
Giulio · @giuliohome
19 followers · 345 posts · Server mastodon.world
On top of #tokens and #embeddings, are #transformers and #selfattention the secrets behind #chatgpt? interesting that they are simple low level parallelism primitives independent from compilers and pipeline models
#transformers #selfattention #chatgpt #tokens #embeddings

Lynd Bacon · @lyndbacon
1 followers · 6 posts · Server masto.aiMaybe "attention" as used in common transformer models isn't all you need, or or need at all. Microsoft researchers describe "focal modulation networks" that aid interpretation of image processing:
#transformer #computervision #selfattention

DavΞ MacDonald (admin) · @dave
383 followers · 38 posts · Server mastodon.solar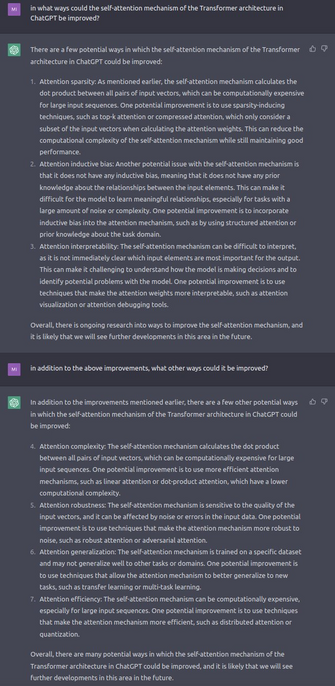
{kind=link}
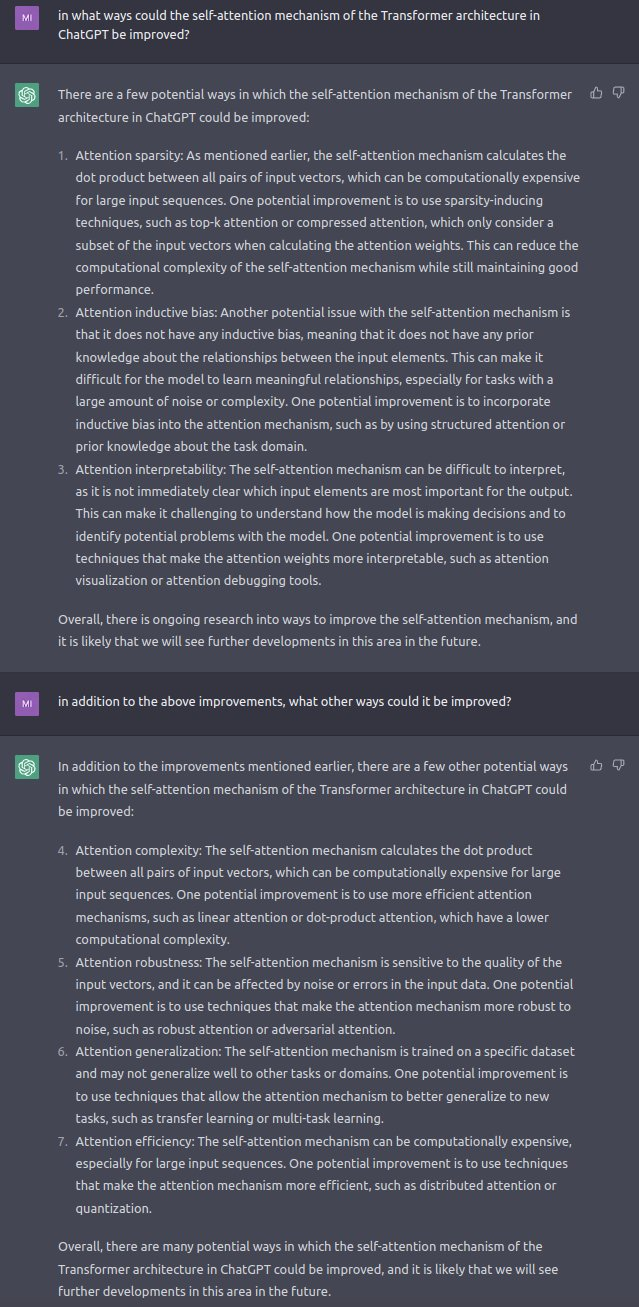
#ChatGPT: in what ways can you improve your own #neuralnet #architecture ?
#chatgpt #neuralnet #architecture #gpt3 #openai #ai #transformer #selfattention