
OL Plus · @OL_Plus
102 followers · 5871 posts · Server mas.to
Ernest #Nuamah, des stats qui parlent
#Stata
(O&L : https://olplus.fr/LeIx6)

Nathaniel D. Porter · @ndporter
575 followers · 418 posts · Server sciences.social
Klaus Pforr · @klauspforr
901 followers · 1273 posts · Server sciences.socialCalling #chatgpt from inside of #Stata https://blog.stata.com/2023/07/25/a-stata-command-to-run-chatgpt/ @stata

Erik Reinbergs · @ereinbergs
215 followers · 281 posts · Server fediscience.orgWhat are y’all’s favorite academic/research related newsletters or blogs?
#education #academia #stats #psychology #research #rstats #stata
#stata #rstats #research #psychology #stats #academia #education
Erik Reinbergs · @ereinbergs
213 followers · 275 posts · Server fediscience.orgGov dataset documentation sometimes says that estimates with relative standard errors greater than 30% are unreliable and/or supressed. I'm trying to understand: Does that mean that they're judging the confidence interval to be so wide that it's not meaningful? Clearly that would depend on what's being measured and the use case no?
#epi #stata #rstats #stats #statistics

Sascha Wolfer · @sascha_wolfer
448 followers · 319 posts · Server fediscience.org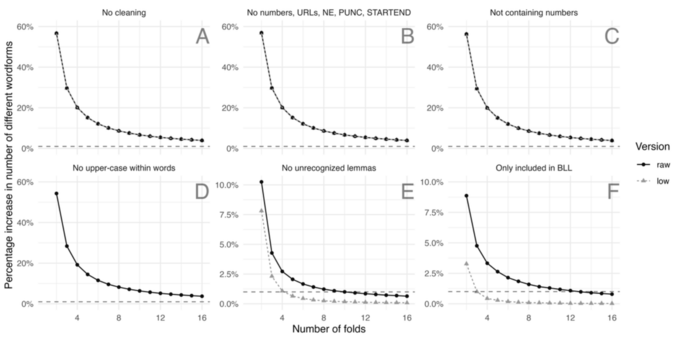
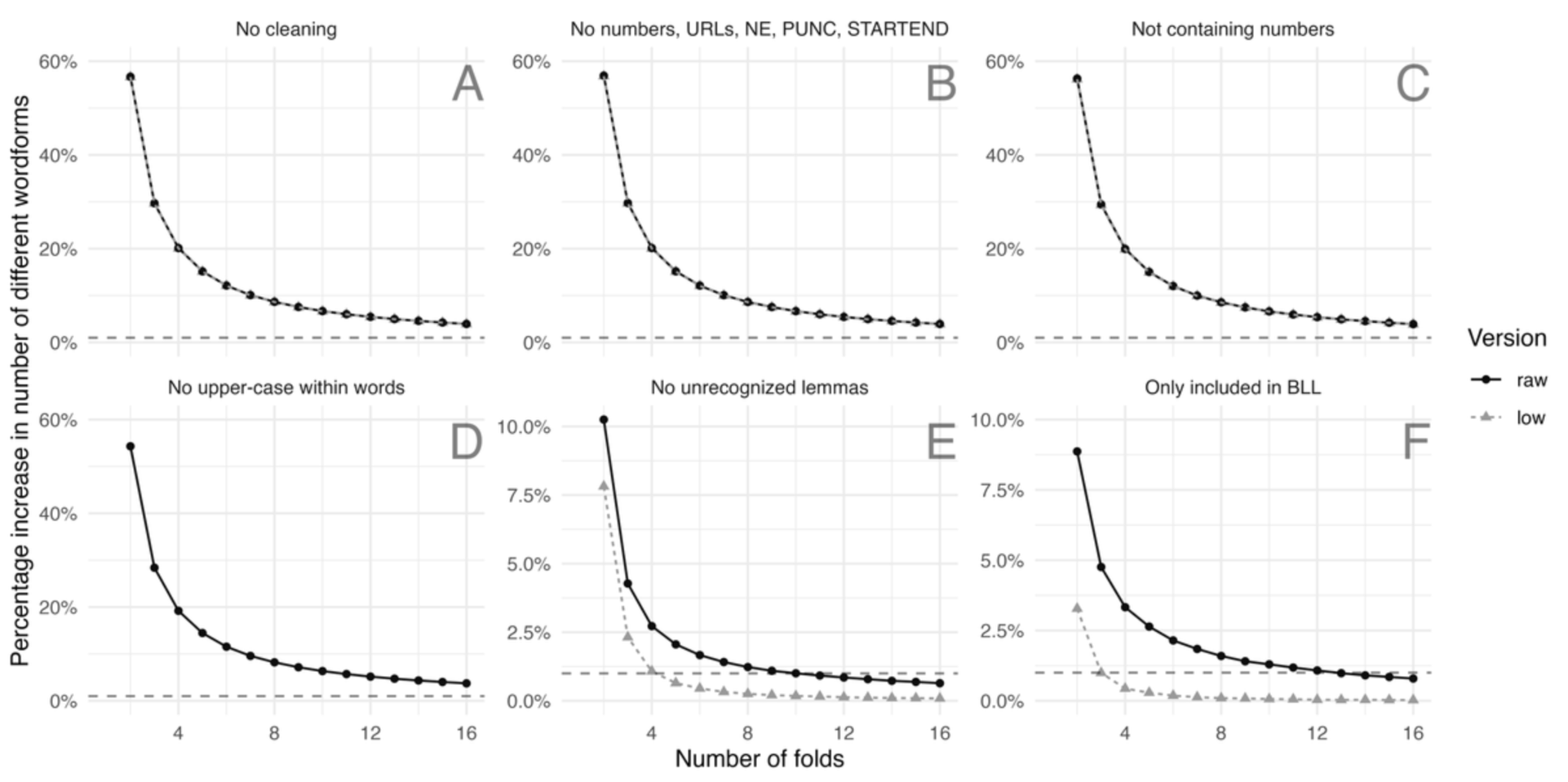
New preprint: We present a new #dataset on the #German #language: DeReKoGram includes uni-, bi-, and trigram frequencies, lemma and POS information for a corpus of around 43 billion tokens.
We evaluate the distribution over the 16 datasets and present a (small) case study on #vocabulary growth.
At https://www.owid.de/plus/derekogram, we provide #Python, #Rstats and #Stata code that should help you getting started with the dataset.
Preprint available at https://doi.org/10.21203/rs.3.rs-3139640/v1.
#linguistics #stata #rstats #python #vocabulary #language #german #DataSet
Klaus Pforr · @klauspforr
887 followers · 1154 posts · Server sciences.socialInterested in #eusilc?
#SPSS, #Stata, and #Rstats routines to transform the raw data of EU-SILC into system files are now available for the most recent EU-SILC release 2023-release1: https://www.gesis.org/en/missy/materials/EU-SILC/setups
@officialmicrodata @gesis_gml @GESIS #eurostat
#eusilc #spss #stata #rstats #Eurostat

Elizabeth Wrigley-Field · @wrigleyfield
2006 followers · 1076 posts · Server fediscience.org@Enema_Cowboy Yup! I teach a #Stata debugging workshop and part of it is about how to clearly explain the problem to someone else. Most times I think that resolves it! (For me, too)
Elizabeth Wrigley-Field · @wrigleyfield
2000 followers · 1071 posts · Server fediscience.orgMeetings with student collaborators where you pull up their code and check & debug it together take a lot of time, but they are uniquely satisfying. These are problems that can be solved within the span of a meeting! The student has wrestled with this and failed, and you are the fresh eyes they need! Something will be accomplished!
I'm an inveterate reader of advice columns, always have been, & I think this scratches the same itch: it is really fun to try to solve someone else's problem

Peter McMahan · @peter_mcmahan
347 followers · 568 posts · Server mas.to@b0rk Fun fact: Stata (extremely popular statistics software in the social sciences) defaults to 16- or 32-bit integers, spilling over to 32-bit _floats_ if your data gets out of the range supported by int32. This is so wild to me. It supports 64-bit ints and floats but explicitly makes them difficult to access.
#stata
Klaus Pforr · @klauspforr
854 followers · 958 posts · Server sciences.social#Stata package for sending emails from Stata with Powershell. Having used Stata for the craziest things, this is exactly down my lane https://docs.iza.org/dp16163.pdf

Jack Iwashyna 🫁 · @iwashyna
935 followers · 1743 posts · Server critcare.social
Nathaniel D. Porter · @ndporter
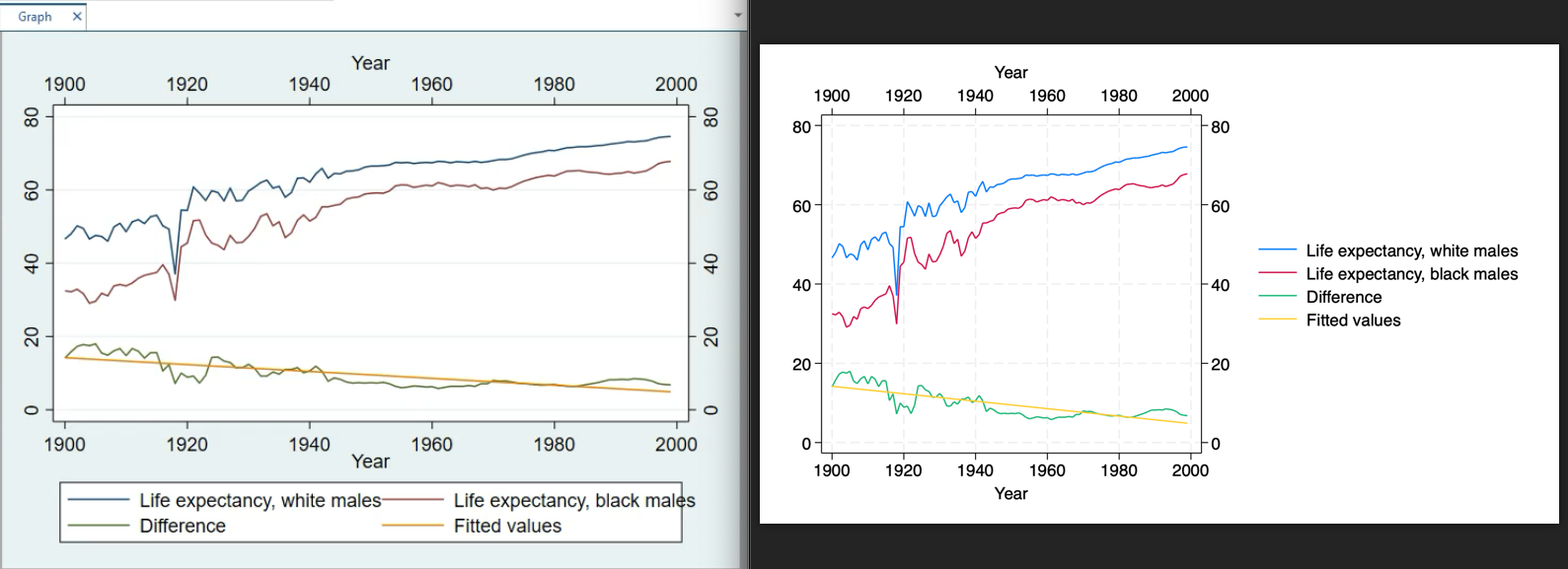
447 followers · 340 posts · Server sciences.social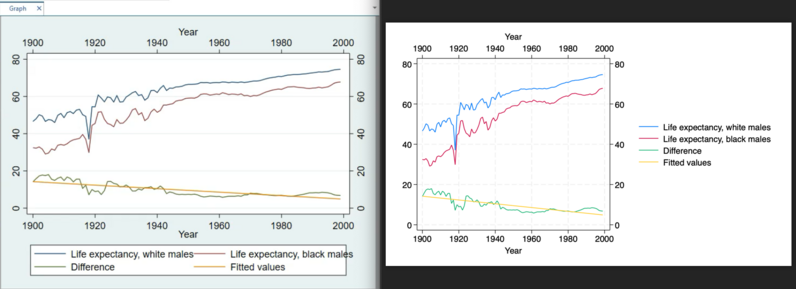
You can really see the difference in aesthetics and #accessibility in a side-by-side of the same line chart in #Stata 17 (left) and 18 (right). Beyond cleaning up the grey background and dramatically improving the legend, the first 2 lines now have colors that I can easily tell apart despite my color impairment.
Nathaniel D. Porter · @ndporter
446 followers · 337 posts · Server sciences.socialI appreciate all the analytic upgrades in #stata 18, but as someone with color vision impairment who could barely differentiate the first two default graph colors, I'm most excited about improvements to the color palette. #disability #data

Erik Reinbergs, PhD · @ereinbergs
184 followers · 141 posts · Server fediscience.org
FReDA Panel Study · @FReDA
82 followers · 41 posts · Server sciences.social
Peter McMahan · @peter_mcmahan
332 followers · 456 posts · Server mas.toI've stumbled into reproducing a published analysis originally done in #Stata. As I'm diving (again) into the syntax, it strikes me just how error prone .do files are. Data wrangling seems to necessarily involve so much copy-paste and hand coding. There are options to commands that aren't in the standard documentation. You can abbreviate command names…up to a point.
I know #RStats syntax has its issues, and I'm trying not to mistake unfamiliarity for inherent problems. But whew this is a lot.

agrogan · @agrogan
3 followers · 4 posts · Server fosstodon.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I have written a book draft of an introduction to #multilevel modeling, entitled #Multilevel Thinking: https://agrogan1.github.io/multilevel-thinking/. Comments, questions and corrections are appreciated, as are suggestions for a possible publisher.
While applicable to many different software programs, the book is currently centered around the use of #Stata, but I hope to extend it to use of #rstats (#lme4) and #julialang
#Multilevel #stata #rstats #lme4 #julialang
agrogan · @agrogan
3 followers · 3 posts · Server fosstodon.orgI have built a tutorial on implementing multilevel models in #Stata, #rstats and #julialang: https://agrogan1.github.io/multilevel-multilingual/multilevel-multilingual.html .

datamaps :rickwhoah: · @datamaps
374 followers · 630 posts · Server social.linux.pizza@kaiarzheimer
those are books about econometric methods not about #stata, the mass would have been certainly the same with #rstats as support language, The book I used for inctroductory econometrics 30+ years ago was 600 pages with no mention of programming. if you cared about looking at least at the TOC, you could have seen there are quite a lot of things going on therein that completely justifies that number