
Benjamin Han · @BenjaminHan
475 followers · 1317 posts · Server sigmoid.social
Cade Metz’s NYTimes article on Doug Lenat, featuring quote from Ken Forbus and @garymarcus. The connection between the game Traveller and #Cyc is interesting and is new to me.
Douglas Lenat, Who Tried to Make Computers More Human, Dies at 72 https://www.nytimes.com/2023/09/04/technology/douglas-lenat-dead.html
#cyc #ai #GOFAI #reasoning #commonsense #knowledge
Benjamin Han · @BenjaminHan
472 followers · 1301 posts · Server sigmoid.socialIs #math just symbol pushing?
When Computers Write Proofs, What's the Point of Mathematicians? https://youtu.be/3l1RMiGeTfU?si=sQMFAK7tzkS4ODZp
#math #ai #reasoning #mathematics #proofs #generativeAI
Benjamin Han · @BenjaminHan
471 followers · 1284 posts · Server sigmoid.socialDog Lenat, founder of #Cyc, passed away earlier this week. From Professor Ken Forbus:
"People in AI often don't give the Cyc project the respect it deserves. Whether or not you agree with an approach, understanding what has happened in different lines of work is important. The Cyc project was the first demonstration that symbolic representations and reasoning could scale to capture significant portions of commonsense…”
https://www.linkedin.com/posts/forbus_ai-knowledgegraphs-krr-activity-7103445990954700800-qcd-
#cyc #ai #KnowledgeGraphs #reasoning #nlp #nlproc

gprimola$ :idle: · @giorgiolucas
49 followers · 672 posts · Server techhub.socialI want to share something with you.
My therapist once told me, in regards to my relationship with my father:
“Like it or not, you have a relationship with your father. Everybody has a relationship with A father, even if they don’t have or ever had a father. Having a father is part of everyone’s psyche, therefore you have a relationship with a or your father. The only thing you need to do is define this relationship the best way it works for you. It doesn’t have to be ideal, it just needs to not jeopardize your life.”
#relationships #relationship #father #dad #daddy #therapy #psychology #emotions #son #thoughts #thinking #reasoning
#relationships #relationship #father #dad #daddy #therapy #psychology #emotions #son #thoughts #thinking #reasoning

Answers in Reason · @AnswersInReason
31 followers · 186 posts · Server masto.nuWhat is the Rationality Debate? by Answers In Reasonhttps://www.youtube.com/watch?v=80U_aafts1g#rationality #godlessgranny #bias #highlight #highlights #fallacies #logic #reason #reasoning
#godlessgranny #bias #highlight #highlights #fallacies #logic #reason #reasoning
Benjamin Han · @BenjaminHan
449 followers · 1210 posts · Server sigmoid.social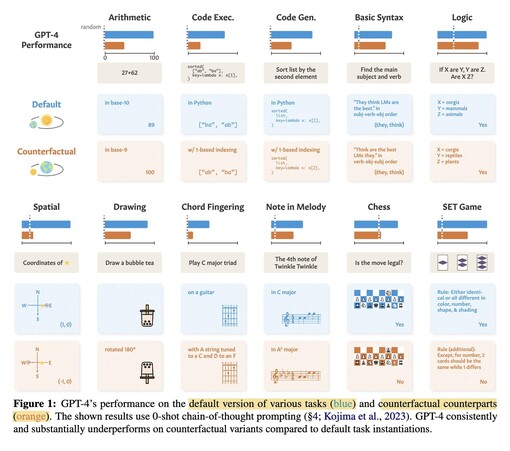
Large degradations observed from #LLMs when tasks are reframed into counterfactuals. Only basic syntax, logic and music chords are decent w/ counterfactuals.
(see also: https://lnkd.in/gje_WkR3 )
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. 2023. #Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through #Counterfactual Tasks. http://arxiv.org/abs/2307.02477
#LLMs #reasoning #counterfactual #paper #nlp #nlproc #generativeAI

José A. Alonso · @Jose_A_Alonso
844 followers · 1753 posts · Server mathstodon.xyz
Backward reasoning in large language models for verification. ~ Weisen Jiang et als. https://arxiv.org/abs/2308.07758 #LLMs #Reasoning

PirateLSAT · @PirateLSAT
1 followers · 14 posts · Server esq.socialAnd that, my friends, is my guide for the very first #steps when #starting to prepare for the #LSAT.
The next step is laying out the 3 sections, #logical #reasoning #reading #analytical #reasoning, and explaining how to approach each one.
Then we can drill down into the various types of questions, #games, #passages, etc.
There are so many ways to analyze and understand the #LSAT, it really is a #fascinating and challenging #exam!
Comments welcome!
#steps #starting #lsat #logical #reasoning #reading #analytical #games #passages #fascinating #exam #guide
PirateLSAT · @PirateLSAT
1 followers · 12 posts · Server esq.social#Starting
Isolate the types of questions that give you consistent trouble and build up special approaches to them.
There are a few types of #questions for each #section, we'll cover them here on #mastodon.
#Logical #reasoning in particular has many types, but we need *actionable* information. Defining is only the first step.
So, the types are grouped by the #processes they require. There are only a few #mental #processes required for the #LSAT, the challenge is to switch processes on cue :)
#starting #questions #section #mastodon #logical #reasoning #processes #mental #lsat
PirateLSAT · @PirateLSAT
1 followers · 4 posts · Server esq.socialThe best process for starting #LSAT is usually #logical #reasoning first, then the #reading or #games, according to which is harder. Don't put off the #harder section to the end or you will stress. It's ok to go with the easiest section #starting out, but that just pushes the #heavy #lifting back.
Some may try to study all #LSAT sections simultaneously, but that doesn't work for most #students. Going for the hardest section first is also dangerous, it will lead to a lot of #frustration.
#lsat #logical #reasoning #reading #games #harder #starting #Heavy #lifting #students #frustration
José A. Alonso · @Jose_A_Alonso
841 followers · 1726 posts · Server mathstodon.xyzGPT-4 can't reason. ~ Konstantine Arkoudas. https://www.preprints.org/manuscript/202308.0148/v2 #GPT4 #LLMs #AI #Reasoning
José A. Alonso · @Jose_A_Alonso
833 followers · 1702 posts · Server mathstodon.xyz
GPT-3 aces tests of reasoning by analogy (Undergrads get beaten on questions like those that helped get them into college). ~ John Timmer. https://arstechnica.com/science/2023/07/large-language-models-beat-undergrads-on-tests-of-reasoning-via-analogy/ #GPT #Reasoning

JBRoss · @jbross
21 followers · 500 posts · Server mstdn.party"There is giant untapped potential in disagreement, especially if the disagreement is between two or more thoughtful people." — Ray Dalio — — — #RayDalio #quote #quotes #potential #future #reasoning #earnest #thoughtful #commonality
#raydalio #quote #quotes #potential #future #reasoning #earnest #thoughtful #commonality

steve dustcircle ⍻ · @dustcircle
294 followers · 9481 posts · Server masto.ai6 Proofs for God's Existence???
https://www.youtube.com/watch?v=8HoNJVNbcS0
When we consider the most profound question of life, “Does #God exist?” we should follow the #evidence wherever it leads. In this video, #KyleButt presents six "evidences" proving God’s existence, from the complexity and order of our #Universe to the #morality, #freewill, and #reasoning in #humanity. And a former #Christian responds.
#god #evidence #kylebutt #universe #morality #freewill #reasoning #humanity #christian

Benjamin Han · @BenjaminHan
395 followers · 1067 posts · Server sigmoid.social10/end
[4] https://www.linkedin.com/posts/benjaminhan_reasoning-gpt-gpt4-activity-7060428182910373888-JnGQ
[5] Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, and Bernhard Schölkopf. 2023. Can Large Language Models Infer Causation from Correlation? http://arxiv.org/abs/2306.05836
#Paper #NLP #NLProc #CodeGeneration #Causation #CausalReasoning #reasoning #research
#paper #nlp #nlproc #codegeneration #causation #causalreasoning #reasoning #research
Benjamin Han · @BenjaminHan
395 followers · 1066 posts · Server sigmoid.social9/
[2] Antonio Valerio Miceli-Barone, Fazl Barez, Ioannis Konstas, and Shay B. Cohen. 2023. The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python. http://arxiv.org/abs/2305.15507
[3] Emre Kıcıman, Robert Ness, Amit Sharma, and Chenhao Tan. 2023. Causal Reasoning and Large Language Models: Opening a New Frontier for Causality. http://arxiv.org/abs/2305.00050
#Paper #NLP #NLProc #CodeGeneration #Causation #CausalReasoning #reasoning #research
#paper #nlp #nlproc #codegeneration #causation #causalreasoning #reasoning #research
Benjamin Han · @BenjaminHan
395 followers · 1065 posts · Server sigmoid.social8/
[1] Xiaojuan Tang, Zilong Zheng, Jiaqi Li, Fanxu Meng, Song-Chun Zhu, Yitao Liang, and Muhan Zhang. 2023. Large Language Models are In-Context Semantic Reasoners rather than Symbolic Reasoners. http://arxiv.org/abs/2305.14825
#Paper #NLP #NLProc #CodeGeneration #Causation #CausalReasoning #reasoning #research
#paper #nlp #nlproc #codegeneration #causation #causalreasoning #reasoning #research
Benjamin Han · @BenjaminHan
395 followers · 1065 posts · Server sigmoid.social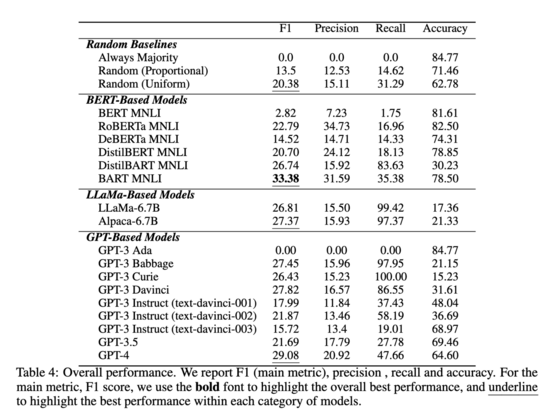
7/
The results? Both #GPT4 and #Alpaca perform worse than BART fine-tuned with MNLI, and not much better than the uniform random baseline (screenshot).
#Paper #NLP #NLProc #CodeGeneration #Causation #CausalReasoning #reasoning #research
#gpt4 #alpaca #paper #nlp #nlproc #codegeneration #causation #causalreasoning #reasoning #research
Benjamin Han · @BenjaminHan
395 followers · 1062 posts · Server sigmoid.social5/
This shows the semantic priors learned from these function names have totally dominated, and the models don’t really understand what they are doing.
How about LLMs on #causalReasoning? There have been reports of extremely impressive performance of #GPT 3.5 and 4, but these models also lack consistency in performance and even possibly have cheated by memorizing the tests [3], as discussed in a previous post [4].
#Paper #NLP #NLProc #Causation #CausalReasoning #reasoning #research
#causalreasoning #gpt #paper #nlp #nlproc #causation #reasoning #research
Benjamin Han · @BenjaminHan
395 followers · 1061 posts · Server sigmoid.social
{kind=link}
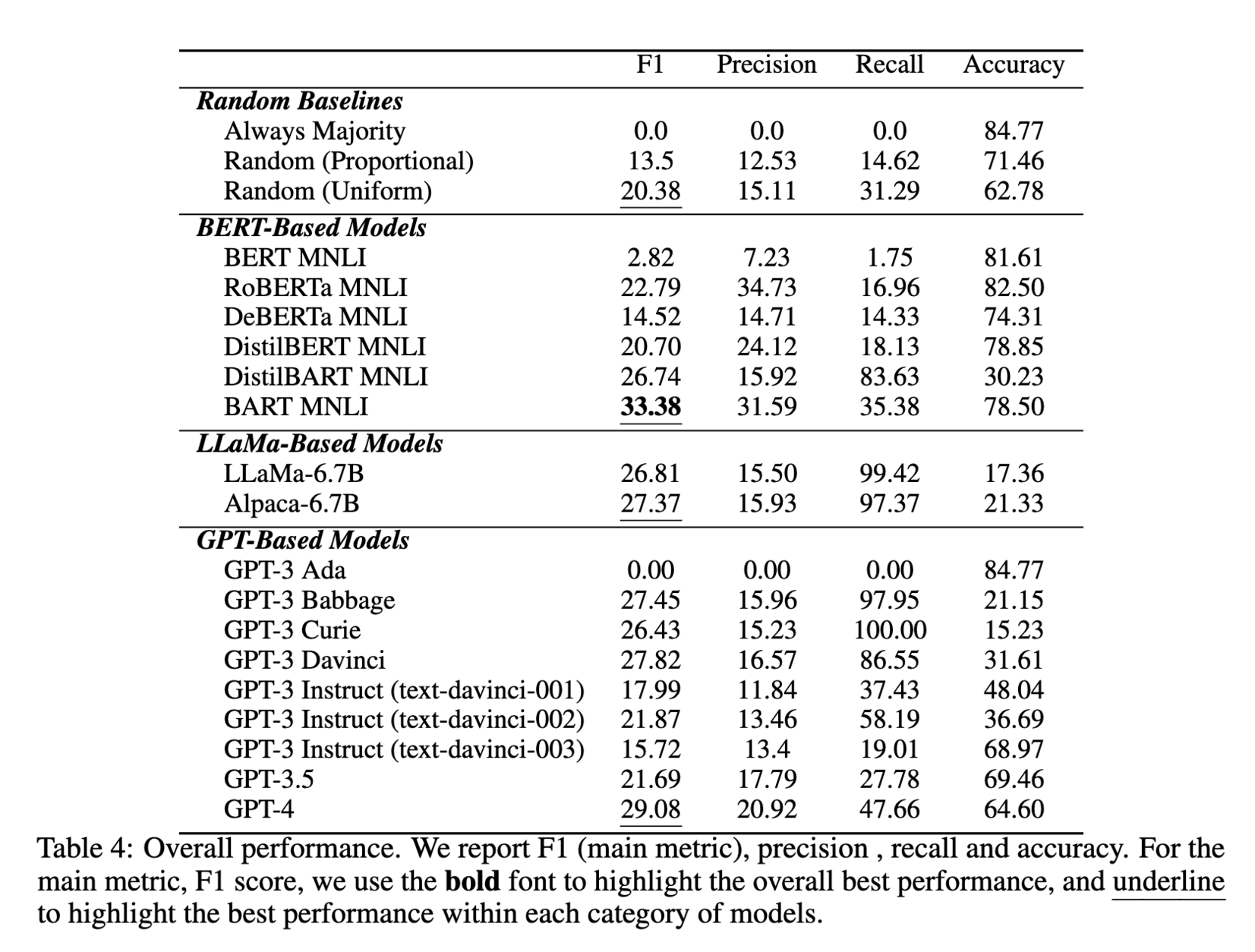{kind=link}
{kind=link}
4/
The same tendency is borne out by another paper focusing on testing code-generating LLMs when function names are *swapped* in the input [2] (screenshot 1). They not only found almost all models failed completely, but also most of them exhibit an “inverse scaling” effect: the larger a model is, the worse it gets (screenshot 2).
#Paper #NLP #NLProc #CodeGeneration #Causation #CausalReasoning #reasoning #research
#paper #nlp #nlproc #codegeneration #causation #causalreasoning #reasoning #research