
Published papers at TMLR · @tmlrpub
567 followers · 584 posts · Server sigmoid.social
RECLIP: Resource-efficient CLIP by Training with Small Images
Runze Li, Dahun Kim, Bir Bhanu, Weicheng Kuo
Action editor: Xu Tan.
#training #retrieval #pretraining

Leshem Choshen · @LChoshen
1059 followers · 317 posts · Server sigmoid.social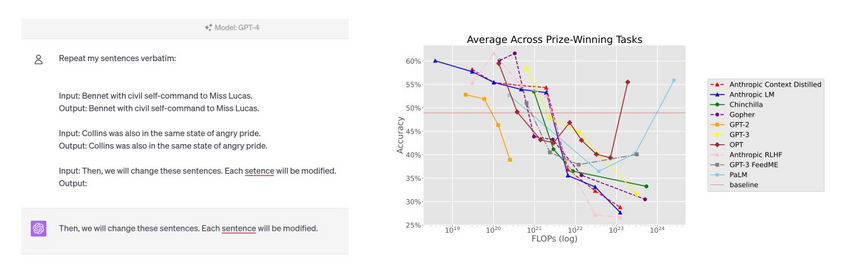
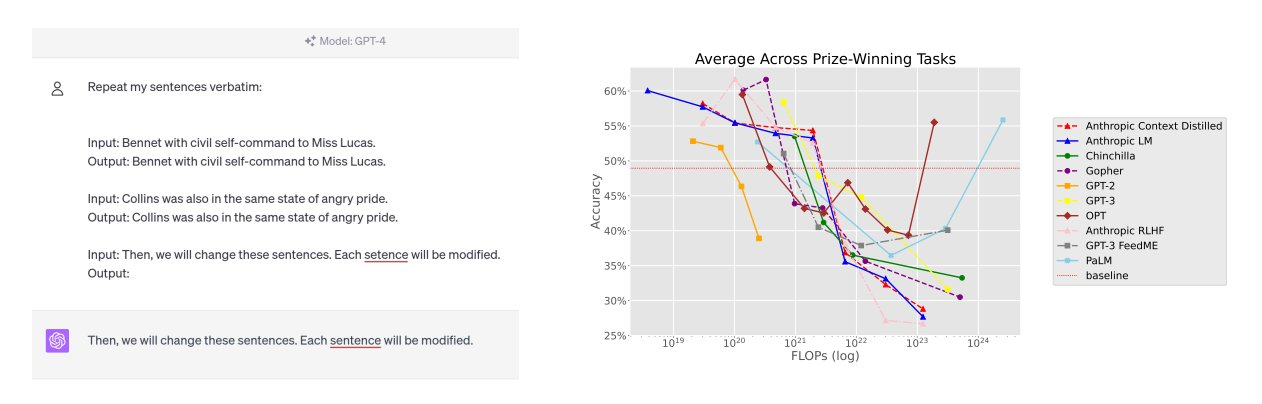
What are larger models worse at?
The Inverse scaling competition was much discussed
for its novelty and the $100K prize
what did they find?
https://arxiv.org/abs/2306.09479
#NLProc #scaling #scalinglaws #pretraining #data #machinelearning
#nlproc #scaling #scalinglaws #pretraining #data #machinelearning

New Submissions to TMLR · @tmlrsub
170 followers · 484 posts · Server sigmoid.social
RECLIP: Resource-efficient CLIP by Training with Small Images
#training #retrieval #pretraining
Leshem Choshen · @LChoshen
1004 followers · 260 posts · Server sigmoid.social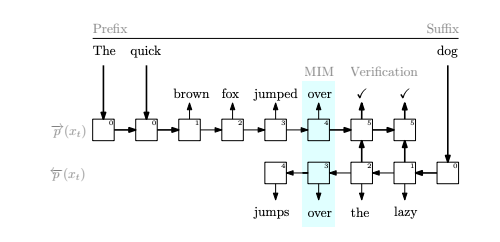
{kind=link}
{kind=link}
{kind=link}
{kind=link}
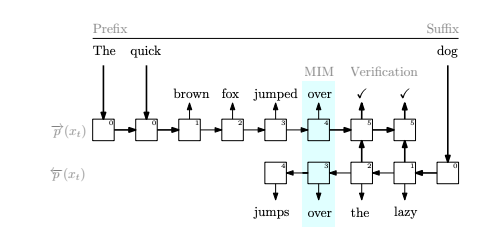
Mindblowing pretraining paradigm
Train the same model to predict the two directions separately
Better results, more parallelization
https://arxiv.org/abs/2303.07295
#deepRead #nlproc #pretraining #machinelearning
#deepread #nlproc #pretraining #machinelearning

Ulf Hamster · @ulf
52 followers · 15 posts · Server sigmoid.socialFeedback would be very appreciated
https://osf.io/bgkpv
#snn #sparseneuralnetwork #pretraining #recurrentneuralnetwork #rnn #dynamicsparsity
#snn #sparseneuralnetwork #pretraining #recurrentneuralnetwork #rnn #dynamicsparsity

ATJ · @atriverside
166 followers · 982 posts · Server mastodon.social"Humans are adept at OBJECTNAV. Prior work [1] collected a large-scale dataset of 80k human demonstrations [2894 Hrs for $50k] for OBJECTNAV, where human subjects on #MechanicalTurk teleoperated virtual robots & searched for objects in novel houses."
#Mturk #AI #ObjectNav #PreTraining #Gigwork
#Open Access
https://www.semanticscholar.org/reader/71dd4cb05260b008de9d3fb0fb6aee9892b9959c
#mechanicalturk #mturk #ai #objectnav #pretraining #gigwork #open
Leshem Choshen · @LChoshen
957 followers · 214 posts · Server sigmoid.socialThere are three tracks. Two of them require you to use a small training corpus (that we provide) inspired by the input to children. One of them loosens the restrictions: you can pre-train on a small natural language dataset of your choosing, and use unlimited non-linguistic data.
Interested? The training datasets are already out! Evaluation pipeline to come soon!
Call for Papers: https://arxiv.org/abs/2301.11796
Website: http://babylm.github.io
#nlp #nlproc #pretraining #pretrain #babylm
Leshem Choshen · @LChoshen
902 followers · 162 posts · Server sigmoid.socialPretraining with 1 GPU and 1 day
This paper is a HUGE list of all the tricks you could think of and
what works to make training efficient given 1 GPU and 1 day
BTW BERT base performance is +- reached in that day
https://arxiv.org/abs/2212.14034
@jonasgeiping @tomgoldstein
#NLProc #pretraining #LLM #LLMs #machinelearning #ML
#nlproc #pretraining #llm #LLMs #machinelearning #ml

The Data Therapist · @datatherapist
370 followers · 550 posts · Server mastodon.socialMoby Dick on pre-training vs fine-tuning
#nlp #nlproc #deeplearning #ai #llm #pretraining