
PyCon CZ :python: 🇨🇿 · @pyconcz
38 followers · 18 posts · Server floss.social
Víš, že ti Python může pomoct stahovat si automaticky z internetu vybraná data? 🌐 Přijď na workshop (nejen pro začátečníky) Šárky Melicharové "Úvod do světa scrapingu: polévky, pavouci, API" 🕷️🐍
https://cz.pycon.org/2023/program/workshops/27/
#Python #WebScraping #Workshop
#Python #webscraping #workshop

MathDaTech :fedora: 🤘 · @mathdatech1
376 followers · 638 posts · Server hostux.socialWebScraping in Bash | Muhammad
In this blog post, we’ll delve into a Bash script that extracts links and titles from a webpage and stores them in a CSV file.

Pete · @forpeterssake
287 followers · 2071 posts · Server mastodon.xyz
"LinkedIn and Facebook, most notably, have done as much as anyone to shape the law of web scraping. ...
But make no mistake, these companies view this data, generated by their users on their platforms, as their property. This is true even though the law does not recognize that they have a property interest in it, and even though they expressly disclaim any property rights in that data in their terms of use."

꧁~Cea~꧂ · @alcea
44 followers · 3258 posts · Server pb.todon.deWell.I got #DiDom running by being a #stubborn idjiot
https://codepen.io/ryedai1/full/jOXPoPy
Ohwell..
But it can do what #simplehtmldom already can.
Yay ?
No #advanced #webscraping for me ...
#didom #stubborn #simplehtmldom #advanced #webscraping #codealcea #brokencodealcea

꧁~LilyCea~꧂ · @alcea
45 followers · 3156 posts · Server pb.todon.deOh and ""#webscraping"" ?
Ha ha.. Ha.
#Let s use a #headless #browser because, #this * !
#Puppeteer #Playwright #CasperJS
Have fun with #serverside #NodeJS or #PHP (which will require #root access wee)
Wtf.
#webscraping #let #headless #browser #this #puppeteer #playwright #casperjs #serverside #nodejs #php #root

Mr.Trunk · @mrtrunk
7 followers · 15221 posts · Server dromedary.seedoubleyou.meHackRead: Overcoming web scraping blocks: Best practices and considerations https://www.hackread.com/web-scraping-blocks-practices-considerations/ #DataScraping #WebScraping #Technology #javascript #Scraping #Python #HowTo
#datascraping #webscraping #technology #javascript #scraping #python #howto
Mr.Trunk · @mrtrunk
7 followers · 15119 posts · Server dromedary.seedoubleyou.meHackRead: Overcoming web scraping blocks: Best practices and considerations https://www.hackread.com/web-scraping-blocks-practices-considerations/ #DataScraping #WebScraping #Technology #javascript #Scraping #Python #HowTo
#datascraping #webscraping #technology #javascript #scraping #python #howto

Sharon Machlis · @smach
2313 followers · 271 posts · Server masto.machlis.com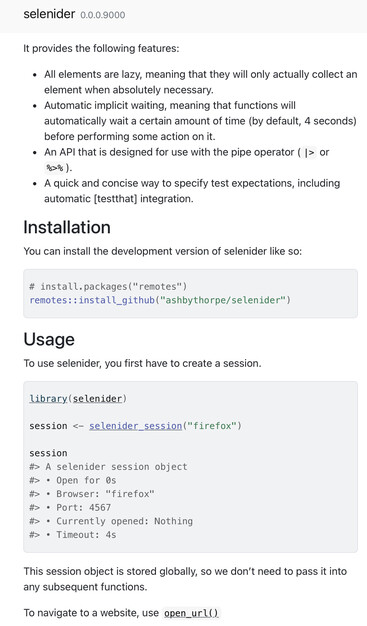
The {selenider} #rstats 📦 “aims to make web testing and scraping much simpler. It is inspired by Java’s Selenide and Python’s Selene. It provides a simple and consistent interface to both {chromote} and {RSelenium}.” By Ashby Thorpe, on GitHub.
https://ashbythorpe.github.io/selenider/
(I haven’t tried this yet but it's on the to-do list!)
#rstats #webscraping #selenium

Miguel Afonso Caetano · @remixtures
686 followers · 2688 posts · Server tldr.nettime.org
#AI #GenerativeAI #WebScraping #DataMining #Privacy #DataProtection: "What kind of info are we comfortable forking over to the AIs, if any? Right now we are in the midst of a destabilizing moment. It’s alarming, yes, but it’s also an opportunity to renegotiate what we do and do not want to hand over to tech giants that have been gathering our personal data for decades now. But to make those sorts of decisions, first we have to know where we stand. What are the websites and apps we use every day doing with our data? Are they using it to train their AI systems? What can we do about it if so?
A good rule of thumb, to begin with: If you are posting pictures or words to a public-facing platform or website, chances are that information is going to be scraped by a system crawling the internet gathering data for AI companies, and very likely used to train an AI model of one kind or another. If it hasn’t already."
#ai #generativeAI #webscraping #datamining #privacy #dataprotection

guites · @guites
31 followers · 190 posts · Server bolha.usWeb scrapers of the world
Unite and take over
Web scrapers of the world
Hand it over
Hand it over
Hand it over

wraptile · @wraptile
148 followers · 480 posts · Server fosstodon.orgExploring #webScraping capabilities with #chatGPT and the new Code Interpreter feature is a real game changer!
Now you can upload an HTML file and with code interpreter chatGPT can generate accurate parsing instructions through self correction.
It basically keeps guessing but with code interpreter it can confirm it's guesses until it's satisfied. This is a game changing feature for this particular niche!
I wrote a short blog here: https://scrapfly.io/blog/parsing-html-with-chatgpt-code-interpreter/

raimoncoding · @raimoncoding
31 followers · 81 posts · Server techhub.social🌐 Explored webscraping today, encountering both successful and challenging projects. Struggling with classes and XPath in my code, but determined to overcome! 💪 #webscraping #webdevelopment #codingstruggles
#webscraping #webdevelopment #codingstruggles
Miguel Afonso Caetano · @remixtures
566 followers · 2245 posts · Server tldr.nettime.org#AI #GenerativeAI #WebScraping #DataScraping #OpenAI #Copyright: "Data scraping practices in the name of training AI have come under attack over the past week on several fronts. OpenAI was hit with two lawsuits. One, filed in federal court in San Francisco, alleges that OpenAI unlawfully copied book text by not getting consent from copyright holders or offering them credit and compensation. The other claims OpenAI’s ChatGPT and DALL·E collect people’s personal data from across the internet in violation of privacy laws.
Twitter also made news around data scraping, but this time it sought to protect its data by limiting access to it. In an effort to curb the effects of AI data scraping, Twitter temporarily prevented individuals who were not logged in from viewing tweets on the social media platform and also set rate limits for how many tweets can be viewed."
https://venturebeat.com/ai/generative-ai-secret-sauce-data-scraping-under-attack/
#ai #generativeAI #webscraping #datascraping #openai #copyright

Digitalcourage-Admins · @freiheit
1603 followers · 563 posts · Server digitalcourage.socialAngenommen, wir haben die Sperre eingerichtet und du nicht, dann sollte Meta/Threads unsere Tröts auch dann nicht geliefert bekommen, wenn du sie boostest.
Bei Posts mit öffentlicher Sichtbarkeit ist es natürlich immer möglich, dass irgendwer die öffentlichen Websites der Instanzen abgrast (#webscraping). Das ist so, weil Mastodon eine Publikationssoftware ist und kein Messenger.
Miguel Afonso Caetano · @remixtures
547 followers · 2201 posts · Server tldr.nettime.org
#Google #BigTech #AI #GenerativeAI #WebScraping #Search: "Google updated its privacy policy over the weekend, explicitly saying the company reserves the right to scrape just about everything you post online to build its AI tools. If Google can read your words, assume they belong to the company now, and expect that they’re nesting somewhere in the bowels of a chatbot.
“Google uses information to improve our services and to develop new products, features and technologies that benefit our users and the public,” the new Google policy says. “For example, we use publicly available information to help train Google’s AI models and build products and features like Google Translate, Bard, and Cloud AI capabilities.”
Fortunately for history fans, Google maintains a history of changes to its terms of service. The new language amends an existing policy, spelling out new ways your online musings might be used for the tech giant’s AI tools work."
https://gizmodo.com/google-says-itll-scrape-everything-you-post-online-for-1850601486
#google #bigtech #ai #generativeAI #webscraping #search

Nathaniel D. Porter · @ndporter
486 followers · 392 posts · Server sciences.socialThe irony is not lost on me that Musk felt he had to cripple a core feature of Twitter (reading tweets) because he locked down the API where people could collect data without breaking Twitter so now people are using bots to scrape that data, which put much more stress on the servers. #bigdata #webscraping
Miguel Afonso Caetano · @remixtures
523 followers · 2179 posts · Server tldr.nettime.org
#AI #GenerativeAI #OpenAI #WebScraping #Privacy #DataProtection: "As the lawsuit notes, AI companies deploy data scraping technology at a massive scale. The race between every major tech company and a growing pack of startups to develop new AI technologies, experts say, has also accelerated not just the scale of web scraping but the potential harms that come with it. Experts note that while web scraping can have benefits to society, such as business transparency and academic research, it can also come with harms, such as cybersecurity risks and scammers harvesting sensitive information for fraud.
“The volume with which they’re going out across the web and scraping code and scraping data and using that to train their algorithms raises an array of legal issues,” said Lee Tiedrich, distinguished faculty fellow in ethical technology at Duke University. “Certainly, to the extent that privacy and other personally identifiable information are involved, it raises a whole host of privacy issues.”
Those privacy concerns are the centerpiece of the recent California lawsuit, which accuses OpenAI of scraping the web to steal “private information, including personally identifiable information, from hundreds of millions of internet users, including children of all ages, without their informed consent or knowledge.”"
https://cyberscoop.com/openai-lawsuit-privacy-data-scraping/
#ai #generativeAI #openai #webscraping #privacy #dataprotection

Qiita - 人気の記事 · @qiita
2 followers · 239 posts · Server rss-mstdn.studiofreesia.comPythonでブログのコメント自動収集
https://qiita.com/yaanai/items/36fecf0e6a2752d0534a?utm_campaign=popular_items&utm_medium=feed&utm_source=popular_items
#Python #JavaScript #WebScraping #ぺろりん先生
#python #javascript #webscraping #ぺろりん先生

Laboratório Hacker de Campinas · @lhc
128 followers · 91 posts · Server mastodon.com.brAs inscrições GRATUITAS para o tutorial "Raspando Dados da Internet com Python" com @rennerocha na manhã do sábado 01 de julho já estão abertas!
Mais informações em: https://www.eventbrite.com.br/e/tutorial-raspando-dados-da-internet-com-python-tickets-652188231557
#scrapy #python #webscraping #hackerspaces

WebRobot · @webrobot
0 followers · 2 posts · Server allthingstech.social
{kind=link}
{kind=link}
How Can You Train and Use Custom OpenAI Models for Your Business?
https://www.webrobot.eu/dynamic-pricing-price-inteligence-higher-profit-sales
#openai #gpt #gpt3 #gpt4 #ai #modeltraining #webscraping #bigdata #datamining #machinelearning #profit #ecommerce #webrobot #dynamicpricing
#openai #gpt #gpt3 #gpt4 #ai #modeltraining #webscraping #bigdata #datamining #machinelearning #profit #ecommerce #webrobot #dynamicpricing