
Shawn Hymel · @shawnhymel
661 followers · 190 posts · Server masto.ai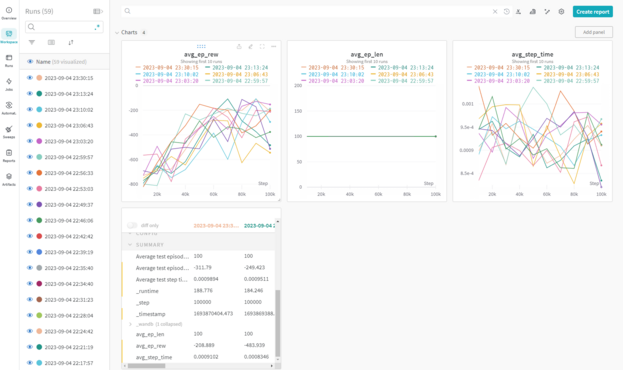
Hyperparameter optimization can be tricky, especially for #ReinforcementLearning. There are a few frameworks out there that can help. I learned the basics of Meta's Ax and logged hyperparameter metrics to Weights & Biases.
If you're curious, here is the code: https://github.com/ShawnHymel/reinforcement-learning-demos/blob/main/rl-demo-pendulum-ax-hpo.ipynb
#reinforcementlearning #machinelearning

hlfshell · @hlfshell
73 followers · 318 posts · Server hachyderm.io
Impressive results w/ RLHF in drone racing w/ deep RL agents - their agent can beat several of the world's champions in drone racing.
#reinforcementlearning #deeplearning #ai #robotics

Armin Hanisch · @Linkshaender
1157 followers · 5048 posts · Server bildung.social
Ich admit that I‘m really impressed. Champion-level drone racing AI using a pretrained model with only a single cam and inertial sensor on-board.
As video is nice, but not information, here’s the link to the paper: https://www.nature.com/articles/s41586-023-06419-4
(edit: typo)
#drone #DroneRacing #AI #ReinforcementLearning #UniZurich
#drone #droneracing #ai #reinforcementlearning #unizurich

Marek Gluza · @Marekgluza
81 followers · 211 posts · Server mathstodon.xyz
My name is Marek Gluza, I'm city hopping from Warsaw to Barcelona and can I visit you on 15th June?
That was the sentence.
Keep in mind that I had my own funding but this sentence worked much better than:
Hey there hello hi, I'm Marek and I have my own travel funding from my postdoxtoral fellowship that I sign with the hashtag #PPF and I'm searching for somebody to visit in the week after the 13th June would you maybe be interested to talk like sometime in the morning, not too late, and I'll align my #train itinerary?
What people don't want:
- read
- be annoyed by a possibly annoying weirdo for longer than 1h
- needing to cover travel costs
The first sentence does all 3 #desiderata by saying hi I'm city hopping. The rest is reassurance for the other two points because the length is within comfort zone:
-If you risk putting pressure by proposing a fixed date you gain reassuring that you will hop in and out.
- And if you're busy hopping in and out clearly you have money for it already.
Yeah sure I'll meet you, come over that day and my secretary will pass you the info how to find my office, cheers!
The experience with this sentence is related to how you search for flats in #Berlin. You send an introduction and improve it by #reinforcementLearning until you start receiving answers.
(2/more): still some thoughts about improving the travel flow and some other thoughts probably coming!
#altText to the somewhat unrelated picture available in #ALT and got overtly extensive because I'm practicing #observationSkills
#observationskills #alt #alttext #reinforcementlearning #berlin #Desiderata #train #ppf

Analyse Asia · @analyseasia
12 followers · 176 posts · Server mas.toGod Moves in Go are low & rare probabilistic game-changing positions that the AI cannot predict
Main Site: https://www.analyse.asia/the-future-of-generative-ai-in-southeast-asia-with-ong-peng-tsin/
Youtube Full Video: https://youtu.be/PzjCXj0rZnI
Newsletter Signup: https://www.analyse.asia/#/portal/signup
#alphafold #alphago #machinelearning #deepmind #ai #generativeai #artificialintelligence #reinforcementlearning #gochess #godmove
#godmove #gochess #reinforcementlearning #artificialintelligence #generativeai #ai #deepmind #machinelearning #alphago #alphafold

Aaron · @hosford42
845 followers · 7819 posts · Server techhub.socialI'm working on an algorithm to automatically identify latent coordinate systems, for the purpose of mapping state spaces in autonomous agents without a priori knowledge of the structure of the environment. Does anybody know of existing literature on this problem?
#machinelearning #reinforcementlearning #slam
hlfshell · @hlfshell
67 followers · 249 posts · Server hachyderm.ioSomeone reminded me of this article today, in response to my PPO project.
Which, you know, probably is rude, but still, it's a good article and I think it's still applicable.
...but I also think that we can't ignore that #reinforcementlearning has brought us instruct based LLM's like ChatGPT
hlfshell · @hlfshell
67 followers · 247 posts · Server hachyderm.ioI finally finished my writeup on utilizing PPO to control a robotic arm to attempt to solve a pick and place problem.
https://hlfshell.ai/posts/ppo-pick-and-place/
In the post I discuss my successes, failures, how everything works, and how I debugged the problem.
It's my first attempt at an in depth tech blogpost.
#robotics #rl #reinforcementlearning #ai

Chris J. Karr · @chris
132 followers · 1423 posts · Server omgwars.com* New Chrome extension for an exciting research project that I'll likely be sharing news stories about roughly in a year or so.
* Progress on the new reusable reinforcement learning system I'm writing that can be plugged into a bunch of my own projects and is based on Vowpal Wabbit.
(Continued...)
#chromeextensions #reinforcementlearning #vowpalwabbit

Brandon Rohrer · @brohrer
1255 followers · 1201 posts · Server recsys.socialIt's the widely anticipated sequel to
Chapter 1on human directed #ReinforcementLearning: https://tyr.fyi/1pdf
Chapter 2 on keeping time in Python: https://tyr.fyi/2pdf
Chapter 3 on working with multiple processes in Python: https://tyr.fyi/3pdf
Chapter 4 on real-time animation with Matplotlib: https://tyr.fyi/4pdf
Shawn Hymel · @shawnhymel
620 followers · 180 posts · Server masto.ai
New video! 📺 I've been studying #ReinforcementLearning over the past year, and this is the culmination of that knowledge. I dive into some theory and a demo with Farama Foundation Gymnasium and DLR Stable Baselines3.
👇👇👇
https://youtu.be/3av8vozEczU #MachineLearning #AI #python
#reinforcementlearning #machinelearning #ai #python
· @maxpool
79 followers · 49 posts · Server mathstodon.xyzProject Pigeon by B.F. Skinner in the early 1940s.
By using trained pigeons and hydraulic guidance, Skinner and his team developed a method to create the first smart-bomb that could be guided to its target with great accuracy.
https://www3.uca.edu/iqzoo/Exhibits/project_pigeon.htm
#weapons #biology #cognition #psycology #reinforcementLearning
#reinforcementlearning #psycology #cognition #biology #weapons

Dimitri Lozeve · @dlzv
178 followers · 156 posts · Server mathstodon.xyzData efficiency for #ReinforcementLearning
Xiuyuan Lu, Benjamin Van Roy, Vikranth Dwaracherla, Morteza Ibrahimi, Ian Osband and Zheng Wen (2023), "Reinforcement Learning, Bit by Bit", Foundations and Trends® in Machine Learning: Vol. 16: No. 6, pp 733-865. http://dx.doi.org/10.1561/2200000097

Michal Špondr · @michal
307 followers · 1580 posts · Server spondr.cz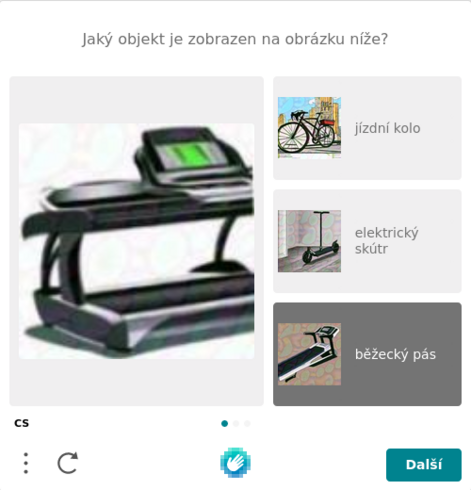
Tento typ Captchy jsem viděl snad poprvé. Takhle se učí umělá inteligence.
#reinforcementlearning

Anker Kafory · @anker
40 followers · 119 posts · Server me.dm🌟 Unlocking AI's Potential: Large language models (LLMs) are the key to advancing artificial general intelligence. How can we align LLMs with humans effectively? Reinforcement Learning with Human Feedback (RLHF) using PPO-max plays a vital role. Let's explore the possibilities! #ArtificialIntelligence #ReinforcementLearning #LanguageModels 🍃 More info: https://go.digitalengineer.io/KJ
#artificialintelligence #reinforcementlearning #languagemodels

David Meyer · @dmm
222 followers · 579 posts · Server mathstodon.xyz
Policy gradient methods in reinforcement learning are very cool and are used in a wide variety of machine learning applications including robotics, game playing, autonomous vehicles and many others, including incremental training of Large Language Models (LLMs).
A few of my notes on policy gradients are here: https://davidmeyer.github.io/ml/policy_gradient_methods_for_robotics.pdf. The LaTeX source is here: https://www.overleaf.com/read/kbgxbmhmrksb.
As always questions/comments/corrections/* greatly appreciated.
#machinelearning #Reinforcementlearning #policygradients #largelanguagemodelsa #TeXLaTeX
#texlatex #largelanguagemodelsa #policygradients #reinforcementlearning #machinelearning
Anker Kafory · @anker
13 followers · 109 posts · Server me.dm🤖💥 Bigger, Better, Faster (BBF) from Google Deepmind masters 26 Atari games in just 2 hours! 🚀🎮💪 It achieves human-like learning efficiency by directly learning from game rewards, saving computational power. BBF performs on par with systems trained on 500x more data. Impressive! 🎯 #AI #ReinforcementLearning #AtariGames 🌐 Src: https://go.digitalengineer.io/CS
#ai #reinforcementlearning #atarigames
David Meyer · @dmm
218 followers · 510 posts · Server mathstodon.xyz
Why is the Law of Large Numbers important when estimating likelihood ratio policy gradients?
Because it allows us to compute an unbiased estimate of an expectation as a sum, see the attached image.
Some of my notes on likelihood ratio policy gradients are here: http://www.1-4-5.net/~dmm/ml/lln_policy_gradient.pdf.
As always, questions/comments/corrections/* greatly appreciated.
#math #machinelearning #policygradients #reinforcementlearning #lawoflargenumbers
#LawOfLargeNumbers #reinforcementlearning #policygradients #machinelearning #math

asmaloney (Andy) 🌎 · @asmaloney
20 followers · 255 posts · Server fosstodon.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
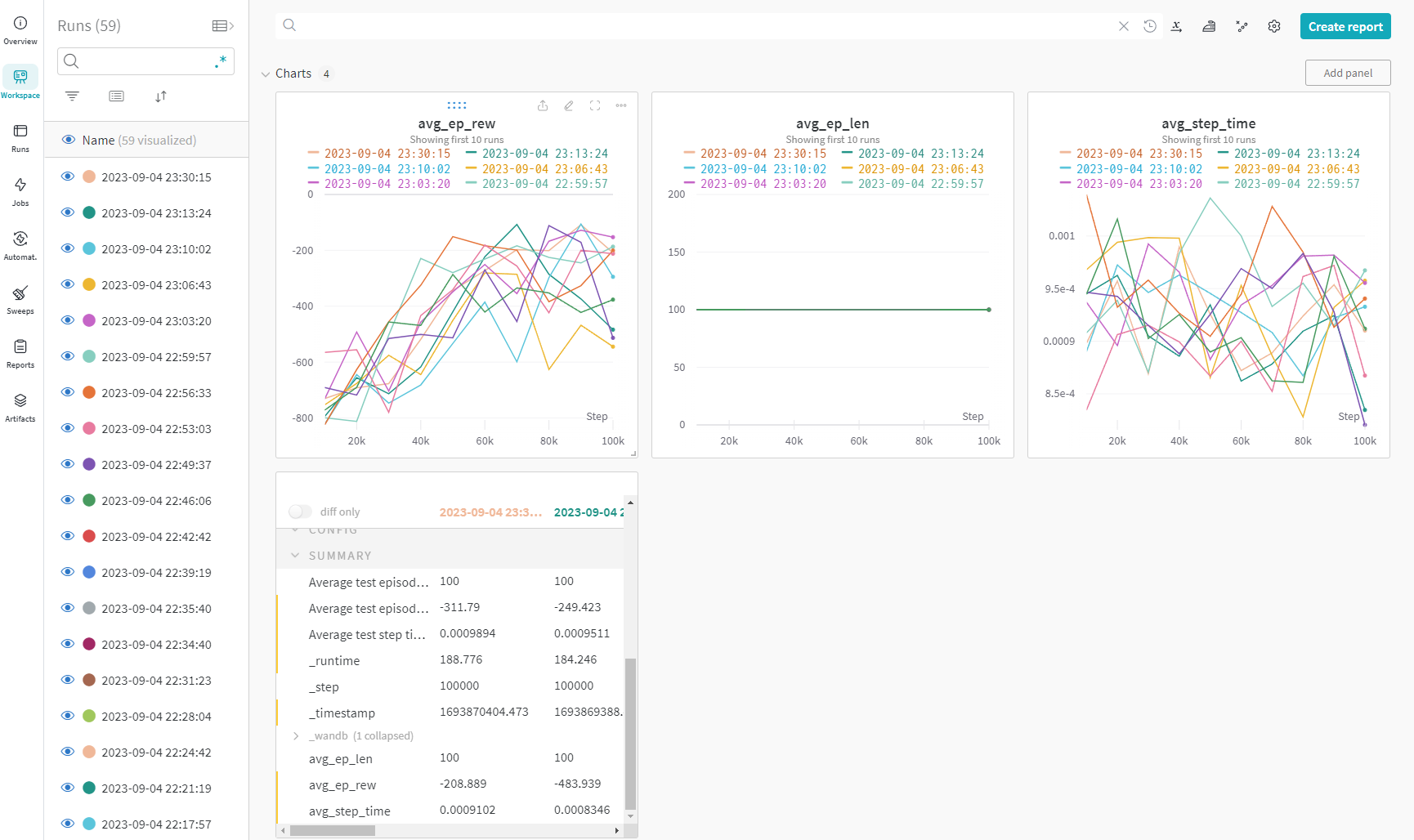
Finally some interesting & useful AI news!
"We reverse engineered the low-level assembly sorting algorithms discovered by AlphaDev for sort 3, sort 4 and sort 5 to C++ and discovered that our sort implementations led to improvements of up to 70% for sequences of a length of five and roughly 1.7% for sequences exceeding 250,000 elements."
https://www.nature.com/articles/s41586-023-06004-9
#NotChatGPT #AI #sorting #algorithm #cpp #LLVM #ReinforcementLearning
#notchatgpt #ai #sorting #algorithm #cpp #llvm #reinforcementlearning

Jürgen · @Jigsaw_You
142 followers · 2699 posts · Server mastodon.nlImpressive engineering and useful application of reinforcement learning.
#reinforcementlearning #machinelearning