
SLCW💥 · @slcw
393 followers · 4392 posts · Server newsie.social
"#Life begins at #conception" is a meaningless and intentionally-deceptive declaration that's meant to obfuscate the fact that #personhood begins at #birth. The #law explicitly does not provide for #legal personhood tied to ambiguous and differing opinions about when life begins. But this is the sort of #dishonesty that is the foundation of the forced-birth movement.
#life #conception #personhood #birth #law #legal #dishonesty #abortionrights

damian entwistle · @ukdamo
60 followers · 508 posts · Server mastodon.org.ukToday's poem:
Black Earth
- by Marianne Moore
https://www.tumblr.com/ukdamo/727163579113095168/black-earth?source=share
#poetry #MarianneMoore #self
#personhood #experience #scars #life #power #identity #individuality
#poetry #mariannemoore #self #personhood #experience #scars #life #power #identity #individuality

Paul Besso · @PBesso
7 followers · 166 posts · Server mastodon.ie
What is the measure of "a person:" Is it as simple as being human? Is it a more nuanced construct? Does personhood require self-awareness? Does it require free will? #personhood #Ethics

Queer Lit Cats · @QLC
357 followers · 12751 posts · Server mastodon.roitsystems.ca
Jezebel: Sex. Celebrity. Politics. With Teeth: Biden Floods Fox News with Abortion Rights Ads Before First Republican Debate https://jezebel.com/biden-floods-fox-news-with-abortion-rights-ads-before-f-1850767150 #Jezebel #abortionintheunitedstates #abortionrightsmovements #abortionrights #abortiondebate #socialissues #robflaherty #darkbrandon #personhood #joebiden #politics #jack #roe
#jezebel #abortionintheunitedstates #abortionrightsmovements #abortionrights #abortiondebate #socialissues #robflaherty #darkbrandon #personhood #joebiden #politics #jack #roe

PeachMcD · @PeachMcD
216 followers · 1553 posts · Server union.placeSeems to me like we need an #intersectional history of #reconstruction that highlights the ways Southern plantation #Oligarchs & Northern #Corporate interests f'd the #Constitution to soften the 'blow' of full #Black #personhood
#intersectional #reconstruction #oligarchs #corporate #constitution #black #personhood

DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net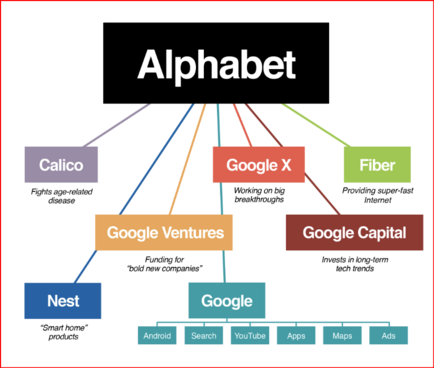
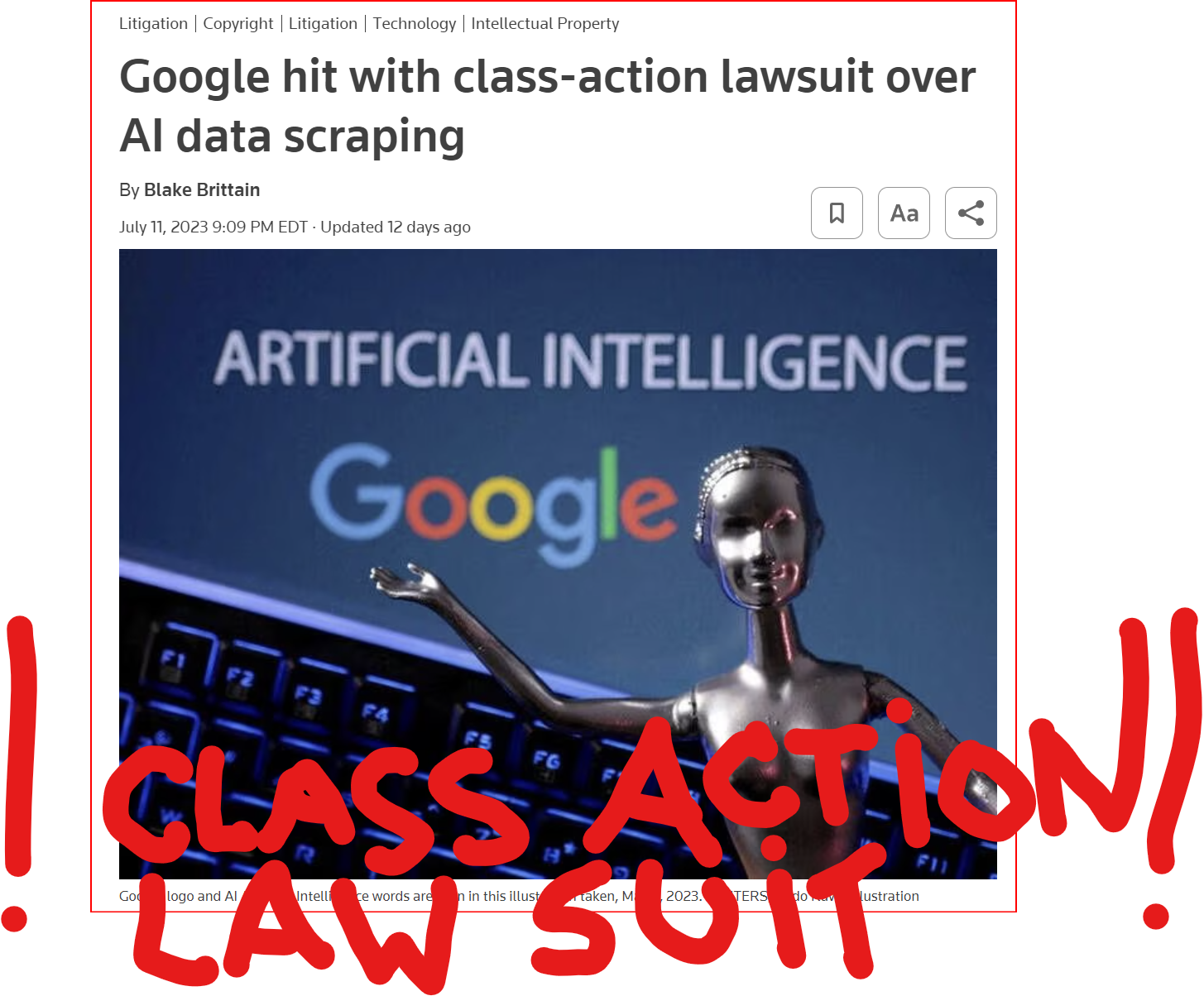
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
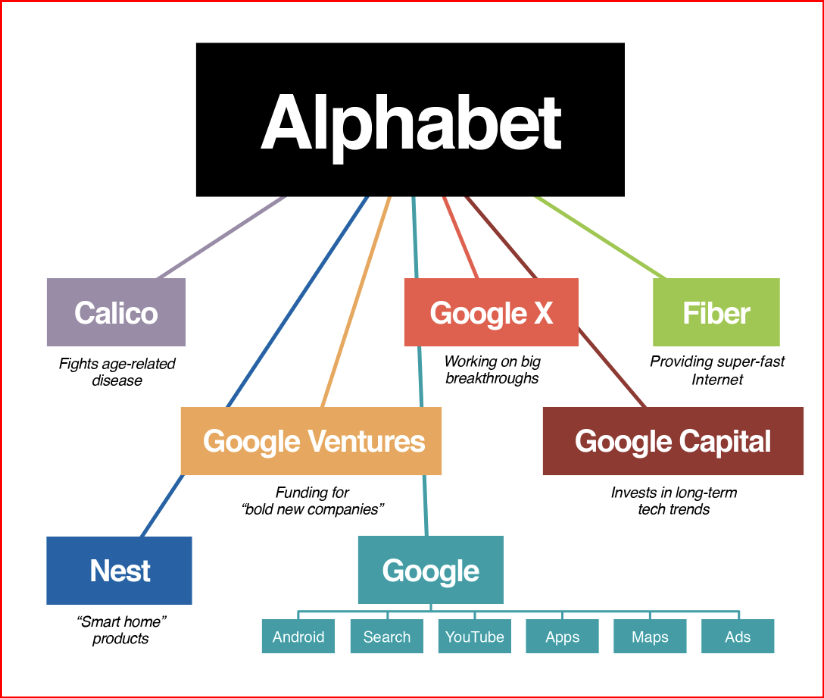
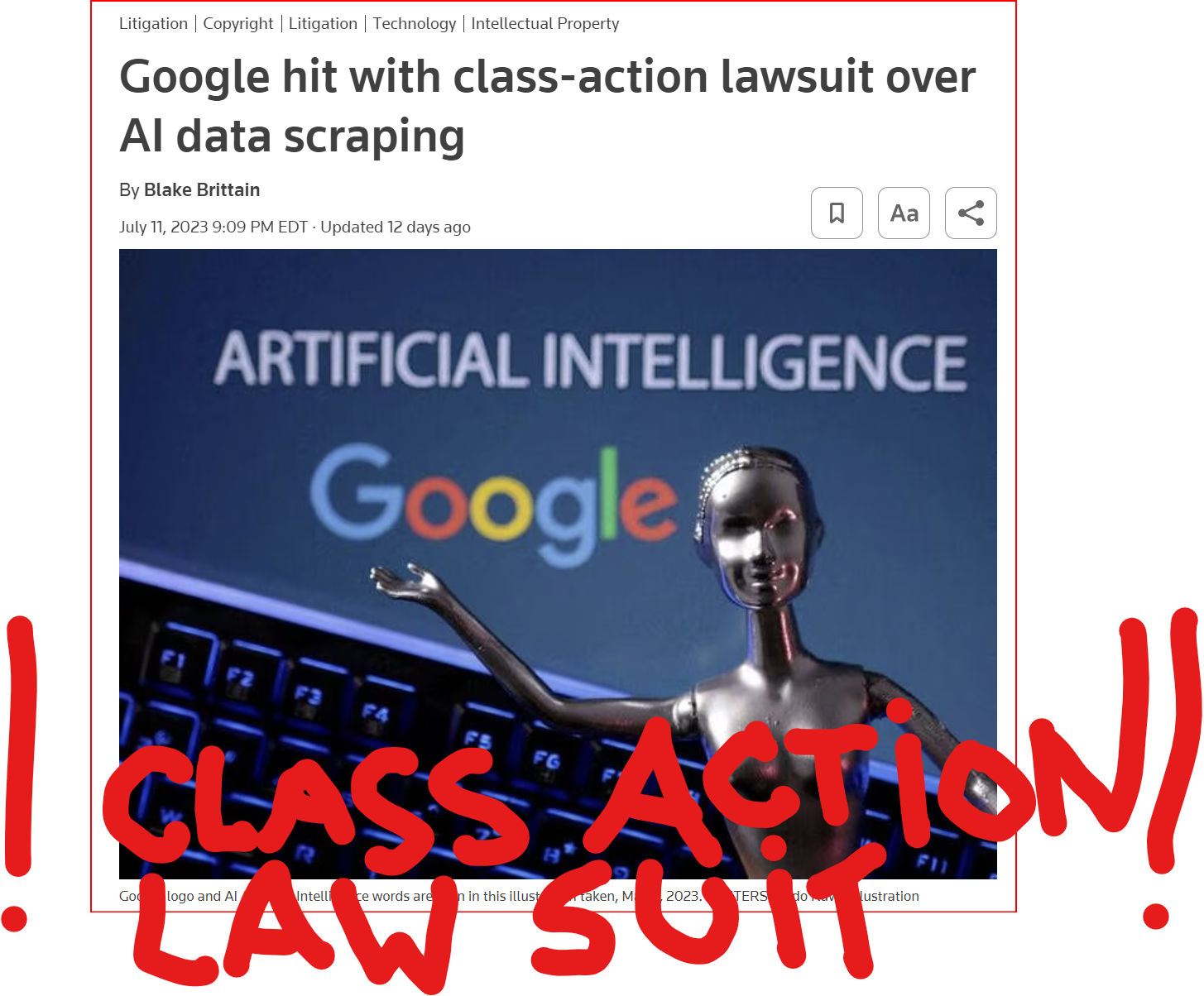
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
6 followers · 1876 posts · Server tastingtraffic.net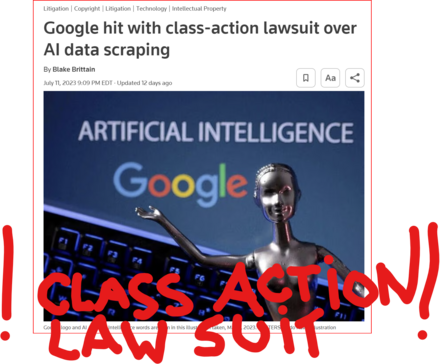
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
Queer Lit Cats · @QLC
325 followers · 12007 posts · Server mastodon.roitsystems.caJezebel: Sex. Celebrity. Politics. With Teeth: Anti-Abortion Activist Facing Trial Won't Be Allowed to Show the 5 Fetuses She Stole https://jezebel.com/anti-abortion-activist-facing-trial-wont-be-allowed-to-1850716105 #Jezebel #beginningofhumanpersonhood #antiabortionmovements #colleenkollarkotelly #judicialactivism #clarencethomas #kollarkotelly #hazeljenkins #heatheridoni #randallterry #laurenhandy #maryziegler #liveaction #personhood #abortion #roevwade #lawcrime #samalito #jezebel #davis
#jezebel #beginningofhumanpersonhood #antiabortionmovements #colleenkollarkotelly #judicialactivism #clarencethomas #kollarkotelly #hazeljenkins #heatheridoni #randallterry #laurenhandy #maryziegler #liveaction #personhood #abortion #roevwade #lawcrime #samalito #davis

nieebel · @aligyie
1395 followers · 3150 posts · Server digitalcourage.social@gael those are great news!
#us #usa #fairphone #android #foss #opensource #california #sfba #lowtech #SmallWeb #SmallTech #web #tech #privacy #humanRights #personhood #democracy #BigTech #VentureCapital #VC #surveillance #capitalism #humanRights #SiliconValley #google #GAFAM
#gafam #google #siliconvalley #capitalism #surveillance #vc #venturecapital #bigtech #democracy #personhood #humanrights #privacy #tech #web #smalltech #SmallWeb #lowtech #sfba #california #opensource #foss #android #fairphone #usa #us

Pauline von Hellermann · @pvonhellermannn
2583 followers · 9240 posts · Server mastodon.green@alx yes, it’s incredible/awful how much this is happening; that it’s all framed as a “bad holiday” experience. And, cruciallt, only UK tourists being granted #Personhood. No first hand accounts of what it’s been like for local people, hotel employees trying to save people’s lives, losing everything, etc. i’ve been really struck by this too. So much awful unconscious bias
DavidV.TV ® · @DavidVTV
5 followers · 1706 posts · Server tastingtraffic.net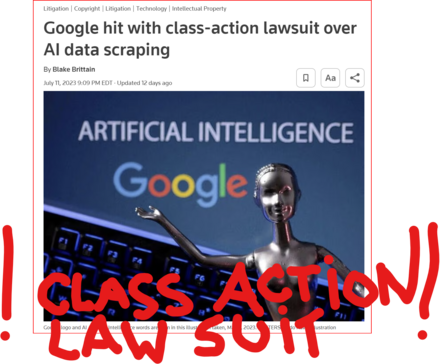
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1698 posts · Server tastingtraffic.net
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
DavidV.TV ® · @DavidVTV
5 followers · 1697 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS

JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.net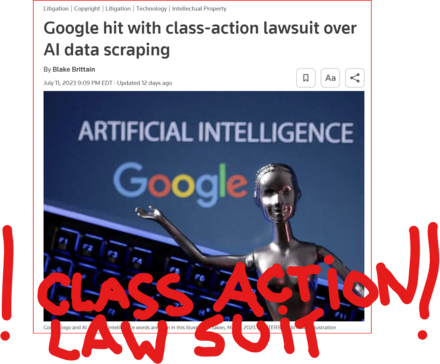
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2984 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2981 posts · Server tastingtraffic.net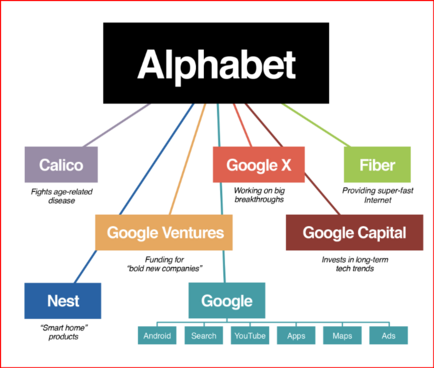
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.net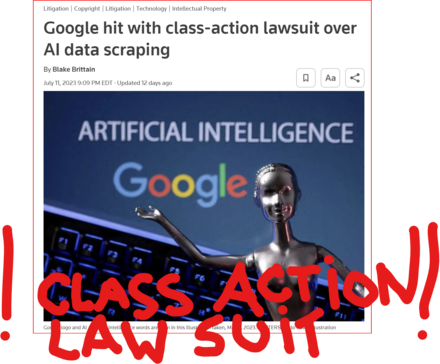
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
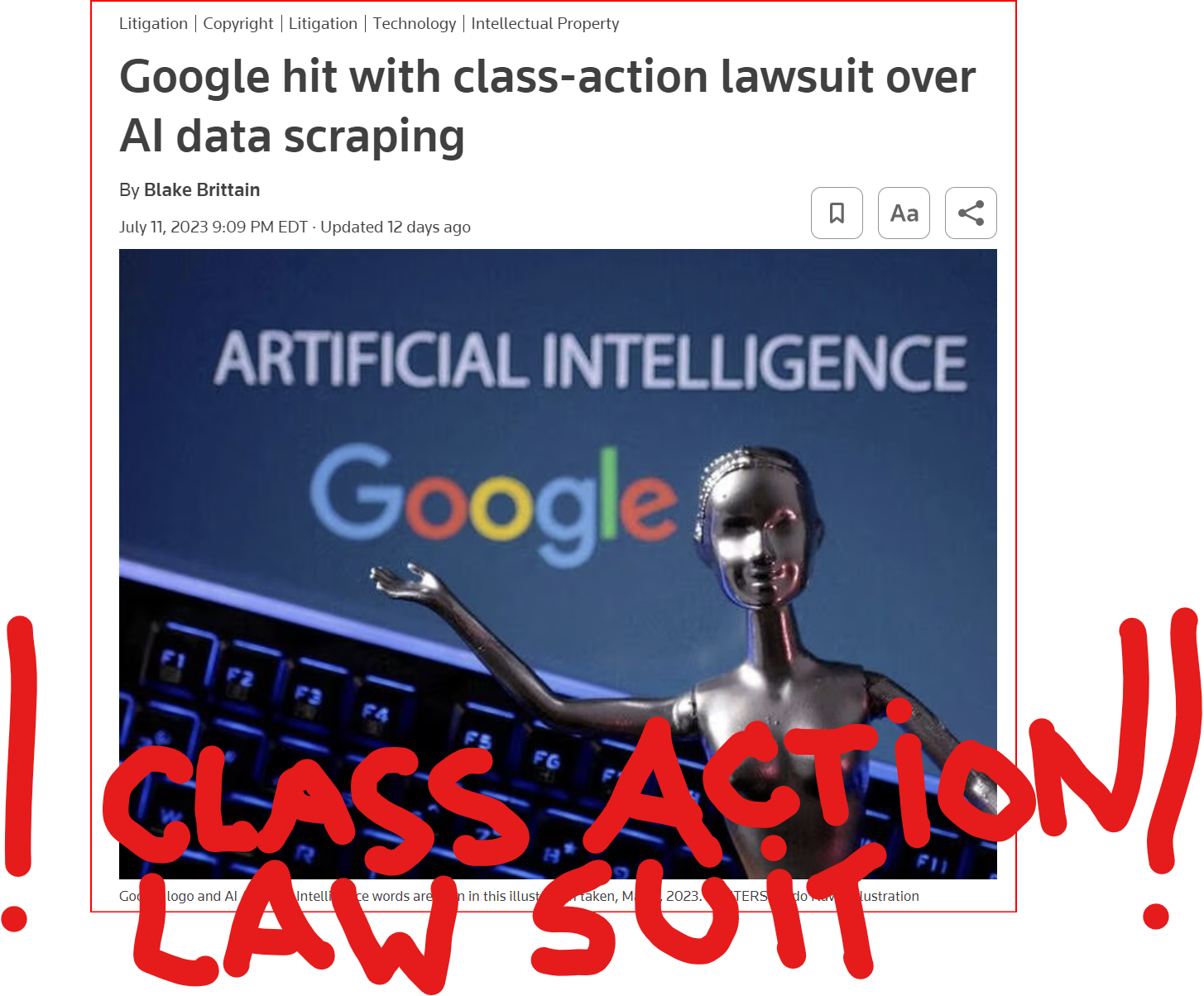
GOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE 3 SIMPLE meta tags BELOW; in order for any content OR DATA (all formats) to be copied/scraped (aka indexed) on the internet without exception.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS (code) SAY.. before they can COPY, SCRAPE OR INDEX ANY DATA OR CONTENT ONLINE-- AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index their content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLIC SEARCH Engine AND/OR ANY (#THIRD_PARTY_ENTITY) without #DO_FOLLOW permissions Granted by the Creator = #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned by third party entity from scraped content and/or data --but only if the author agrees and gives CONSENT.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SEARCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
JustBlameWayne Social® · @JustBlameWayne
13 followers · 2980 posts · Server tastingtraffic.netGOOD MORNING WORLD | INTERNATIONAL #TECH NEWS | #Google hit with #class_action_lawsuit over #AI #DATA_SCRAPING | #IP_THEFT!
DAVIDV #FOUNDER_OF_SEO #SOLUTION_HERE:
All data that is indexed across the world MUST HAVE THE 3 SIMPLE meta tags BELOW for any content (all formats) on the internet.
ALL SEARCH ENGINE SPIDERS (AKA SE BOTS) MUST FOLLOW WHAT THE META TAGS SAY.. before they can COPY OR INDEX ANY DATA OR CONTENT ONLINE AS FOLLOWS:
1. #DO_FOLLOW
<DO_FOLLOW></DO_FOLLOW> (google spiders are granted permission by author to index thier content into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
2. #NO_FOLLOW
<NO FOLLOW></NO FOLLOW>
(Google Spiders are NOT granted permission by author and CANNOT SCRAPE THAT CONTENT TO BE INDEXED into google databases WITH SERPS (SERCH ENGINE RANKING REPORTS)
CANNOT BE #INDEXED OR #RANKED IN ANY PUBLCI SEARCH Engine (#THIRD_PARTY_ENTITY) without #DO_FOLLOW #META_TAGS.
3. #DO_FOLLOW_WITH_SHARED_REVENUE %
<DO FOLLOW WITH SHARED REVENUE %>></DO FOLLOW WITH SHARED REVENUE %>
Shared revenue can be anywhere btw 50% to 90% on all revenues earned from scrape content and/or data --but only if the author agrees.
July 11 (Reuters) - #Alphabet's #Google #GOOGL_O was accused in a proposed class action lawsuit on Tuesday of #misusing #vast_amounts of #personal_information and #copyrighted material to #train its #artificial_intelligence systems.
The #complaint, filed in #San_Francisco federal court by #eight individuals seeking to represent #millions of #internet_users and #copyright_holders, said Google's #unauthorized_scraping of #data from websites #violated their #privacy and #property_rights. (AKA #IP_THEFT!)
"Google #does_not #OWN the internet, it does not #own our #creative works, it does not #own our #expressions of our #personhood, #pictures of our #families and #children, or anything else simply because we #share_it online," the plaintiffs' attorney #Ryan_Clarkson said in a statement.
Clarkson's firm filed a similar lawsuit in the #same court against #Microsoft_backed #OpenAI in June. It asked the court to allow the plaintiffs to remain #anonymous in both cases, citing #violent_threats reportedly received by individuals filing similar lawsuits.
The lawsuit filed on Tuesday claims that the company could owe at least $5 #billion.
#Google general #counsel #Halimah_DeLaine_Prado said the company has been "clear for years that we use data from public sources — like information published to the open web and public datasets – to train the AI models behind services like Google Translate, responsibly and in line with our AI Principles."
DAVIDv COMMENT: THAT IS A #LIE. DAVIDv WAS HERE BEFORE GOOGLE and IS AVAILABE AS #WITNESS AGAINST #BIG_TECH.
25 YEARS #REVERSE_SOFTWARE_ENGINEER. #EXPERT_BLACK_BOX_TESTER --CAN #CONFIRM WITH #PROOF --ALL THESE #ALLEGATIONS ARE INFACT TRUE.
"American law supports using public information to create new beneficial uses, and we look forward to refuting these #baseless_claims," DeLaine Prado said.
The case is one of several filed since last year against companies in the booming AI industry, including Meta Platforms, Microsoft and OpenAI, over their alleged misuse of personal data and copyrighted books, visual art and source code to train their systems.
JOBS FOR ALL WORLDWIDE!
CONNECT Today for EARLY #INVITE. TastingTraffic LAUNCHING SOON!
WELCOME TO THE FUTURE OF ADVERTISING! | If it Tastes Good, You Gotta LOVE IT! (Patent Pending).
Upon launch all will be notified.
* Software Architect (PhD) Supervisor -25 years 100K PMS hours
* EXPERT BLACK BOX TESTER
* Founder of SEO (Search Engine Optimization)
* Founder of RTB (Real Time Bidding)
* Founder of HFT (High Frequency Trading)
https://Withbrains.com/@Davidv ® (Decentralized SOCIAL Network | Signup for Early Invite);
https://TastingTraffic.net ® (#International_Tech_News);
http://JustBlameWayne.com ® (Just Blame Wayne & Post it);
http://Davidv.TV ® (Big Faith | Christianity RAW 101) are not affiliates of this provider or referenced images used. This is NOT an endorsement OR Sponsored (Paid) Promotion/Reshare.
#Tech #google #CLASS_ACTION_LAWSUIT #ai #DATA_SCRAPING #IP_Theft #FOUNDER_OF_SEO #SOLUTION_HERE #DO_FOLLOW #NO_FOLLOW #INDEXED #RANKED #THIRD_PARTY_ENTITY #META_TAGS #DO_FOLLOW_WITH_SHARED_REVENUE #Alphabet #GOOGL_O #misusing #vast_amounts #personal_information #copyrighted #train #artificial_intelligence #complaint #San_Francisco #eight #millions #internet_users #copyright_holders #unauthorized_scraping #data #VIOLATED #privacy #property_rights #does_not #own #creative #expressions #personhood #pictures #families #children #share_it #Ryan_Clarkson #SAME #Microsoft_backed #openai #anonymous #violent_threats #billion #counsel #Halimah_DeLaine_Prado #lie #WITNESS #big_tech #REVERSE_SOFTWARE_ENGINEER #EXPERT_BLACK_BOX_TESTER #confirm #PROOF #allegations #baseless_claims #INVITE #INTERNATIONAL_TECH_NEWS
damian entwistle · @ukdamo
58 followers · 423 posts · Server mastodon.org.ukToday's poem:
Wail
- by Johnson Cheu
https://www.tumblr.com/ukdamo/723710539032887296/wail?source=share
#love #life #poetry #community #identity #personhood #actualisation #JohnsonCheu #pupil #person #desire #hope #purpose
#love #life #poetry #community #identity #personhood #actualisation #johnsoncheu #pupil #person #desire #hope #purpose