
Tabular · @tabular
53 followers · 62 posts · Server data-folks.masto.hostPyIceberg: Python Development Setup
This video will walk you through the steps required to set up the Python development environment for PyIceberg. We will set up a local instance of Spark, Rest catalog, and MinIO for querying an actual table. This makes it easy to do interactive development and test everything end to end.
#iceberg #python #pyiceberg #tabular #minio #spark #datalake #datalakehouse #pyarrow
https://youtu.be/D0HJuB0uSio
#iceberg #python #pyiceberg #tabular #minio #spark #DataLake #datalakehouse #pyarrow
Tabular · @tabular
50 followers · 52 posts · Server data-folks.masto.hostFokko Driesprong has written a very interesting new blog on using the latest version of #PyIceberg with #PyArrow and DuckDB Labs to load data from an #Iceberg table into PyArrow or DuckDB with PyIceberg.
https://tabular.medium.com/pyiceberg-0-2-1-pyarrow-and-duckdb-79effbd1077f
#pyiceberg #pyarrow #iceberg #python #spark #minio
Tabular · @tabular
50 followers · 51 posts · Server data-folks.masto.hostWith #PyIceberg 0.2.1 now available, we thought a video that illustrates using it with #PyArrow and DuckDB Labs would be in order. Thank you Fokko Driesprong for the content.
#iceberg #apacheiceberg #duckdb #voltrondata #datalake #datalakehouse
#pyiceberg #pyarrow #iceberg #apacheiceberg #duckdb #voltrondata #DataLake #datalakehouse

sʌǝu ᴧɐɹʞǝʃ 🤘🇪🇪🤘 · @varkel
224 followers · 224 posts · Server est.social
Tabular · @tabular
44 followers · 29 posts · Server data-folks.masto.hostA hearty thank you to the PyIceberg community on the release of Apache PyIceberg release 0.2.0!
This release includes a few major features, such as
* Read support using PyArrow and DuckDB
* Support for AWS Glue
Please check the updated docs (https://py.iceberg.apache.org/) for the details.
This release can be downloaded from: https://pypi.org/project/pyiceberg/0.2.0/
And can be installed using: pip3 install pyiceberg==0.2.0
#iceberg #python #pyiceberg #duckdb #pyarrow

Taras Novak 🇺🇦 · @dataSamurai
64 followers · 86 posts · Server vis.social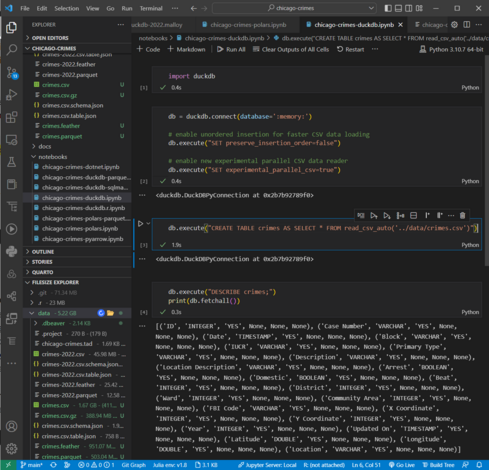
{kind=link}
Hey #dataNerds 🤓, good news:
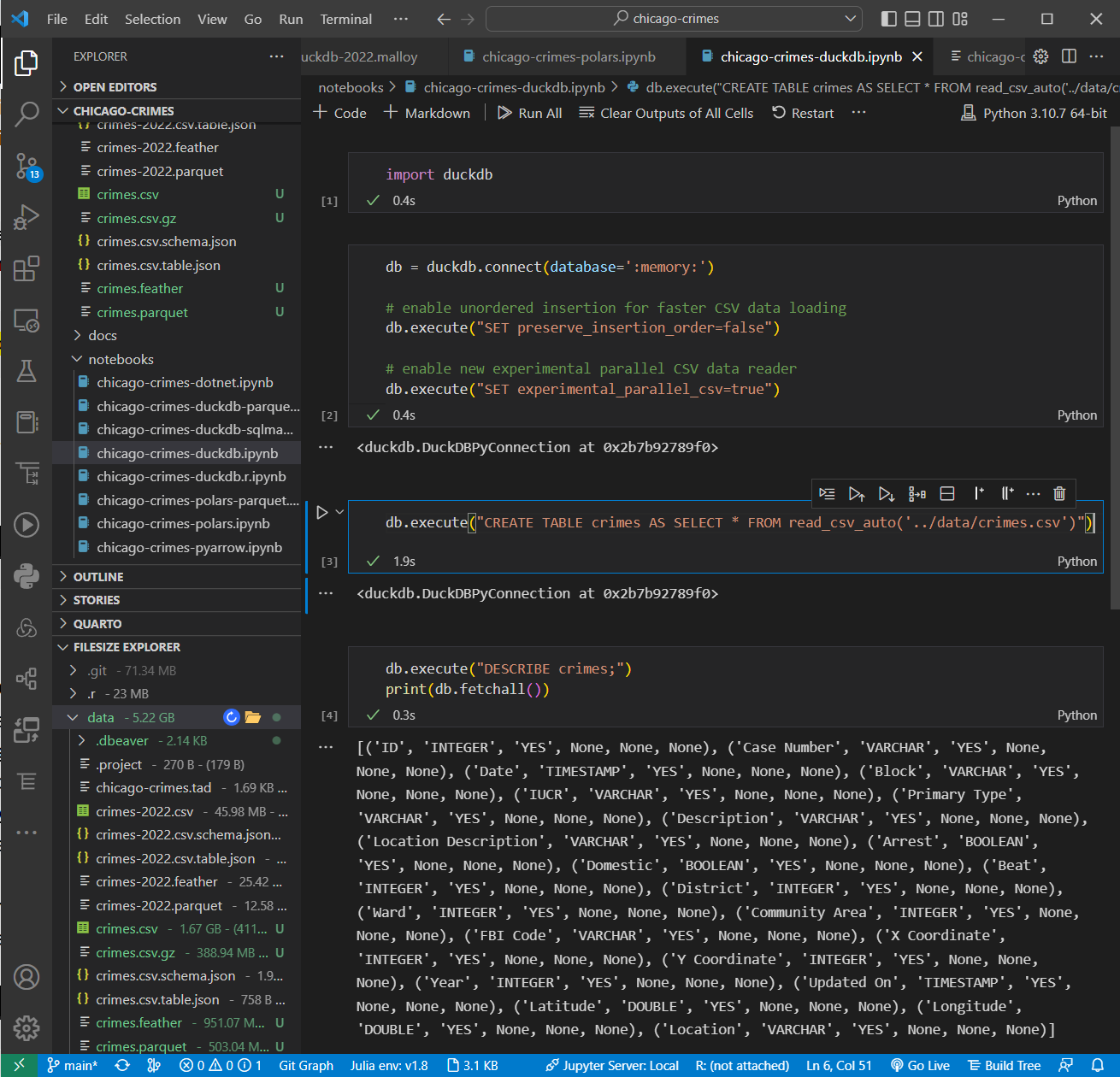
#DuckDB v0.6.0 brings reading #CSV data on par with #PyArrow & #Polars and loads 1.66 GB of #ChicagoCrimes data in 1.9s with 12 cores/24 threads when experimental parallel CSV reader & unordered insertion are enabled.
🧐 https://github.com/RandomFractals/chicago-crimes#with-duckdb
#dataTools 🔬 ...
#datatools #ChicagoCrimes #polars #pyarrow #csv #duckdb #datanerds

cmsadler 🏳️🌈📊🦽🥁🐈⬛ · @cmsadler
173 followers · 170 posts · Server mastodon.onlineToday I'm doing some #MachineLearning archeology, and once again dabbling in #PyArrow to read and convert parquet to #Pandas so that I can do some minimal data exploration and answer questions on how the models were trained. If you store data in parquet format, PyArrow is a great resource.
#pandas #pyarrow #machinelearning