
Annika Rockenberger (she/they) · @arockenberger
257 followers · 312 posts · Server fedihum.org🧵 3/ #ResearchSupportPartnershipUiO continues after lunch w/ my "adopted" colleagues from the #History section. I had a coordinating & getting-to-know meeting to set up some presentations and show-and-tell sessions for the Depts. #DigitalMeetup that happens every #Tuesday. I offered to do short sessions on #TaDiRAH, #Transkribus, #Tropy and #Tesseract during the fall. I'll use the 1678 #Danish translation of the #EthicaComplementoria as an example for #AutomatedTextRecognition of C17th books!
#researchsupportpartnershipuio #history #digitalmeetup #tuesday #TaDiRAH #Transkribus #tropy #tesseract #danish #ethicacomplementoria #automatedtextrecognition

Andrew Wedlake · @adventure_tense
42 followers · 230 posts · Server mapstodon.spaceIf you're doing research that requires a large collection of (historical) maps or photos, old articles, etc, nothing is like #tropy. It gets more useful the more data you build into it. And the database is always under our control (including a backup plan). Zooming into and panning documents is silky smooth.
Andrew Wedlake · @adventure_tense
42 followers · 230 posts · Server mapstodon.space
I got #Tropy installed on LinuxMint. Back to working on my projects as normal.
Tropy 1.13.1 for linux seems to have a crash bug when importing several files into the database. It can be worked around by limiting number of files to import. I posted my crash log on #github. Seems that the Tropy team is aware of issue and working on it.
This is why I love open source. Our relationship is different. The software won't improve as fast, unless we report our bugs and explain how to duplicate them. 🙂

Florian Ledermann · @floledermann
199 followers · 154 posts · Server mapstodon.spaceNice to see screenshots of #Shadowmap https://shadowmap.org/ and #Tropy https://tropy.org/ making the rounds here – the former started as a Master's thesis supervised by me, the latter has two friends of mine as dev and UI leads. 🤗
Good to see friends' projects thrive!
#shadowmap #tropy #opensource #FreeSoftware #startups
Annika Rockenberger (she/they) · @arockenberger
194 followers · 131 posts · Server fedihum.org

UjuBib · @UjuBib
369 followers · 4964 posts · Server mamot.fr#Tropy j'avais pas insisté mais c'est une mise à jour majeure (sur la manière de partager les projets notamment). Les nouveaux projets, par défauts, copient les photos dans le dossier du projet (attention aux doublons).
cc @DamienPetermann
---
RT @UjuBib
New Project Types in Tropy 1.13 | Tropy https://tropy.org/blog/new-project-types-in-tropy-1-13
https://twitter.com/UjuBib/status/1643178811826003968

Robert Petersen :ve: · @Sonikku
444 followers · 3674 posts · Server techhub.socialFinally. Police station escaped.
#ps5share #residentevil2 #tropy #playstation #gaming

Natalie · @natalie
698 followers · 50 posts · Server hcommons.socialHow to Analyse Soninke Ajami Manuscripts: A workflow for the analysis of Soninke Ajami manuscripts using the open-source software #Tropy
Andrew Wedlake · @adventure_tense
29 followers · 134 posts · Server mapstodon.space
Andrew Wedlake · @adventure_tense
28 followers · 123 posts · Server mapstodon.space
From Simon’s post, I really dug into #Tropy this weekend. It’s functionality is perfect for my research projects. UX is fluid, easy to add data and tags, and it’s easy to zoom around large maps. I attached a few screenshots from my progress. Very suitable for tracking large collections.
Special thanks to Simon Polster for his post.
From: @cartisan
https://mapstodon.space/@cartisan/109913395068416883

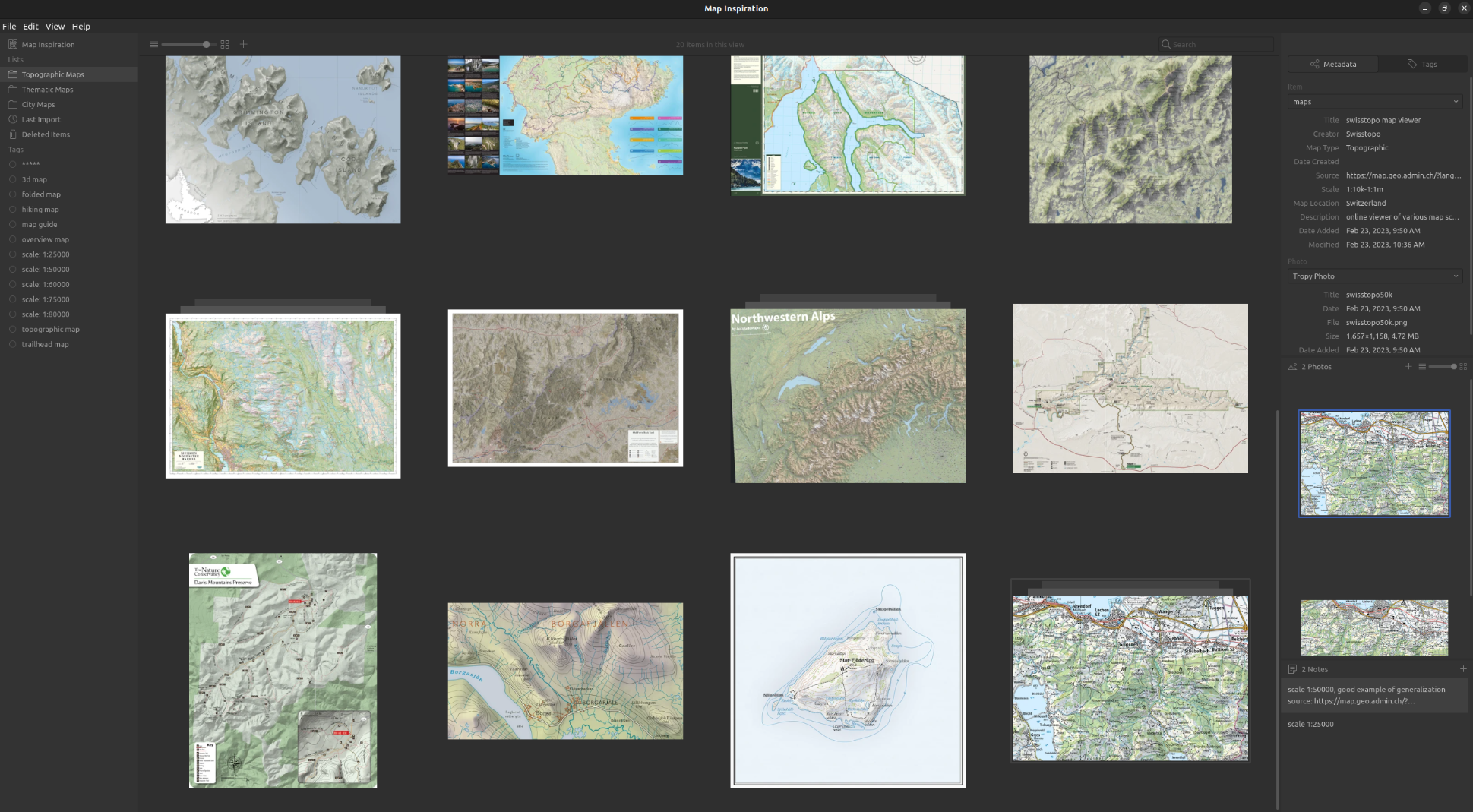
Simon Polster · @cartisan
42 followers · 45 posts · Server mapstodon.space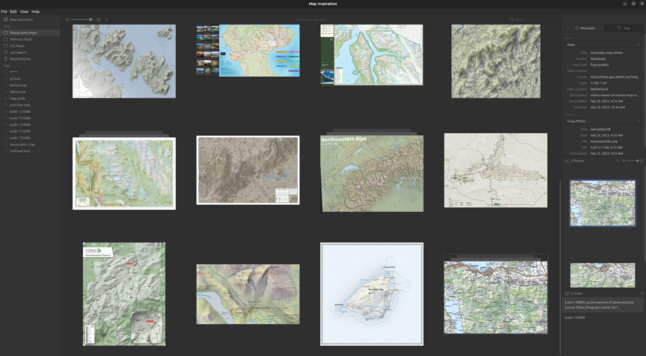
I just started using the #opensource app #tropy to manage my "map inspiration" collection. It is exactly what I've been looking for! #gischat

Mike Dickison · @Adzebill
634 followers · 159 posts · Server ausglam.spaceWow, #Tropy looks great as an open-source tool for organising a collection of research photographs. https://tropy.org/

Douglas McRae · @dvmcrae
356 followers · 26 posts · Server mastodon.online
Are you interested in learning more about #Tropy? The Tropy team has two dedicated outreach postdocs who frequently hold virtual and in-person demonstration sessions and workshops.
In the upcoming week we will lead sessions at Universidad Católica Andres Bello (Caracas, Venezuela--see attached image), Arquivo Público Estadual de São Paulo (Brazil) and the Univrsidade Federal de Sergipe (also Brazil).
Contact us if you'd like to set up a Tropy session at your institution!
Natalie · @natalie
491 followers · 175 posts · Server hcommons.socialExtrem interessanter Vortrag von Dominique Stutzmann (IRHT/CNRS) über die Analyse mittelalterlicher Schriftquellen mit digitalen Methoden am Beispiel von Stundenbüchern und Urkundenregistern.
Videomitschnitt: https://youtu.be/ZZdiOI4g_Zc
Zusammenfassender Blogbeitrag: https://dhistory.hypotheses.org/2574
Für mich gerade am spannendsten: Die Entdeckung von #Arkindex, was gerade für gescannte Texte besonders gut zu funktionieren scheint. Werde es mit #Tropy vergleichen ...
#Arkindex #tropy #digitalhistory #digitalhumanities

Till Grallert · @tillgrallert
294 followers · 174 posts · Server digitalcourage.social@whanley @philippsteinkrueger @natalie @stefandumont Great question and I reckon there are a myriad of ways to approach this problem. For me, the answer depends on a) the length of the manuscript in question and b) @natalie skill set. Training HTR for a single, short-ish manuscript is probably not worth the effort, as you don't want / need the full text. You could annotate regions within the images with the open-source #Tropy app (https://tropy.org/). Tropy provides various means for exporting structured data, one of which is JSON-LD. This could then be used for the actual co-occurrence / network analysis in #Python or #R.
UjuBib · @UjuBib
347 followers · 4503 posts · Server mamot.fr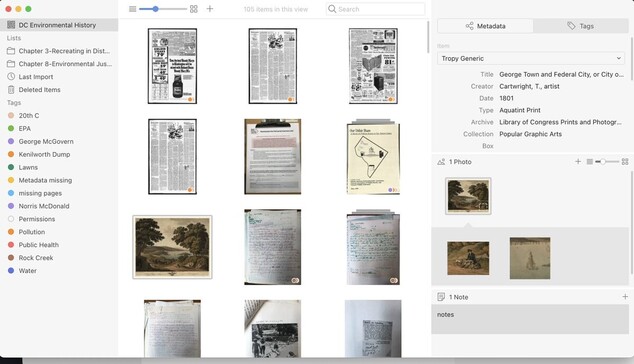
RT @tropy
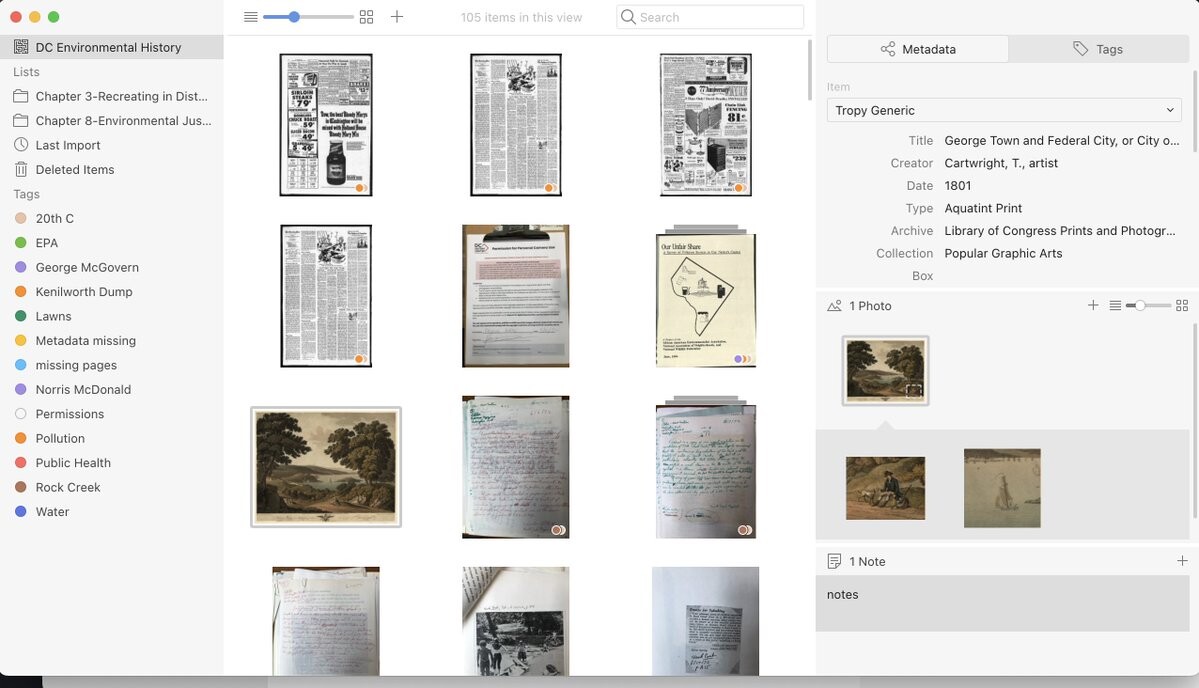
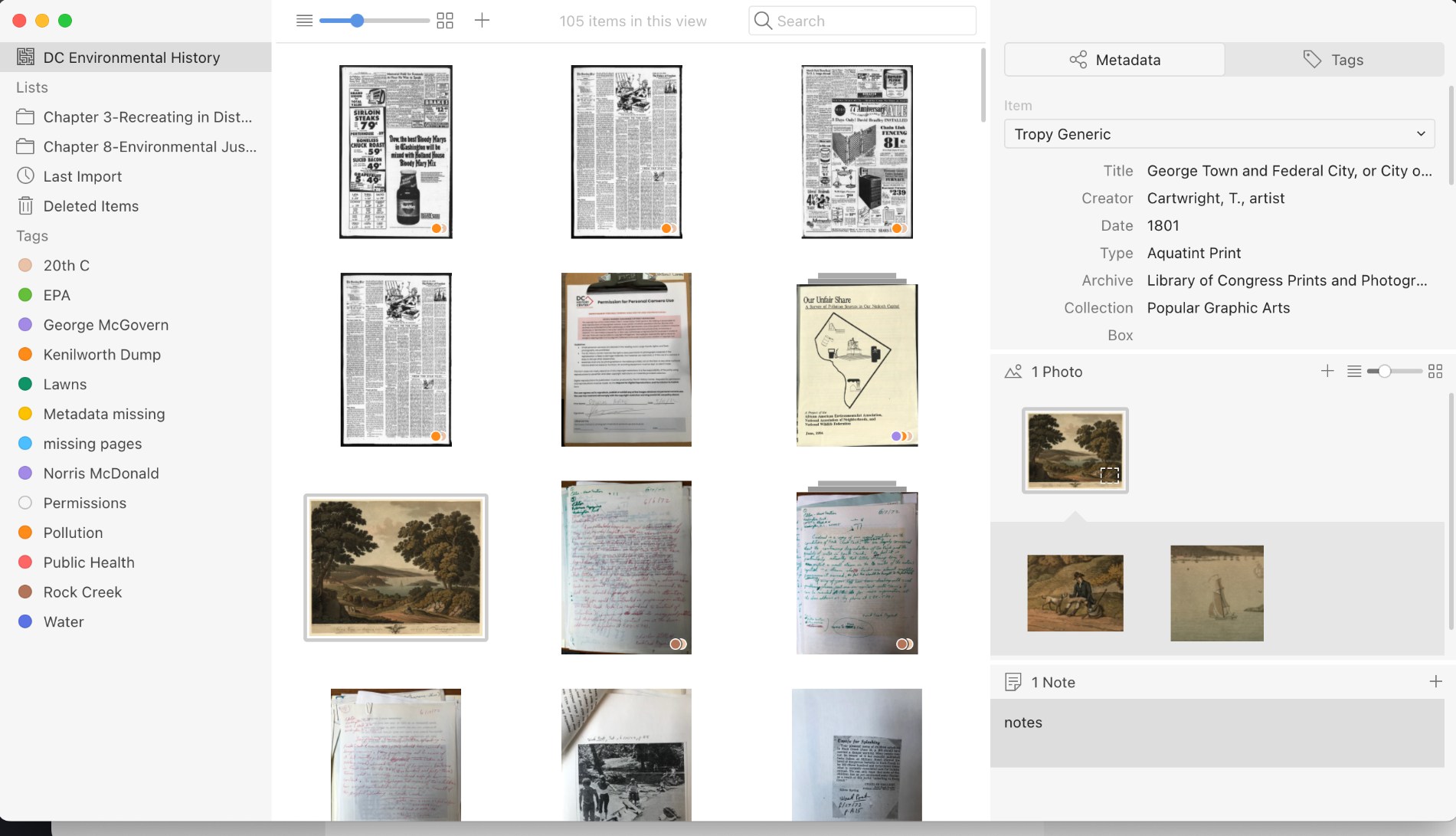
#tropy users...did you first start using Tropy at the beginning of a new project, or did you first adopt it during a project in progress?
What was your experience switching from your previous workflow to Tropy?

Sarah · @wynkenhimself
625 followers · 319 posts · Server glammr.usIf you do research (or have fun with!) large collections of images, whether of your own taking or institutionally provided ones, #Tropy is a life saver and I cannot recommend it highly enough. I've been using it since early days and am delighted with it https://tropy.org/
Douglas McRae · @dvmcrae
331 followers · 17 posts · Server mastodon.online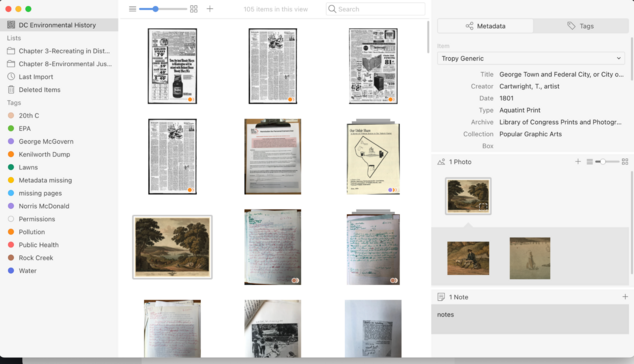
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#tropy users...did you first start using Tropy at the beginning of a new project, or did you first adopt it during a project in progress? What was your experience switching from your previous workflow to Tropy?
I'm trying to find out more about our users, but also want to keep the conversation rolling about how Tropy can help researchers with their projects.
(If you've never heard of Tropy, check out tropy.org)
#histodons
#digitalhumanities
#research
#dissertation
#thesis
#archives
#archives #thesis #dissertation #research #digitalhumanities #histodons #tropy
UjuBib · @UjuBib
278 followers · 4296 posts · Server mamot.frCorporation for Digital Scholarship [#Omeka, #Zotero, #Tropy...] https://digitalscholar.org/
UjuBib · @UjuBib
347 followers · 4503 posts · Server mamot.frCorporation for Digital Scholarship [#Omeka, #Zotero, #Tropy...] https://digitalscholar.org/