
Elias Dabbas :verified: · @elias
57 followers · 98 posts · Server seocommunity.social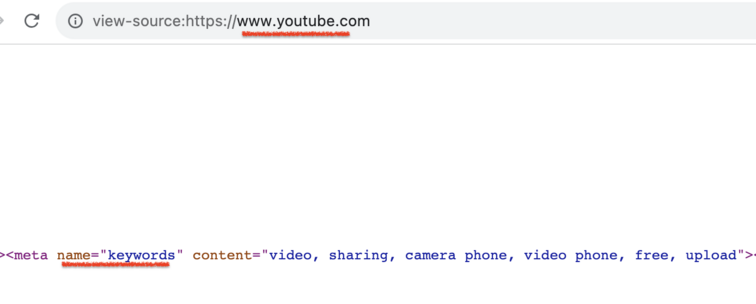
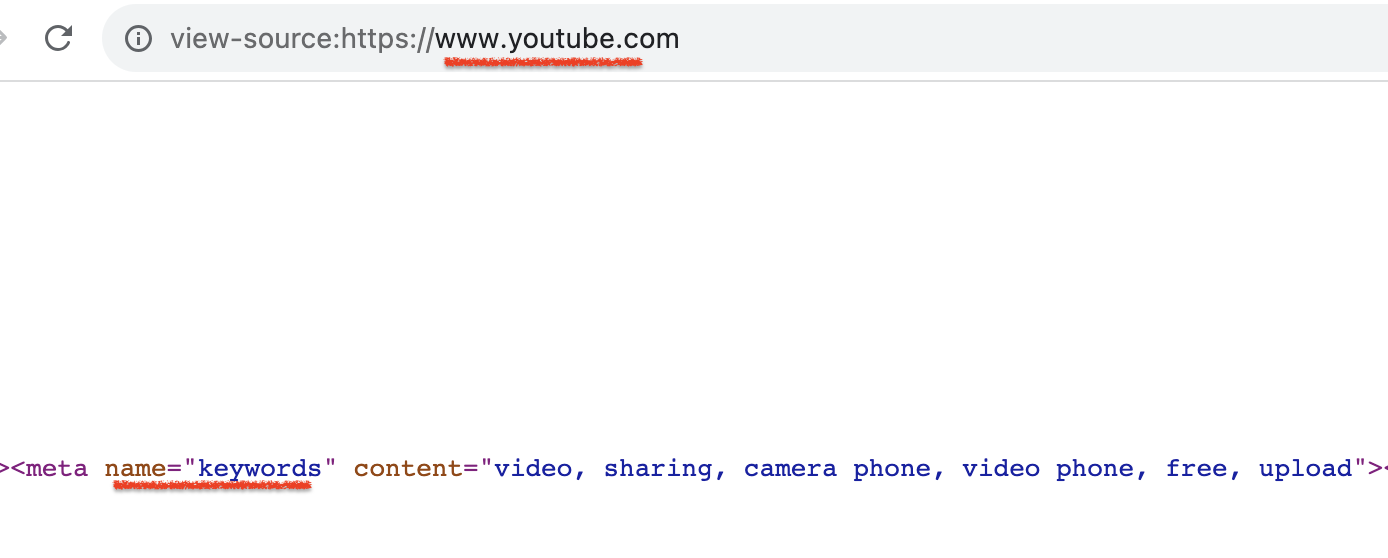
Get all meta tags from a page
🔵 Use to explore which meta tags exist on a certain URL
🔵 Get all tags, all attributes, and all their values
🔵 Discover some great "best practices" as I did in one of the screenshots ;)
🔵 Instructions, code, and a few example outputs can be found in the link
#seo #datascience #python #scrapy

Laboratório Hacker de Campinas · @lhc
128 followers · 91 posts · Server mastodon.com.brAs inscrições GRATUITAS para o tutorial "Raspando Dados da Internet com Python" com @rennerocha na manhã do sábado 01 de julho já estão abertas!
Mais informações em: https://www.eventbrite.com.br/e/tutorial-raspando-dados-da-internet-com-python-tickets-652188231557
#scrapy #python #webscraping #hackerspaces

Rami Krispin :unverified: · @ramikrispin
889 followers · 406 posts · Server mstdn.social
Web scraping with Scrapy course 🚀🚀🚀
A new course by freeCodeCamp for web scrapping with Python and scrapy by Joe Kearney. The course is for beginners level.
Resources 📚
➡️ Course: https://www.youtube.com/watch?v=mBoX_JCKZTE&t=31s&ab_channel=freeCodeCamp.org
➡️ Course website: https://thepythonscrapyplaybook.com/freecodecamp-beginner-course/
➡️ Scrapy: https://docs.scrapy.org/en/latest/

Dave Mackey · @davidshq
802 followers · 1237 posts · Server hachyderm.ioWhat are your favorite / the best #WebCrawlers for broad / #WebScale #crawling?
I've built a list but am looking for anything I missed: https://github.com/davidshq/awesome-search-engines/blob/main/WebCrawlers.md
Main options I've found include #Apache #Nutch, #StormCrawler, #Scrapy, #Norconex, #PulsarR, #Heritrix, and #sparkler
#WebCrawlers #webscale #crawling #apache #nutch #stormcrawler #scrapy #norconex #pulsarr #heritrix #sparkler #question #search #searchengines

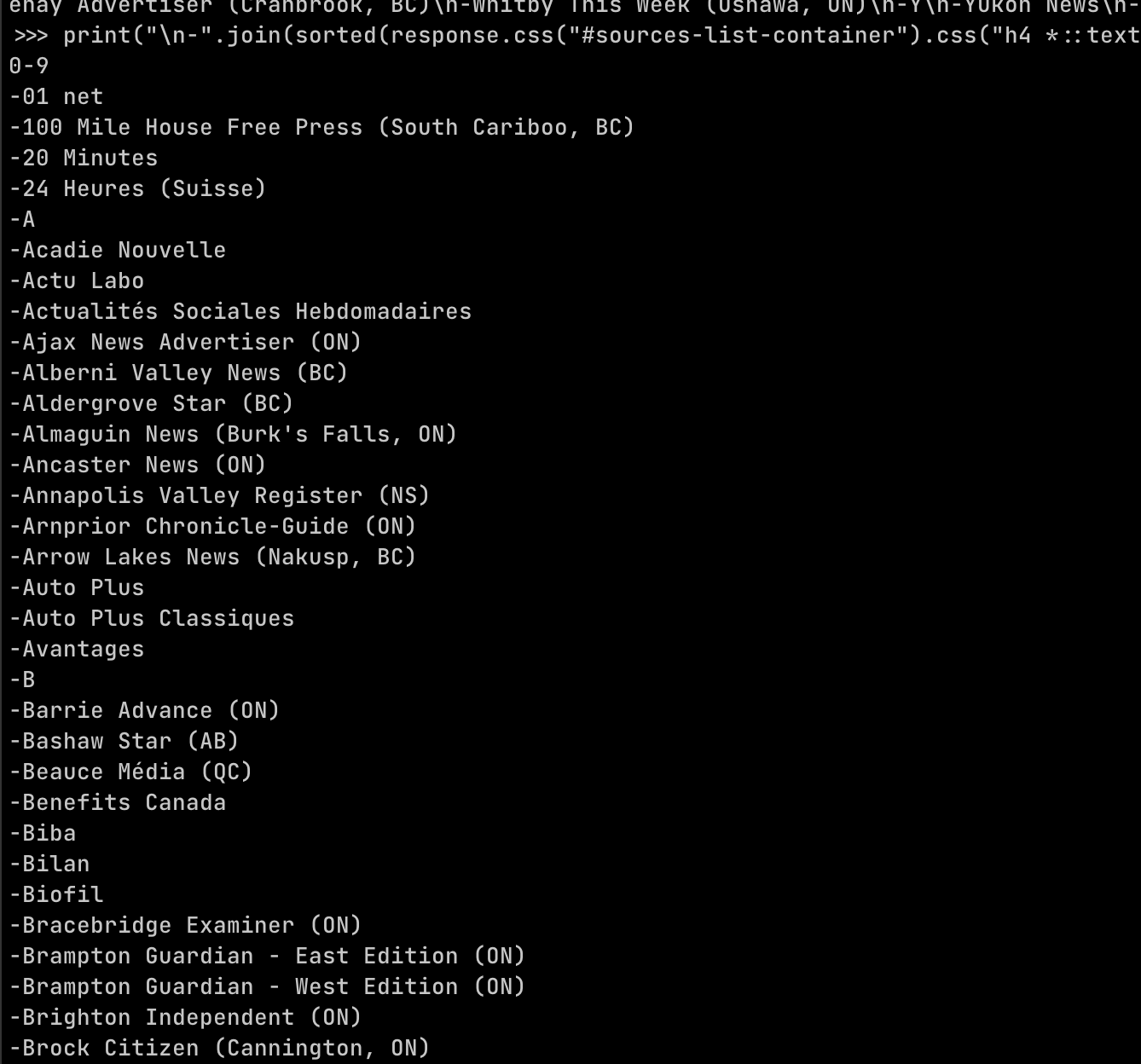
octplane · @octplane
97 followers · 240 posts · Server mastodon.xyz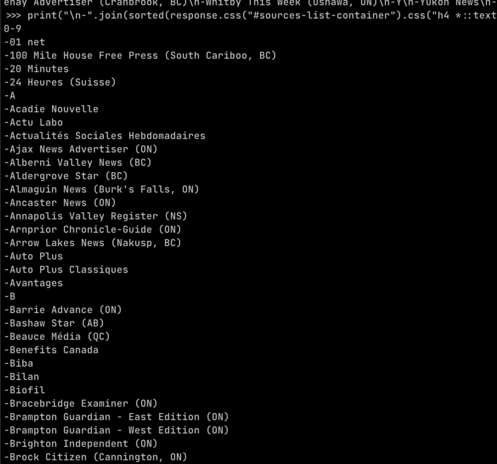

Frederik Elwert · @felwert
754 followers · 1068 posts · Server mstdn.social@grvsmth In this case from #OpenRefine. But other scrapers like #scrapy can also output CSV. Is this practice so uncommon? I always thought it a practical way to keep metadata and text together. But maybe I've been doing things wrong the whole time. 😅

Matt Layman · @mblayman
89 followers · 348 posts · Server mastodon.social🐍 How can you scrape data from webpages using #Python? In this talk, you'll see how this is possible with #scrapy. https://www.youtube.com/watch?v=tdA1cl6LiCw

Tahsin J · @knyghtmare
2 followers · 19 posts · Server mas.toHey, all!
Here's some #Python must-knows if you're wanting to get into #datascience
Mathematics:
#Numpy, #Scipy, #statmodels
Data Mining:
#BeautifulSoup or #Scrapy
EDA & DataVisualisation:
#Pandas, #MatPlotLib, #Plotly, #Seaborn
Machine Learning & Deep Learning:
#TensorFlow, #ScikitLearn, #Keras, #Pytorch, PyCaret
#pytorch #keras #scikitlearn #tensorflow #seaborn #plotly #matplotlib #pandas #scrapy #beautifulsoup #statmodels #scipy #numpy #datascience #Python
Tahsin J · @knyghtmare
3 followers · 43 posts · Server mas.toHey, all!
Here's some #Python must-knows if you're wanting to get into #datascience
Mathematics:
#Numpy, #Scipy, #statmodels
Data Mining:
#BeautifulSoup or #Scrapy
EDA & DataVisualisation:
#Pandas, #MatPlotLib, #Plotly, #Seaborn
Machine Learning & Deep Learning:
#TensorFlow, #ScikitLearn, #Keras, #Pytorch, PyCaret
#pytorch #keras #scikitlearn #tensorflow #seaborn #plotly #matplotlib #pandas #scrapy #beautifulsoup #statmodels #scipy #numpy #datascience #Python

Ryan He · @ryanhe
40 followers · 165 posts · Server moe.pastwind.top
Ryan He · @ryanhe
40 followers · 164 posts · Server moe.pastwind.top
Oriol Piera :python: · @cortsenc
111 followers · 239 posts · Server mastodont.catDesprés de dinar, treballem amb #Scrapy amb https://github.com/JimenaEB presidenta de #PythonES #PyBCNDay #PythonBarcelona #PyLadiesBarcelona
#scrapy #pythones #pybcnday #pythonbarcelona #pyladiesbarcelona

DeaDSouL :fedora: :fediverse: · @DeaDSouL
103 followers · 290 posts · Server fosstodon.org
{kind=link}
{kind=link}
{kind=link}
#Python #Frameworks #Libraries #numpy #tensorflow #theano #pandas #pytorch #keras #matplotlib #scipy #seaborn #django #flask #bottle #cherrypy #pyramid #web2py #turboGears #cubic #dash #falcon #pyunit #behave #splinter #robot #pytest #opencv #mahotas #pgmagick #simpletk $scikit #arcade #pyglet #pyopengl #pygame #panda3d #lxml #requests #selenium #scrapy #code #developing #programming #coding
#python #frameworks #libraries #numpy #tensorflow #Theano #pandas #pytorch #keras #matplotlib #scipy #seaborn #django #flask #bottle #cherrypy #pyramid #web2py #turbogears #cubic #dash #falcon #pyunit #behave #splinter #robot #pytest #opencv #mahotas #pgmagick #simpletk #arcade #pyglet #pyopengl #pygame #panda3d #lxml #requests #selenium #scrapy #code #developing #programming #coding

Jose Marichal · @JoseMarichal
284 followers · 68 posts · Server mastodon.social
Riverfount :verified_alt: · @Riverfount
18 followers · 173 posts · Server mstdn.social
Phel · @phel
139 followers · 2433 posts · Server toot.cafe@ajroach42 You could give #scrapy a shot - pretty easy to configure and scrape the relevant data. Maybe you need to feed the login cookie manually, but otherwise it could work.
TBH, this is probably already overengineering...

Ell · @cincodenada
49 followers · 2233 posts · Server cybre.spaceHaving a real grumpy old man moment here trying to write a bog-standard crawler to log in to a website and download a couple dozen links.
I made the mistake of trying to use #Scrapy, which is apparently now an aggressively asynchronous crawler ecosystem that seems hostile to my goal of visiting a set sequence of pages, one after the other.
I'm not writing a search engine here, I don't need this to be massively parallel, I don't care about your Cloud Service, I literally want you to just log in at page A and then use that session to visit page B, and then go down a list of links on that page one by one and save them to my disk, but apparently that's too blase these days.
Ironically, the last time I did this using Node and it was way less hassle. Guess I'll dust off that project and use that instead.

Cécile Le Chevalier · @CLC
194 followers · 1175 posts · Server framapiaf.org#Python How to scrape websites in 5 minutes with #Scrapy ?
http://blog.theodo.fr/2018/02/scrape-websites-5-minutes-scrapy/?