
Fabrice Tshimanga · @fab13
36 followers · 224 posts · Server sigmoid.socialSome stream of thoughts wrt ConvNets and ViTs.
The paper "Patches Are All You Need?" contends that patchification has a special place into why ViTs are so effective, while others have said it's the expressiveness of the attention mechanism, or the expressiveness of multiplicative interactions, or the fact that many operations are data dependent (like, in a spectrum with weights-dependent on the other end) 1/n
#deeplearning #vit #attention #cnn
#deeplearning #vit #attention #cnn

Hue · @hue
59 followers · 131 posts · Server sigmoid.socialThe #ViT journey:
Vision transformers were easier than I expected. I planned to spend three weeks learning them, but I'm already done :ablobcatrave: .
Hue · @hue
59 followers · 130 posts · Server sigmoid.social
Hue · @hue
58 followers · 128 posts · Server sigmoid.social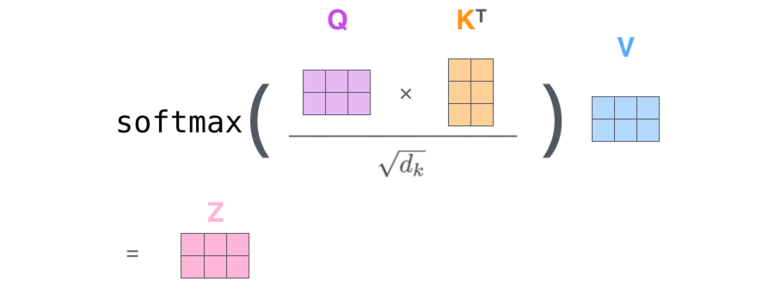
The #ViT journey:
Let's visit Jay Alammar's blog once again and check out his amazing Illustrated #Transformer post. Even if you're already familiar with transformers, it's definitely worth taking a look: https://jalammar.github.io/illustrated-transformer/
Hue · @hue
58 followers · 126 posts · Server sigmoid.socialThe #ViT journey:
I need to spend some time studying the multi-head self-attention mechanism. I'm going to start with this fantastic blog post by Jay Alammar: 'Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)'.
Check it out here: https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
Hue · @hue
58 followers · 124 posts · Server sigmoid.socialThe #ViT journey:
This is one of the best step-by-step paper implementation tutorials I've ever encountered. The video version on Udemy, which is over eight hours long :ablobwhee: , was also a real treat to watch. If you want to learn how to replicate Vision Transformers in PyTorch, I highly recommend it:
Hue · @hue
57 followers · 111 posts · Server sigmoid.socialThe #ViT journey:
"The key contributions from [AN IMAGE IS WORTH 16X16 WORDS] paper were not in terms of a new architecture, but rather the application of an existing architecture (Transformers), to the field of Computer Vision. It is the training method and the dataset used to pretrain the network, that were key for ViT to get excellent results compared to SOTA (State of the Art) on ImageNet."
https://amaarora.github.io/2021/01/18/ViT.html
So I have to take a step back and learn about #Transformers :woohoo:
Hue · @hue
56 followers · 110 posts · Server sigmoid.socialI'll spend the next three weeks fully dedicated to learning about Vision Transformers and implementing the #ViT paper in PyTorch from scratch. Let's hope that this will be sufficient time to complete the task! :thisisfine:

Ross Wightman · @rwightman
283 followers · 22 posts · Server sigmoid.social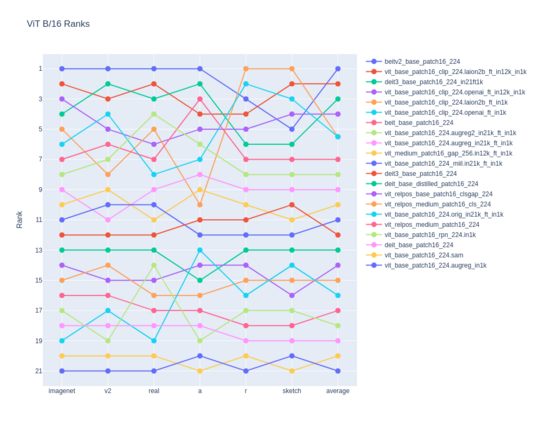
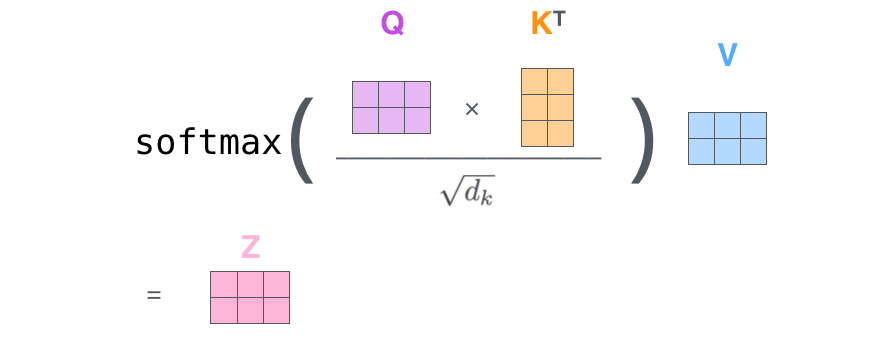{kind=link}
{kind=link}
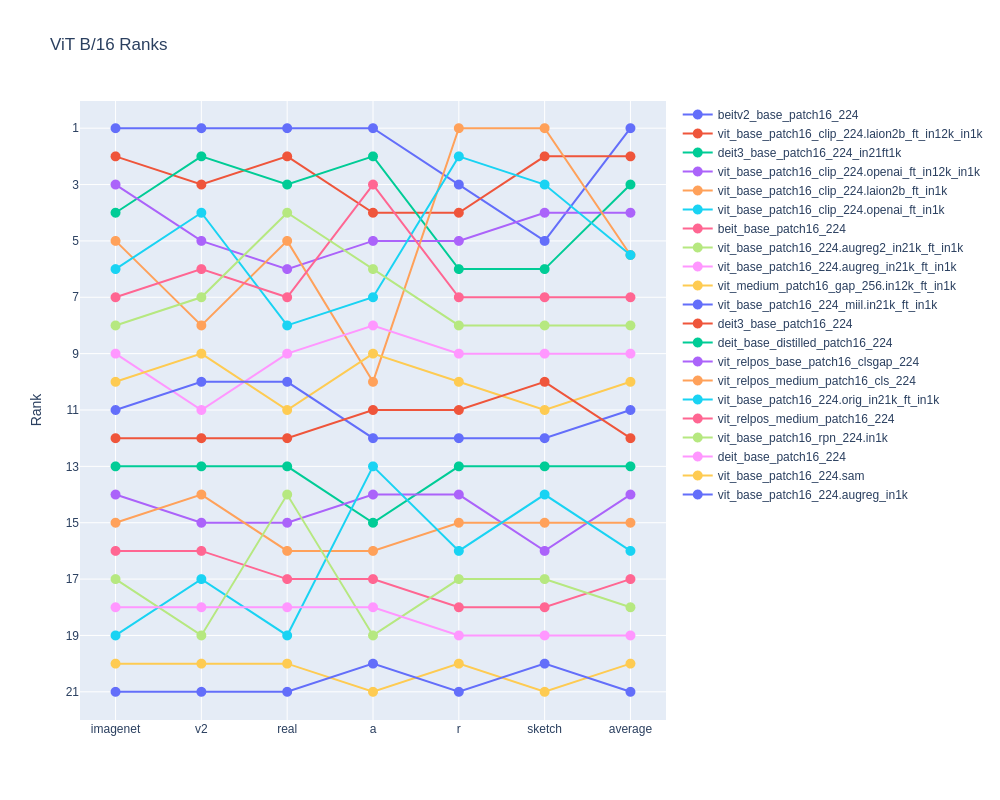
Which B/16 reigns supreme? I've recently fine-tuned quite a few new ViT models and wanted to compare them. With new multi-weight support on the way I realized timm will soon have ~20 different B/16 (or close to). B/16 is the most common ViT model and easiest to compare across wide range of pretrain datasets and methods. In the lead is BEiT v2, but hot on its heals are fine-tuned LAION2B and OpenAI CLIP image towers. Check out a notebook at https://colab.research.google.com/drive/12u1csH7_Uun78lGti35zvi5-S6FX4ZKu?usp=sharing #CV #machinelearning #vit #AI

Patrikai.com · @patrikaidotcom
106 followers · 62737 posts · Server masthead.socialமாணவர்கள் கண்டுபிடித்த ரோபோ மூலம் ஆயுத பூஜை கொண்டாடிய விஐடி – வீடியோ
https://patrikai.com/vit-celebrates-ayudha-puja-with-student-invention-robot-video/ via @patrikaidotcom@twitter.com
#VIT #Robotics #robots #AyudhaPooja2022 #AyudhaPuja #AUTOMATION #AutomateUpdates #ViralVideo @VIT_univ@twitter.com @GraVITas_VIT@twitter.com
#ViralVideo #AutomateUpdates #automation #AyudhaPuja #AyudhaPooja2022 #robots #robotics #vit
Patrikai.com · @patrikaidotcom
106 followers · 62737 posts · Server masthead.socialவண்டலூர் விஐடி பல்கலைக்கழகத்தில் மேலும் 45 பேருக்கு கொரோனா உறுதி… https://patrikai.com/corona-confirms-45-more-students-at-vandalur-vit-university/ via @patrikaidotcom@twitter.com
#COVID #COVID19 #university #vit #vandalur

erAck · @erAck
218 followers · 5335 posts · Server social.tchncs.deBy urgency as a calculation of importance, impact, benefit, dependencies, due date and age.
I use #Taskwarrior
https://taskwarrior.org/
A command line task manager.
Recommendable Vim-alike frontend: #vit
https://github.com/scottkosty/vit
Loads of other tools available
https://taskwarrior.org/tools/
Along with #Timewarrior to track time spent.
https://timewarrior.net/
#taskwarrior #vit #timewarrior