Johan van der Knijff · @bitsgalore
376 followers · 645 posts · Server digipres.club

Micky · @mickylindlar
292 followers · 826 posts · Server digipres.club
while PDF is something of a life partner for me, 3D data is something that always excites me .... sorry #wtfpdf ... still love ya.
#4culturebarcamp #digitalpreservationlife #wtfPDF
Johan van der Knijff · @bitsgalore
361 followers · 608 posts · Server digipres.clubIn today's #wtfPDF news - Foxit integrates #ChatGPT into #PDF Editor Cloud, use cases include "have a conversation with PDF and answer user questions based on PDF content"😱:
https://pdfa.org/pdf-editor-cloud-integration-with-chatgpt/
(I sincerely hope I'll never feel the urge to have a conversation with PDF. Sounds like something that would require urgent medical assistance!)
Johan van der Knijff · @bitsgalore
353 followers · 565 posts · Server digipres.club
Johan van der Knijff · @bitsgalore
352 followers · 550 posts · Server digipres.club@mickylindlar Either job security or a sure path to ruin, as the more nightmarish aspects of PDF drive one to drink and illegal substances along the way! #wtfpdf
Micky · @mickylindlar
268 followers · 562 posts · Server digipres.clubheads up #wtfPDF friends around the world! this is not an april fool's!
Adobe, Apryse, Foxit and PDFAssociation have partnered up and made ISO32000-2 2020 (aka PDF2.0), ISO/TS 32001 (Extensions to Hash Algorithm Support in ISO 32000-2) and ISO/TS 32002 (Extensions to
Digital Signatures in ISO 32000-2) available as sponsored papers ... so **FREE**. Follow the links from press release below; no valid email (or address) necessary:

Jon Ippolito · @jonippolito
395 followers · 204 posts · Server digipres.club
Today a friend approached me stymied by trying to copy-paste a number—yep, one single number—out of a PDF.
A collection of PDFs isn't an archive; it's a tomb.
#WTFpdf #libraries #digitalpreservation #collections #archives #digipres
#digipres #archives #collections #digitalpreservation #libraries #wtfPDF
Micky · @mickylindlar
239 followers · 397 posts · Server digipres.club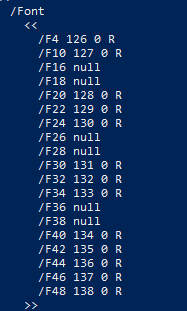
back for some fun with the font-problem #wtfPDF
as we learned ⬆️ the font problem is on page 2 / obj 6. with
pdf-parser -o 6 filename.pdf
we can take a quick look at the content of obj 6.
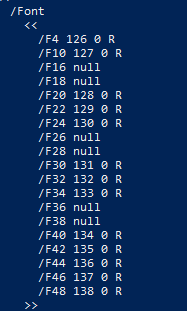
This returns an odd Font dictionary, that lists 4 names (/F16, /F18, /F26, /F28, /F36, /F38) with "null" instead of the expected indirect object.
which makes them a bit hard to find, to put it nicely.
Micky · @mickylindlar
236 followers · 376 posts · Server digipres.club
k, so with a bit of time this morning before meetings, i'll continue to look at the #wtfPDF issue from this 🧵 .
Yesterday I figured out that we have 76 font errors on page 2. Looking at page 2, i can confirm there's an issue .... please see for yourself:
Johan van der Knijff · @bitsgalore
322 followers · 360 posts · Server digipres.club@mickylindlar Yes, that's classic #wtfPDF material! Could it be that those 76 errors all refer to the same font resource? Haven't used Preflight for a while, but I vaguely recall it reports errors on a per-page basis (I might misremember this).
Micky · @mickylindlar
236 followers · 371 posts · Server digipres.clubSo to summarize the story so far .... we've moved from 1 error reported by JHOVE and a different one reported by pdfcpu (and none by qpdf) to 8 font syntax errors with pdffonts and 76 font errors with Adobe Preflight.
The logical summary so far is of course #wtfPDF
I shall continue to dig deeper later on. Now off to meetings for the rest of the afternoon!
Micky · @mickylindlar
203 followers · 274 posts · Server digipres.clubThanks! Will have to deep-dive into the Arlington model checker. In @DidierStevens pdf-parser i so far only found the possiblility to check for a (known and suspected to be orphaned) obj via regular search function.
it seems that while many readers ignore orphaned objects, many validators don't ;-P the question behind it being "if no one cares that it's there, but not really, shoudl validators care"?
Ah, the philosophic mysticism that is #wtfPDF
Micky · @mickylindlar
203 followers · 270 posts · Server digipres.clubToday's example of why reading the PDF spec is so much fun:
"The following objects shall not be stored in an object stream:
* stream objects"
Micky · @mickylindlar
194 followers · 252 posts · Server digipres.club"clean" Polyglots in the wild - examples given by @Ange at #DPCcyber:
- hybrid ISOs (ISO & MBR)
- self-extracting archives (executable+archive)
- hybrid PDF #wtfPDF (PDFs with embedded OpenOffice doc)
Check out ange's MITRA tool for some polyglot generation:
https://github.com/corkami/mitra

Bertrand Caron · @BertrandCaron
159 followers · 103 posts · Server digipres.club
Micky · @mickylindlar
190 followers · 215 posts · Server digipres.club
Micky · @mickylindlar
170 followers · 127 posts · Server digipres.club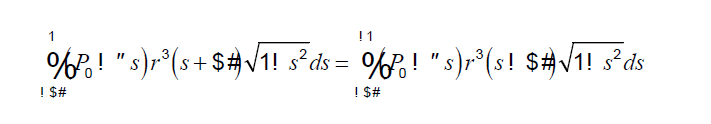
Johan van der Knijff · @bitsgalore
235 followers · 221 posts · Server digipres.club
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
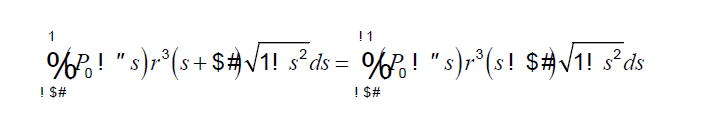{kind=link}
{kind=link}
Classic #wtfPDF moment earlier today on the birdsite, posting here for the attention of @wtfpdf https://twitter.com/bitsgalore/status/1595826793402990595