.com/tag/use-smartphone-identify-anything-camfind/ #Tech #MakeUseOf #TechNews #IT via @morganeogerbc #ImageRecognition #SmartphoneTips #AndroidApps #GoogleLens #Android #iOSApps #OCR
#Tech #MakeUseOf #technews #it #imagerecognition #SmartphoneTips #AndroidApps #googlelens #android #iOSApps #ocr
DrPetz · @DrPetz
84 followers · 963 posts · Server troet.cafe

ymaurer · @ymaurer
19 followers · 42 posts · Server mastodon.topSince #ChatGPT already does a decent job of postcorrecting #OCR errors, it would be interesting to see what it can achieve with fine-tuning now that it is available. #DigitizedNewspaper @cneudecker @PeterGilles https://platform.openai.com/docs/guides/fine-tuning
#chatgpt #ocr #digitizednewspaper
Phillip Ströbel · @phillipstroebel
66 followers · 27 posts · Server techhub.socialAnna Scius-Bertrand is presenting the #Bullinger writer adaptation challenge @ ICDAR2023. The #dataset is available here: https://tc11.cvc.uab.es/datasets/BullingerDB_1
The paper here: https://link.springer.com/chapter/10.1007/978-3-031-41676-7_23
#HTR #OCR #digitalhumanities
#bullinger #dataset #htr #ocr #digitalhumanities

David Bruchmann · @davidbruchmann
289 followers · 6139 posts · Server activism.openworlds.info
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@A_AnisimOFF
Btw. I used this #ocr online tool in combination with google translate:
https://www.ocr2edit.com/convert-to-txt
Copy and paste of the image is enough (without storing the image locally first), you just have to know, try or find out the right language.