
Thomas Sandmann · @thomas_sandmann
366 followers · 1147 posts · Server genomic.socialToday I learned how to use Pagès’s awesome {DelayedArray} @bioconductor package to handle gene expression data stored in parquet files. https://tomsing1.github.io/blog/posts/parquetArray/ This way, I can leverage familiar R tools and take
advantage of the language-agnostic parquet file format, querying very large gene expression datasets. Do you have experience with parquet files for biological data - please share the lessons you have learned! #til #parquet #rstats #duckdb #bioconductor
#til #parquet #RStats #duckdb #Bioconductor

· @emauviere
93 followers · 23 posts · Server mapstodon.space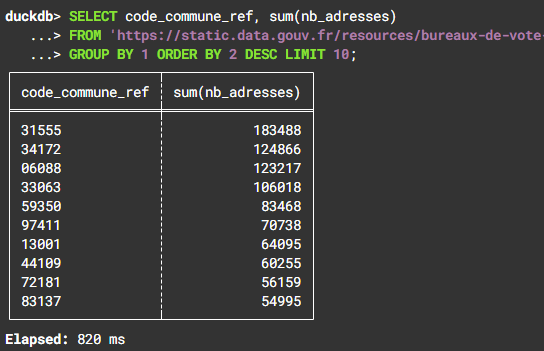
Le format #Parquet et le moteur SQL DuckDB changent vraiment la donne en requêtage #opendata.
L'Insee commence à diffuser en Parquet, ça tombe bien !
Avec https://shell.duckdb.org, requête en direct sur le fichier de 470 mo des adresses géocodées des électeurs par bureau de vote (https://www.data.gouv.fr/fr/datasets/bureaux-de-vote-et-adresses-de-leurs-electeurs/).
Toulouse en tête pour le nb d'adresses, résultat en 1 s, chapeau DuckDB, ça décoiffe 🙌
Thomas Sandmann · @thomas_sandmann
366 followers · 1147 posts · Server genomic.socialToday I learned how to store gene expression data in (multiple) parquet files, and query them as a single dataset from R with the {arrow}, {duckdb} or {sparklyr} packages. I am amazed by {duckdb}'s speed 🚀 - even on my laptop! Here's a blog post with what I learned: https://tomsing1.github.io/blog/posts/parquet/ #TIL #RStats #duckdb #parquet #spark #compbio #rnaseq
#til #RStats #duckdb #parquet #spark #compBio #rnaseq

Andrea Borruso · @aborruso
227 followers · 203 posts · Server mastodon.uno

Catalyst Cooperative · @catalystcoop
4 followers · 5 posts · Server mastodon.energyOur tooling is mostly #Python based. We primarily use @pandas_dev for data wrangling, and @dagster for orchestration.
We publish our smaller, more relational outputs as #SQLite databases and bigger skinny tables as Apache #Parquet datasets.
Historically we've focused on wrangling semi-structured data like spreadsheets, VisualFoxPro DBs, XBRL, and piles of CSVs into clean tables, but recently we've also started using OCR and ML to extract tables from regulatory PDFs in bulk (millions of pages).

Philippe Massicotte · @philmassicotte
64 followers · 90 posts · Server fosstodon.orgNew spatial products freely available from Meta, Microsoft, Amazon, and Tomtom, and all that available in cloud-native Parquet format!

Mark Wolfe · @wolfeidau
102 followers · 113 posts · Server awscommunity.socialBuilt out a small sample project which illustrates using apache arrow to write a parquet file from JSON Lines https://github.com/wolfeidau/arrow-gh-processor Using the GitHub archives as input has been interesting #golang #parquet

Konstantin Stadler :verified: · @kst
444 followers · 58 posts · Server qoto.orgNew #pymrio release (v0.5.1) with support for #Parquet file storage, GLORIA #mrio downloader (parser coming soon) and some bugfixes. First release with LGPL licence. Available on pypi pypi.org/project/pymrio/ and #condaforge :
https://anaconda.org/conda-forge/pymrio
The new #parquet based file format reduces the save/read time of the full #exiobase system from around 2 min to 20 sec on a typical SSD/laptop (with half the space req).
Will present parts of this at the #iioa conference #opensource special session, Tuesday 27.6 at 1430.
#MRIO #exiobase #pymrio #parquet #condaforge #iioa #opensource

François Michonneau · @fmic_
432 followers · 47 posts · Server hachyderm.io
A short blog post where I show how to use #DuckDB to connect to a remote #Parquet file hosted over HTTPS and work with it using #dplyr:
https://francoismichonneau.net/2023/06/duckdb-r-remote-data/
François Michonneau · @fmic_
484 followers · 74 posts · Server hachyderm.ioA short blog post where I show how to use #DuckDB to connect to a remote #Parquet file hosted over HTTPS and work with it using #dplyr:
https://francoismichonneau.net/2023/06/duckdb-r-remote-data/

GuruHiTech · @guruhitech
85 followers · 928 posts · Server mastodon.unoMIGO Ascender, il primo robot aspirapolvere in grado di salire le scale [VIDEO]
#Ascender #MigoRobotics #robot #scale #aspirapolvere #pavimento #pulizia #polvere #parquet
https://guruhitech.com/migo-ascender-il-primo-robot-aspirapolvere-in-grado-di-salire-le-scale/
#ascender #migorobotics #robot #scale #aspirapolvere #pavimento #pulizia #polvere #parquet

POUJOL-ROST Mathias ✅ · @poujolrost
284 followers · 10872 posts · Server mstdn.jp[ 🔄 ]
@Mediapart 🔗 https://mastodon.social/users/Mediapart/statuses/110445950829069600
-
Les « #écoutes » de Matignon: la #justice enquête sur des #soupçons d’ #irrégularités massives
Après le #signalement d’une #gendarme, le #parquet de Paris a ouvert une #enquête préliminaire, confiée à la #DGSI, à propos d’une #dérive au sein de #Matignon. Pas moins de 300 techniques de renseignement ont été pratiquées sans #validation du premier #ministre, comme l’impose pourtant la #loi.
#loi #ministre #validation #matignon #derive #dgsi #enquete #parquet #gendarme #signalement #irregularites #soupcons #justice #ecoutes
POUJOL-ROST Mathias ✅ · @poujolrost
306 followers · 11086 posts · Server mstdn.jp
{kind=link}
{kind=link}
{kind=link}
[ 🔄 ]
@Mediapart 🔗 https://mastodon.social/users/Mediapart/statuses/110445950829069600
-
Les « #écoutes » de Matignon: la #justice enquête sur des #soupçons d’ #irrégularités massives
Après le #signalement d’une #gendarme, le #parquet de Paris a ouvert une #enquête préliminaire, confiée à la #DGSI, à propos d’une #dérive au sein de #Matignon. Pas moins de 300 techniques de renseignement ont été pratiquées sans #validation du premier #ministre, comme l’impose pourtant la #loi.
#loi #ministre #validation #matignon #derive #dgsi #enquete #parquet #gendarme #signalement #irregularites #soupcons #justice #ecoutes

Dave Mackey · @davidshq
861 followers · 1400 posts · Server hachyderm.ioany #recommendations on best articles to read to understand #apache #parquet?
#recommendations #apache #parquet

Leon Brocard · @orangeacme
214 followers · 141 posts · Server fosstodon.orgRecently I've been building reports based upon HTTP Archive data. Rather than call BigQuery, I instead export the data I'm interested in into Parquet format and then query it locally on my laptop using DuckDB. Here's how I did it: https://discuss.httparchive.org/t/querying-the-http-archive-with-duckdb/2568
#httpArchive #parquet #DuckDB
GuruHiTech · @guruhitech
66 followers · 626 posts · Server mastodon.unoPavimenti al top con l'aspirapolvere 3 in 1 Neakasa PowerScrub II
#Neakasa #PowerScrub2 #aspirapolvere #pavimento #casa #pulizia #sconto #offerta #coupon #parquet
https://guruhitech.com/pavimenti-al-top-con-laspirapolvere-3-in-1-neakasa-powerscrub-ii/
#neakasa #powerscrub2 #aspirapolvere #pavimento #casa #pulizia #sconto #offerta #coupon #parquet

Thom O'Connor · @thomoco
184 followers · 977 posts · Server mas.toPart 2 of our blog series on using #Apache #Parquet with #ClickHouse
https://clickhouse.com/blog/apache-parquet-clickhouse-local-querying-writing-internals-row-groups

Tim Yocum · @tky
74 followers · 11 posts · Server hachyderm.ioProud of the #influxdb team today. We’ve launched InfluxDB 3.0 on InfluxDB Cloud. Built with #rust, leveraging #parquet, #datafusion, and #arrow, it sports unlimited cardinality, SQL, and so much more. This unlocks new capabilities for #observability, #iot, and other use cases.
#influxdb #rust #parquet #datafusion #Arrow #observability #iot

Nikola Ilic · @DataMozart
69 followers · 16 posts · Server dataplatform.socialNEW BLOG POST!
We evolve! So do the data...New flavors of data required new ways of storing it. In this article, we are going to dive deep under the hood of the #Apache #Parquet file format and explain the multiple benefits that it brings to the table.
Oh, there is a bonus part on #DeltaLake as well😉
https://data-mozart.com/parquet-file-format-everything-you-need-to-know/

Eugene Meidinger · @Sqlgene
254 followers · 569 posts · Server techhub.socialYour 5 weekly BI links - April 25th, 2023
https://mailchi.mp/sqlgene/your-5-weekly-bi-links-april-25th-2023
This week's links include Meagan Longoria, Chris Webb, David Eldersveld, Nikola Ilic, and Primal Branding.